Authors
Benoit Pimpaud

Benoit Pimpaud
Infrastructure as Code (IaC) has become the industry standard for cloud resources management and configuration.
It allows teams to easily collaborate across multiple resources through providers and have a common declarative syntax for several purposes: IAM policies, Kubernetes clusters, database users and tables, etc.
What if this same principle were applied to Data Engineering?
That’s what Gorgias is doing with Kestra.
These days, workflows span diverse tools— from ETL scripts, data transformations, and database operations to reverse ETL processes and ML model training.
Managing modern data infrastructure involves configuring resources across various domains:
With a growing number of workflows and data volume, Gorgias engineering teams found themselves having to maintain complex logic across multiple heterogeneous systems.
Embracing standardization helps them accomplish more consistent usage patterns, e.g., using Airbyte for data ingestion enforces writing connectors with a common structure. However, it was not enough to keep data flow logic versioned and maintainable.
Engineering and technical debts start to rise and it is more and more difficult to delegate part of the upstream scope (ingestion, transformation) to data consumers such as data analysts, marketing, HR, or growth teams.
Let’s dive into how Gorgias adopted IaC principles for its data infrastructure using best-of-breed tools, including Kestra, Airbyte, dbt, Hightouch, and Terraform.
Several months ago, Gorgias faced the limitations of embedded schedulers leading them to the adoption of a dedicated data orchestration tool.
Although many modern data tools integrate schedulers (Hightouch, Dbt cloud, Airbyte, GCP with Cloud Scheduler and scheduled queries), they are not built for handling complex orchestration needs, such as retry policies, event-triggered workflows, and complex dependencies.
Also, managing numerous execution logs across different tabs further highlights the need for a centralized orchestrator to streamline operations and enhance visibility.
Kestra is transforming data pipeline management by using a declarative approach, making it easier to bring Infrastructure as Code best practices to data engineering workflows. That declarative interface fits seamlessly into Gorgias’ existing toolkit, which includes Airbyte, BigQuery, PostgreSQL, dbt, GitHub, Slack, Hightouch, and others. With Kestra, creating and overseeing tasks becomes more intuitive thanks to its comprehensive UI. Kestra also supports Webhook triggers natively and integrates with Terraform to add versioning and modularity to data flows.
One of Kestra’s strengths is its ability to scale effortlessly. It can handle millions of flows simultaneously and provides users full control over their data, including the option for self-hosting on Kubernetes. Additionally, contributing to Kestra’s plugin ecosystem has been a straightforward process.
For the Gorgias team, streamlining processes like initiating Airbyte synchronization followed by dbt transformations and setting up efficient retry policies for dbt jobs has been particularly valuable, as they have shifted to BigQuery’s capacity-based pricing. Kestra also enables the Gorgias team to schedule Hightouch synchronization after dbt jobs to ensure data remains current, trigger ETL Python scripts with easy monitoring, centralize their log management, and use an integrated UI. This UI allows for the quick creation of flows with a user-friendly workflow editor and offers a wide range of blueprints for various needs.
