
Authors
Ludovic Dehon
Ludovic Dehon
Since our public launch, we’ve done a lot of work to give you the best possible experience, something we hope you will come to expect from Kestra. This latest release brings performance improvements to provide a smooth experience with large clusters, as well as some other great features.
Since we already have a large deployment at Leroy Merlin, we have often encountered performance issues, but this one was more complicated to find. Here, we’ll outline some metrics based on our large deployment on Leroy Merlin’s production environment and show you some before and after graphs for the same workload. Leroy Merlin’s usage is mostly processed overnight, with all flows starting simultaneously around 3AM with 4000+ executions and 40,000+ tasks.
We have done a lot of work to reduce CPU usage and latency.
As you can see, the same workload previously used 3 executors (we used autoscaling), with a total usage of 2.5 cores for over 6 hours. After, only 0.5 cores were necessary through most of the runtime, with a peak of only 1.5 cores for 1 hour, the whole workload was managed by only 2 executors (minimum autoscaling).
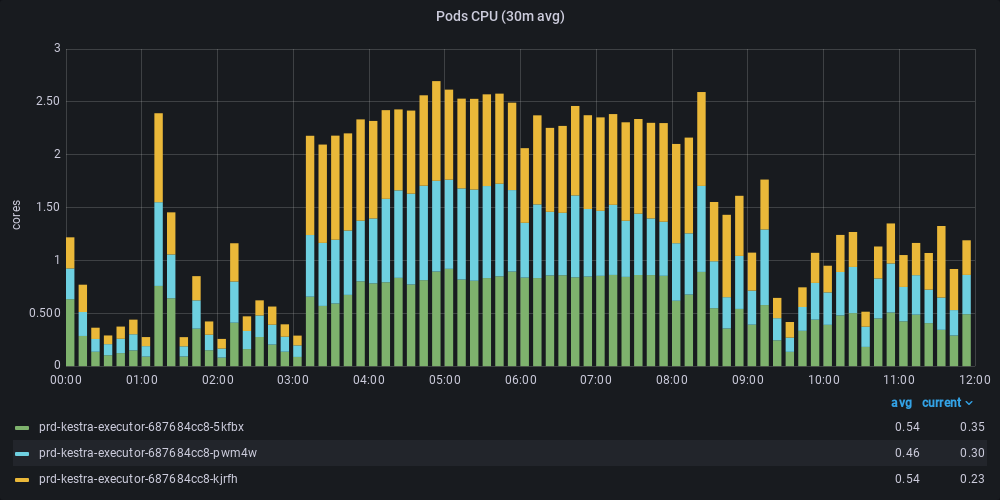
Before
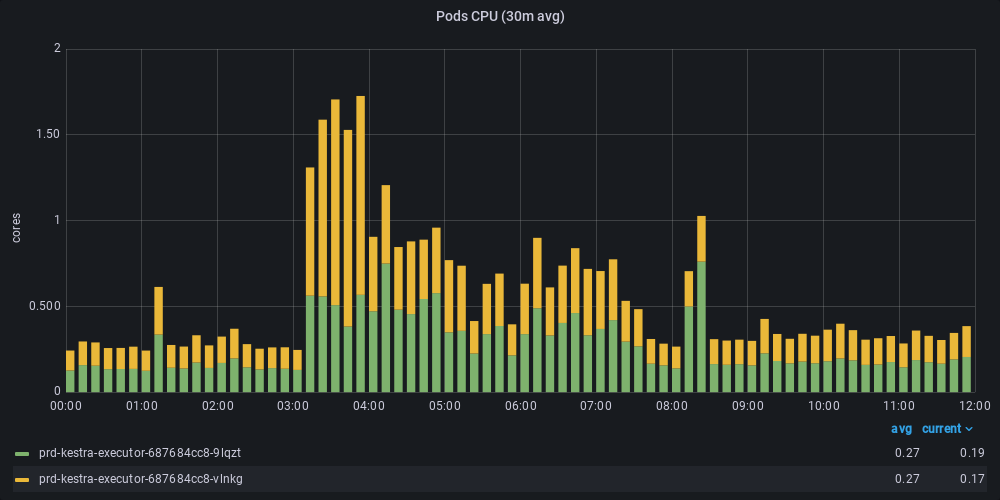
After
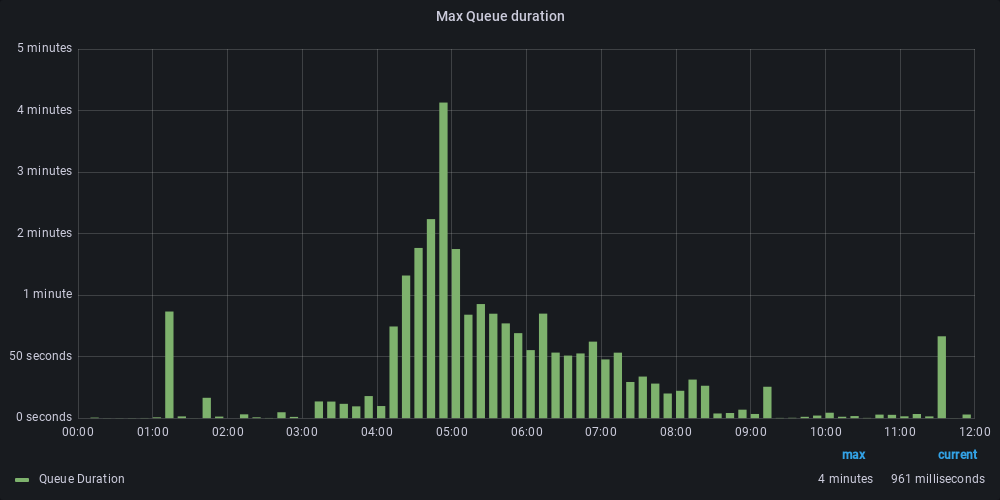
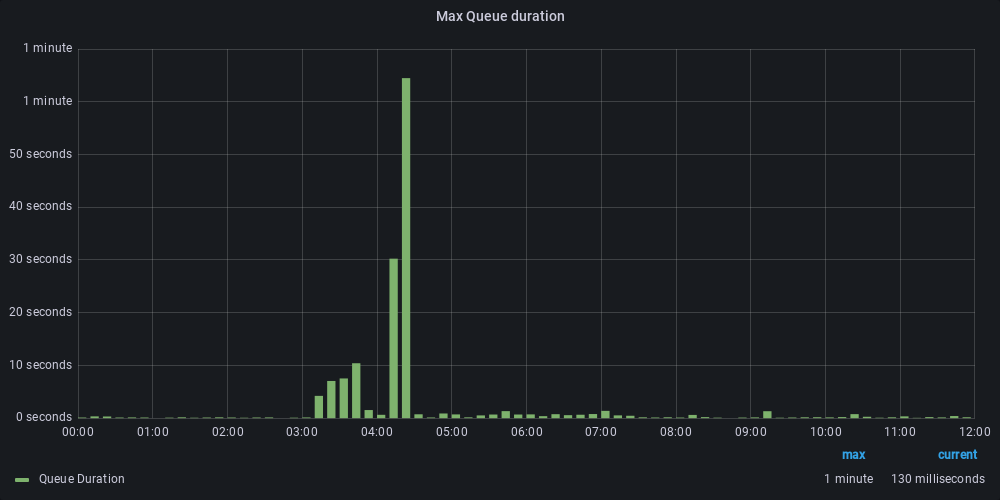
On the Kafka side, we also see improved latency. The system had a lot of flow triggers, which needed to be analyzed for each completed execution. When you have a high volume of execution, a lot of messages are sent by Kafka and if your consumer is too slow, the queue fills up and increases latency. Previously, we had a large message lag that led to a late start of flow executions (a few minutes). The optimization allowed us to keep the start of the flow to within a few seconds.