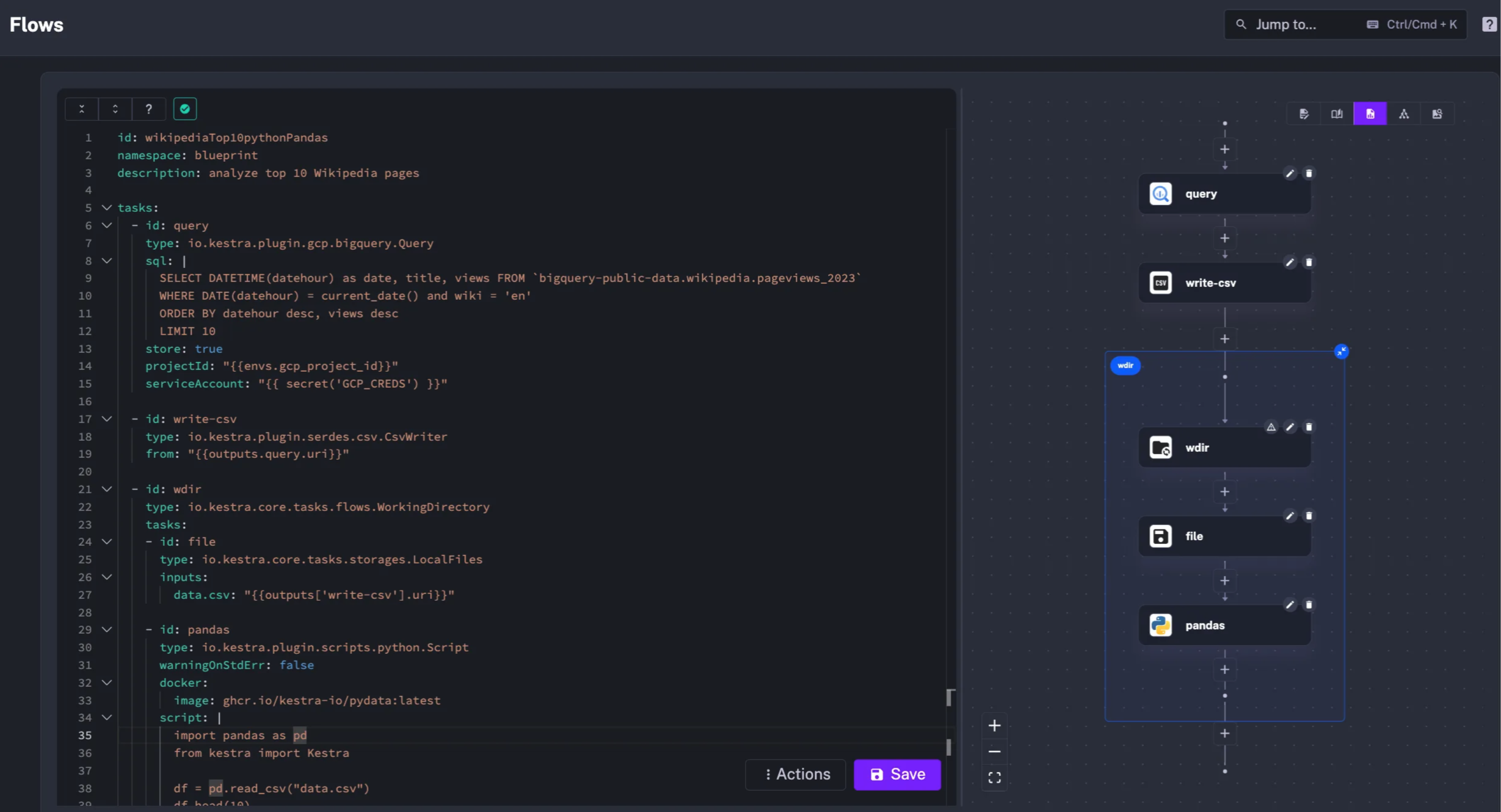
To provide modular development experience, the Gorgias team leverages Terraform modules and the subflow pattern in Kestra.
Modules are used as an abstraction layer for regular users to write flows (i.e. triggering an Airbyte sync followed by a dbt transformation) without having to worry about Kestra syntax, authentication, or connection details.