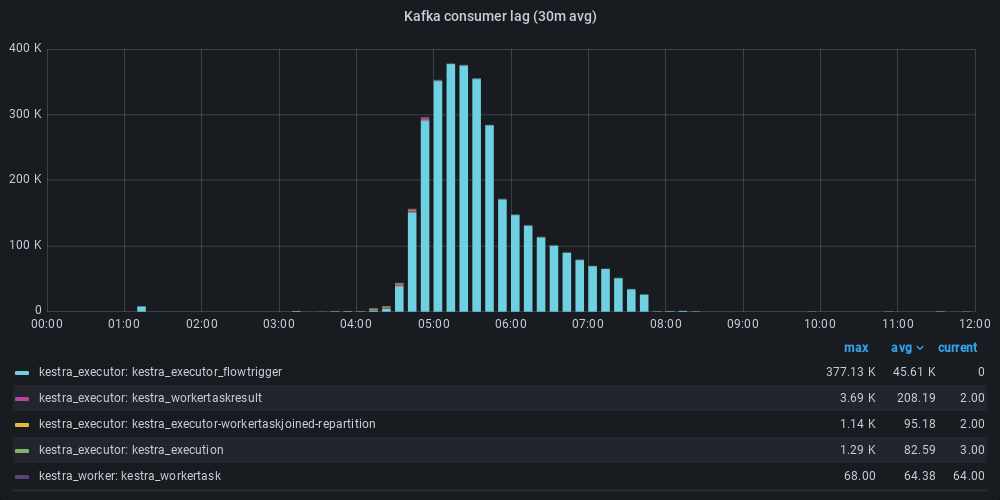
Before
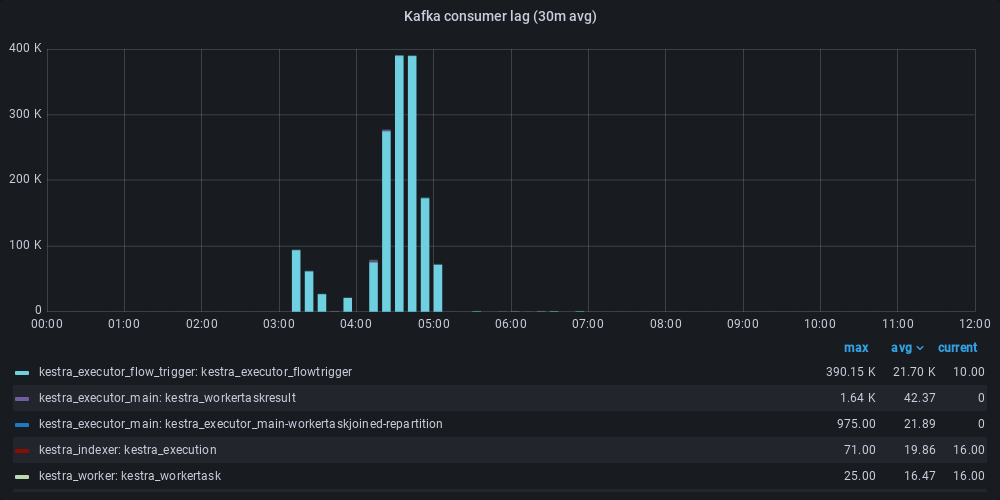
After
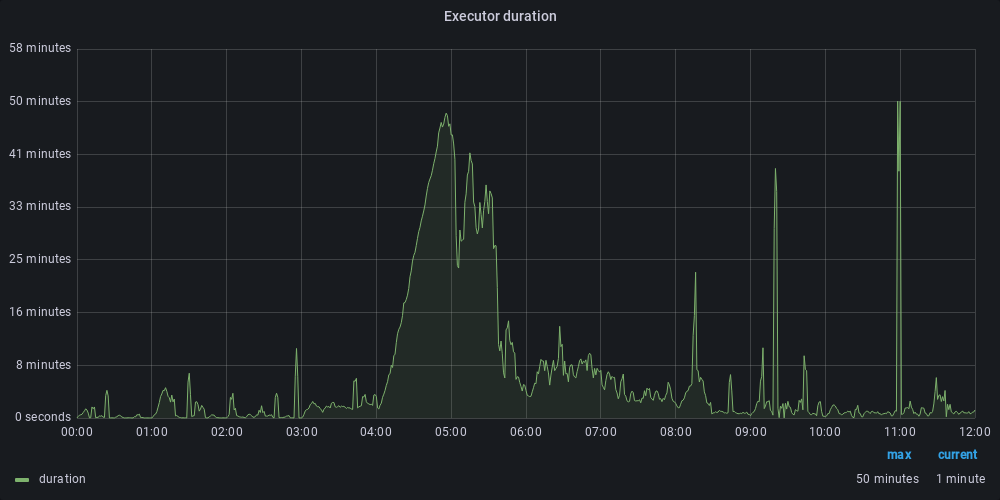
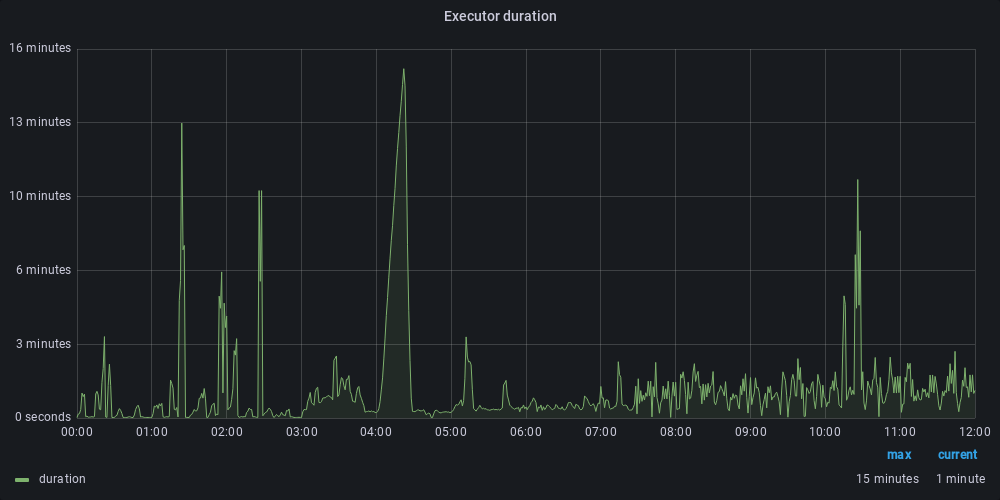
The last graph shows the delay between the creation of the task and the task launched by the worker. Since we have optimized Kafka processing globally, we avoid queuing messages on Kafka and reduce the delay between task creation and worker processing.
Before
After
All of these improvements also provide a significant reduction in total execution time. As all messages are consumed quickly, the time between each task is reduced and the total runtime is reduced.
Before
After
Keep in mind that Leroy Merlin’s workflow is unbalanced, and all executions take place at the same time, more than 3000 executions and more than 35,000 tasks in a short period of time, making up 50% of the entire day’s workload. We have to provide the same requirement for night processing, even if we are all asleep. We have more optimizations pending, but this provided a big improvement that will allow us to handle more complex clusters with lots of streams and concurrent executions. A full blog post is coming soon to expose what we discovered while scaling a Kafka Streams application.
JDBC plugins have been given a major update that allows for bulk queries. This update allows you to use any file generated by Kestra storage to generate a batch query. You can now read data from any task and generate a batch query to insert or update data in most JDBC databases.
Here is an example:
tasks: - id: query type: io.kestra.plugin.jdbc.mysql.Query url: jdbc:mysql://127.0.0.1:56982/ username: mysql_user password: mysql_passwd sql: select * from users store: true - id: load type: io.kestra.plugin.jdbc.sqlserver.Batch url: jdbc:sqlserver://localhost:41433;trustServerCertificate=true username: sa password: Sqls3rv3r_Pa55word! from: "{{ inputs.query.uri }}" sql: "insert into users values( ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ? )"In this example, we read a table from a mysql database using a Query and store it on internal storage, after generating a bulk insert that will load the resulting dataset into a Microsoft SQL Server database.