Subflows are used for generic tasks:
depends_on field in subflows/main.tf. *Can be used by modules to hide some non-necessary complexity and to dry redundant tasks (Running a SQL query on a given PostgresDB)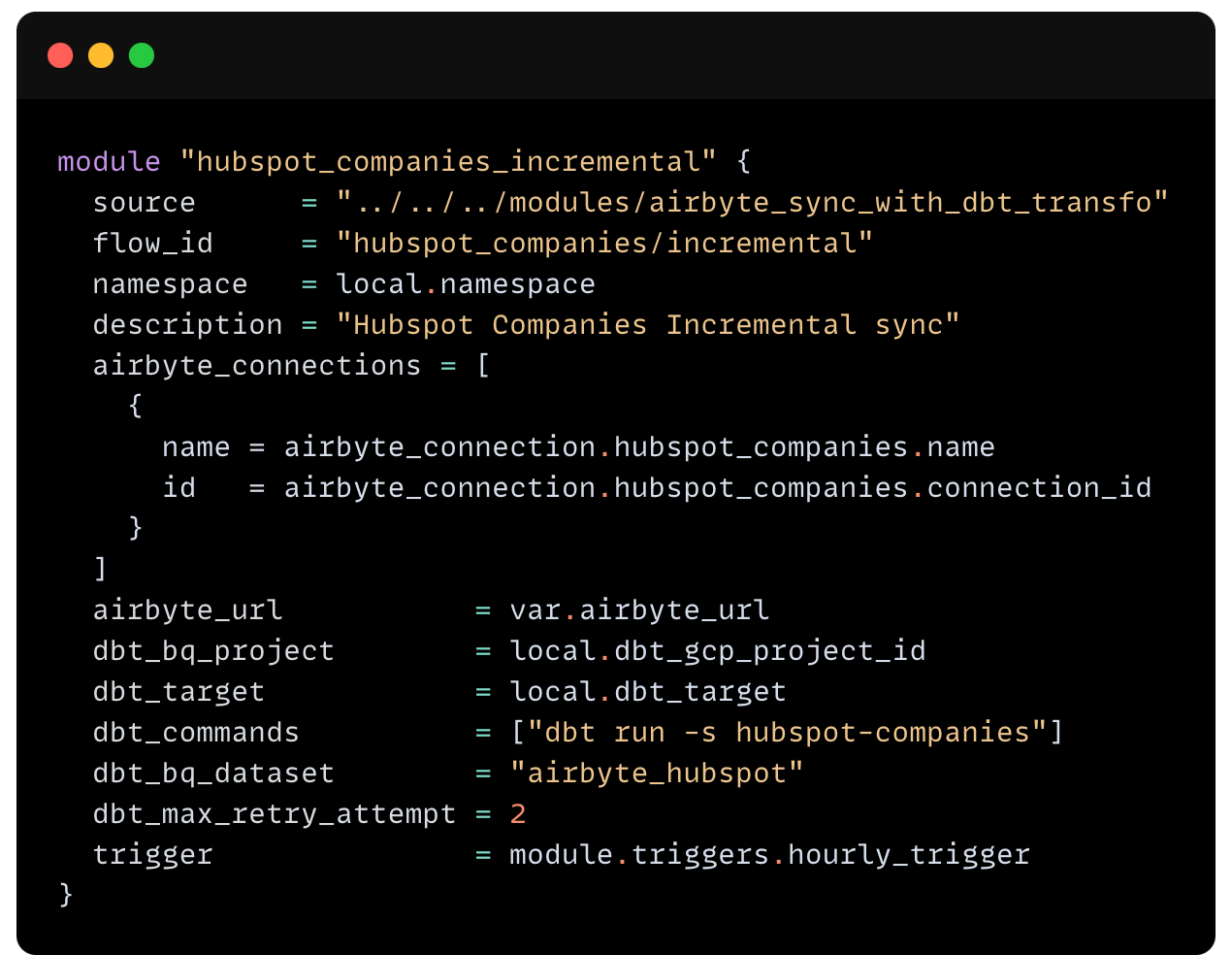
Logs are fully streamed from Airbyte to Kestra to provide a centralized platform for monitoring and debugging :
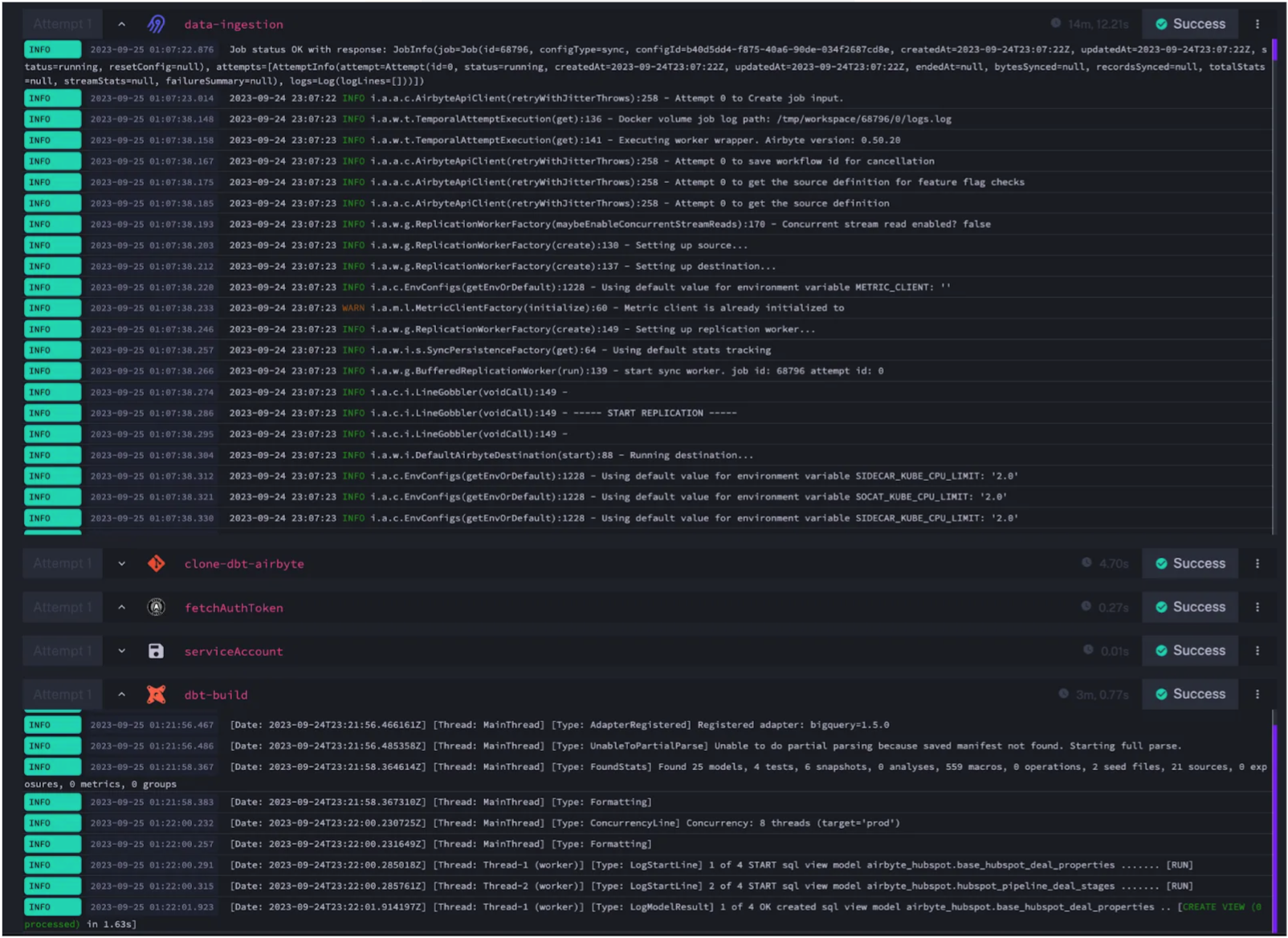
Maintaining a direct connection between external CI/CD tools like GitHub Action to the Kestra server service involves solutions like:
To be more efficient, Gorgias’s team uses Kestra also as a CI/CD engine. As they are applying configuration change on a self-hosted instance, it’s easier to run Terraform directly on their Kubernetes cluster.