Easily move data to jdbc
Since we rely on Kestra’s internal storage, any task that produces Kestra internal storage, such as JsonReader, AvroReader, … can be used as a source. You can now move data from any source and any format thanks to Kestra plugins.
We also introduced 2 new jdbc plugins:
Both support Query and Batch queries, so you can imagine many more use cases.
The Kafka plugin is now also released with a first Produce (Consume will come soon). Like the other plugins (jdbc, json, csv, …), the Kafka plugins rely on Kestra’s internal storage, allowing you to send from any source to Kafka.
We currently support many types of serializers in Kafka, the most notable ones are STRING, JSON & AVRO with support for Kafka schema registry.
This is just the beginning for this plugin but we plan to support JSON and the Protobuf schema with the schema registry. Also, as mentioned before, we want to support Consume tasks (with OU without of consumer groups). We may also want a Trigger based on Consume that allows you to start executions based on an incoming topic, we are waiting for more feedback from the community for this part.
We have made an evolutionary improvement on our Singer plugins (deprecated). Singer operates based on 2 concepts: taps (data source) and targets (destination, where you load the data). This model is smart, since you can work with many different sources, and each can be loaded to as many destinations as you need thanks to Singer specifications.
Previously, plugins had a single target task that incorporated a tap to load from one source to a single destination. Now we have 2 different tasks that allow you to download one time from a tap and send the same result to multiple destinations.