With the dedicated Kestra Terraform plugin, they can apply changes to a local Kubernetes service endpoint using kube-DNS resolution. This way, their entire data infrastructure is managed using Kestra.
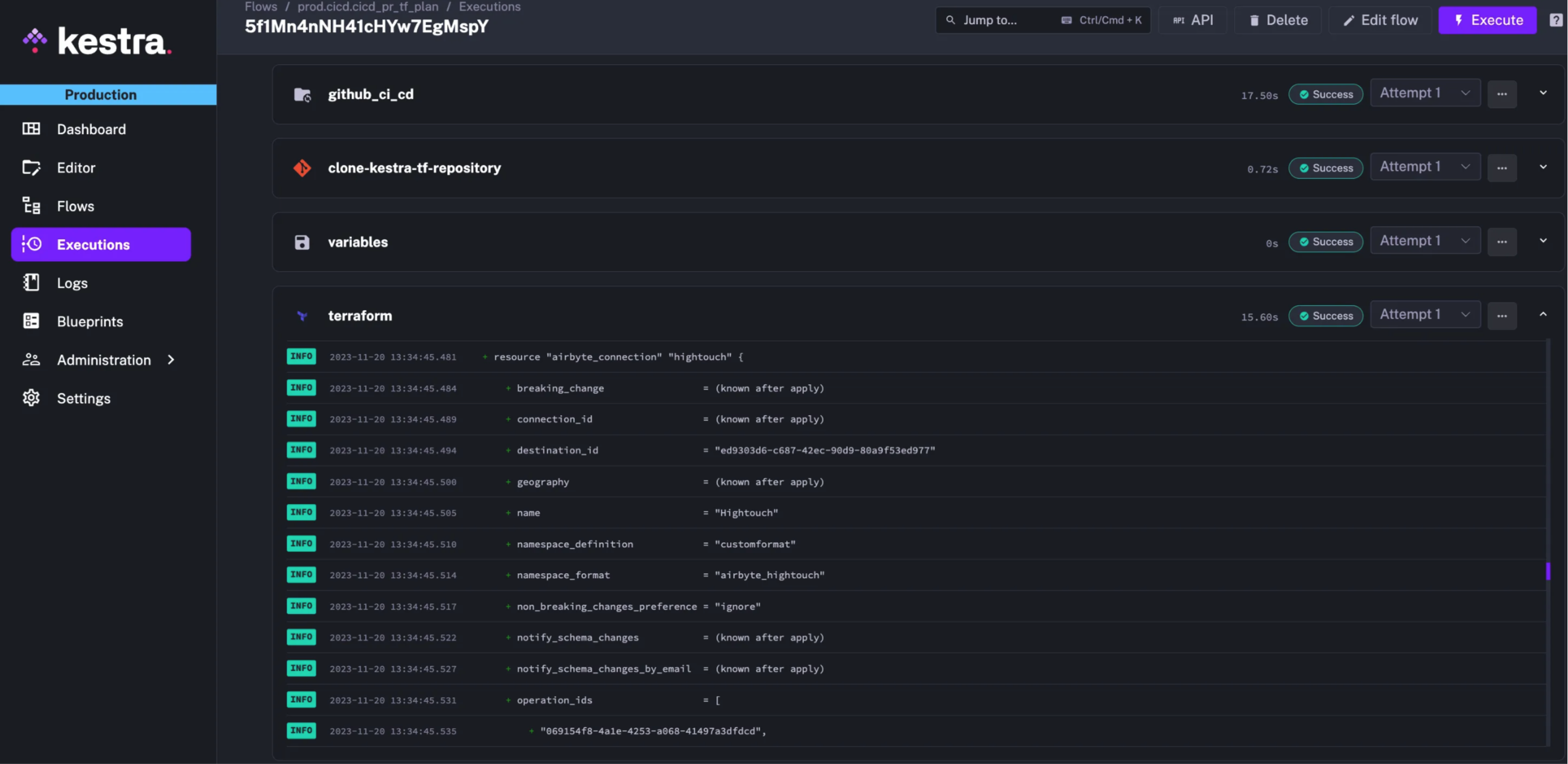
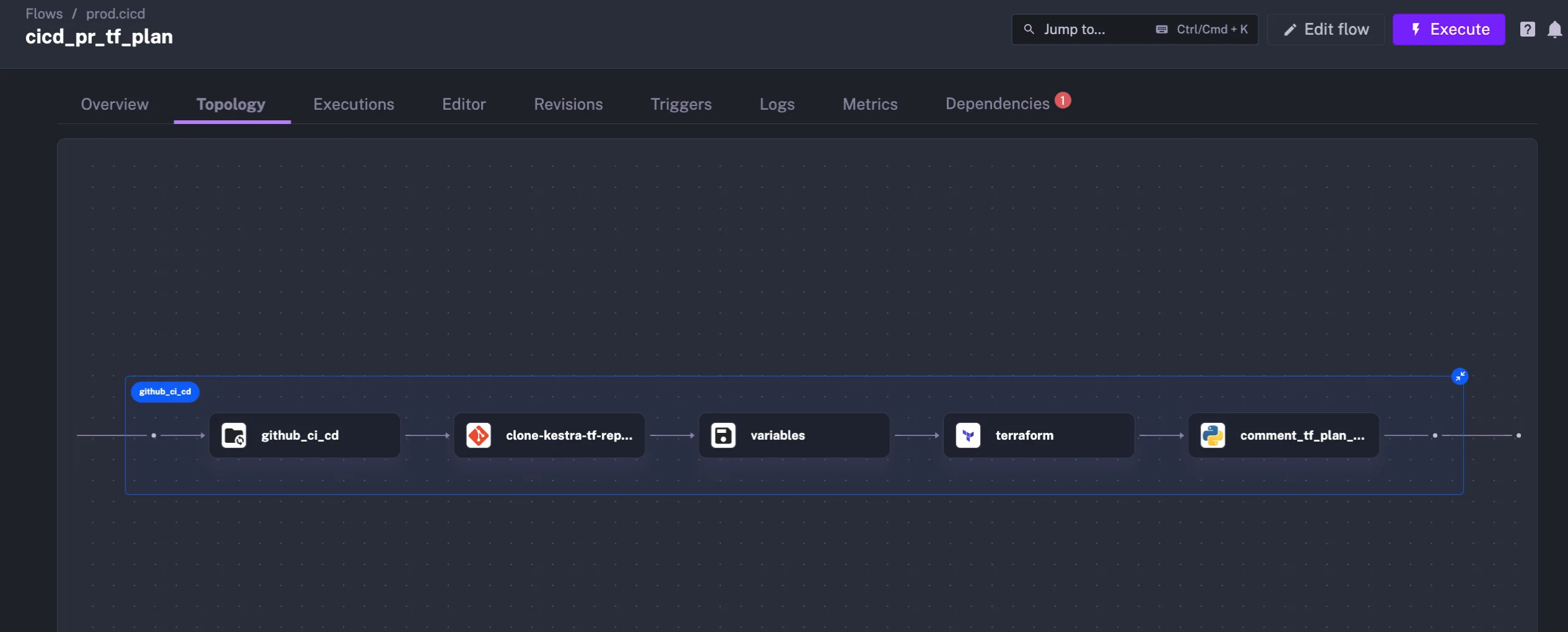
Declarative interfaces are gaining popularity as data teams embrace Infrastructure as Code best practices. Kestra allows data practitioners to collaborate using a common tool.
Join the Slack community if you have any questions or need assistance. Follow us on Twitter for the latest news. Check the code in our GitHub repository and give us a star if you like the project.

Stay up to date with the latest features and changes to Kestra