Here is an example of loading GitHub from a repository to a BigQuery Dataset:
tasks: - id: github type: io.kestra.plugin.singer.taps.GitHub accessToken: "{{ vars.github.token }}" repositories: - kestra-io/kestra startDate: "2019-07-01" raw: true streamsConfigurations: - replicationMethod: INCREMENTAL selected: true - selected: false stream: projects - selected: false stream: project_cards - selected: false stream: project_columns runner: DOCKER dockerOptions: image: python:3.8 - id: bigquery type: io.kestra.plugin.singer.targets.AdswerveBigQuery addMetadataColumns: true from: "{{ outputs.github.raw }}" datasetId: github location: EU projectId: "{{ vars.serviceAccount }}" serviceAccount: "{{ vars.projectId }}" runner: DOCKER dockerOptions: image: python:3.8You can still use Kestra’s internal storage with any singer taps and use the data with any Kestra tasks:
- id: github # same as above raw: false - id: update type: io.kestra.plugin.jdbc.sqlserver.Batch url: jdbc:sqlserver://localhost:41433;trustServerCertificate=true username: sa password: Sqls3rv3r_Pa55word! from: "{{ outputs.github.streams.commit }}" sql: "insert into commit values( ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ? )"We also added another singer destination Oracle.
VertexAI is a complete suite for machine learning that allows you to build, deploy and scale ML models faster.
We’ve added a CustomJob that starts a Vertex AI Custom Job. This one is based on a docker image that you can launch on any type of instance, with or without a GPU. It allows you to deploy any kind of custom code to be run in ephemeral clusters and will be stopped when the job is finished. This is perfect for large-scale machine learning, but it can be used for any Docker image that requires a large compute engine without having to create a Kubernetes cluster or compute engine.
The integration will start the vertex job and wait for the job to finish before passing the job status to Kestra. We have done a deep integration, so you will also receive real-time logs for your running jobs.
tasks: - id: tableAnalysis type: io.kestra.plugin.gcp.vertexai.CustomJob delete: false displayName: "{{ task.id }}" projectId: "{{ vars.serviceAccount }}" serviceAccount: "{{ vars.projectId }}" region: europe-west1 spec: serviceAccount: service-account-name@project-name.iam.gserviceaccount.com workerPoolSpecs: - containerSpec: args: - "-e" - "{{ globals.env }}" commands: - /app/start.sh imageUri: "{{ vars.imageUri }}" machineSpec: machineType: n1-standard-4 replicaCount: 1We also improved the retry of all BigQuery tasks. By default, we retry all operations with an internal error for Google servers, but also some errors that could happen in real life, including: rateLimitExceeded, due to concurrent update, and more… These are many cases in which a simple retry will make the task successful. So we enable it by default. For a large use of BigQuery, such as our implementation at Leroy Merlin, this avoids unexpected failures that a simple retry could solve.
Now we catch many errors automatically on BigQuery that can be retried.
For the Enterprise Edition, we delivered the most requested features: the ability to see all flow dependencies recursively.
We also added a confirmation when deleting a flow that has dependencies, which warns the user that deleting it might break the whole production plan.
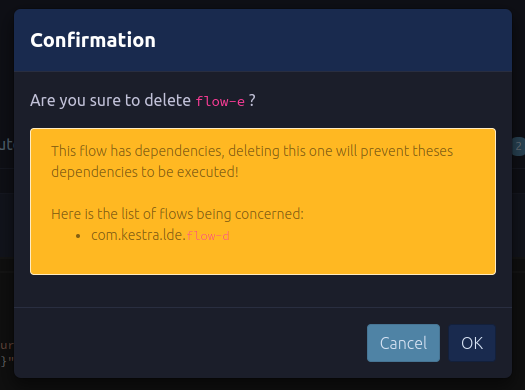
This is a valuable feature that provides a complete view of your entire data pipeline across teams. With many teams consuming data from other teams, no one can be sure whether if this flow is changed, another flow will be impacted. Impact analysis is greatly simplified with this powerful user interface.
In the meantime, we have released versions 0.4.1 and 0.4.2 to fix a few minor bugs and to provide some nice polish to our UX and UI.
We are working on the next step with a lot of new plugins allowing stronger integrations with the ecosystem. Stay connected and follow us on GitHub, Twitter or Slack.

Stay up to date with the latest features and changes to Kestra