
Authors
Loïc Mathieu
Loïc Mathieu
One of the recent Kestra evolutions I was responsible for was multitenancy support, a critical feature for providing scalable and secure data management solutions to a wide range of clients. This blog post delves into how we’re implementing multi-tenancy at Kestra, guided by insights from a recent talk I gave on designing multi-tenant SaaS systems.
Multi-tenancy is a software architecture model that enable a single instance of software to serve multiple tenants or client organizations, It simulates several logical instances within a single physical instance. The goal is to maximize resource efficiency while ensuring data isolation and operational cost control.
Multi-tenancy comes in various forms, each with its pros and cons, from separate instances per tenant to shared databases with tenant-specific schemas or data rows.
This model advocates for launching a distinct application instance for every tenant. While its simplicity is appealing, it demands higher operational costs due to the need to maintain individual instances for each tenant.
Here, each tenant benefits from a dedicated database, ensuring data isolation at the database level. This straightforward approach slightly elevates implementation costs but also raises operational expenses, as it requires maintaining separate databases.
In this approach, we allocate a unique database schema for every tenant within a shared database environment. It strikes a balance between simplicity and operational efficiency, offering a cost-effective solution without the complexity of managing numerous databases. However, it leans on the database’s ability to support multiple schemas, which could become a single point of failure (SPOF).
The most flexible yet complex model involves embedding a tenantId identifier in each table row. This method offers great operational efficiency and flexibility but demands a higher implementation effort to ensure data isolation and security.
Kestra’s architecture is built on a distributed system, where various components interact asynchronously, primarily through messaging queues. Below is an overview of the key components that make up Kestra’s architecture:
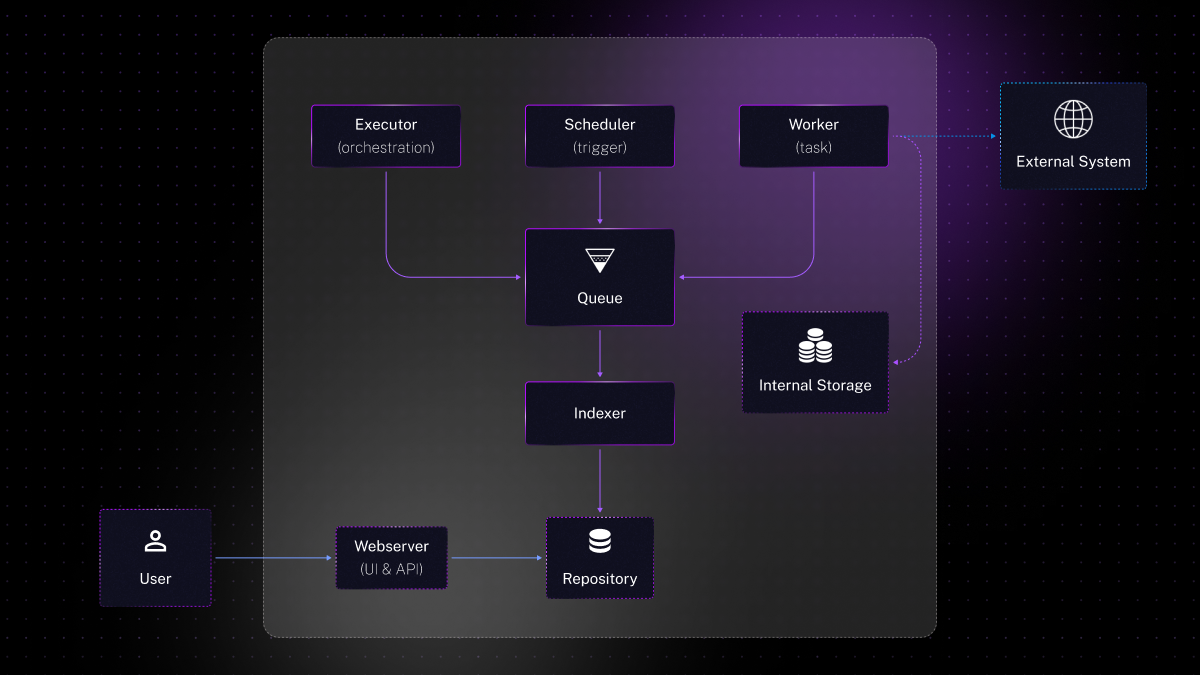
note that the Worker is the only component that access to external systems needed to execute a flow (remote database, web service, cloud service, …) as well as Kestra’s internal data storage.
Kestra supports several deployment modes, with all components in a single process, or microservice with one component per process.
For data management and queueing, Kestra utilizes two main runners:
The objective? To create a robust, highly available cluster that can host a Kafka runner for each cloud provider and region, ensuring:
Namespaces are hierarchical structures similar to filesystem directories, they are a component of Kestra used to store flows. Namespaces allow for specific configurations (e.g., tasks, secrets) and role-based access control in our enterprise version, raising the question of their utility in our multi-tenant architecture.
Our exploration of multi-tenancy models revealed three viable options:
tenantId Property: Introducing a dedicated tenantId across Kestra’s components to distinctly identify tenant data.As one of Kestra’s runners uses Kafka and Elasticsearch, which do not support the notion of schema, only a declination of the Tenant model within tables/messages was possible. The three solutions therefore propose adding the tenant to a new property or using an existing property (namespace) to limit the changes required.
tenantId ApproachUltimately, we selected the tenantId model for its flexibility and alignment with Kestra’s distributed architecture. This approach enables us to maintain the granular control needed for effective multi-tenancy, such as data isolation and tenant-specific configurations, without limiting user functionalities in the cloud or complicating the underlying system.
Using namespace would have been convenient, as we already had namespace-based flow isolation as well as role-based access management. But it would have greatly reduced the functionality of a user of our Cloud, as a namespace or basic namespace could not have been used by different users.
Incorporating a tenantId across Kestra required us to:
tenantId propertytenantId at the API layer.You see it comming, it was not that simple!
Adding a property to a large number of classes / filters / queries / … brings a high risk of oversight, and therefore of bugs. And that’s exactly what happened.
Despite great care during implementation, there were a few places where the tenant was not passed:
tenantId across various system components led to inevitable oversights, resulting in bugs. Particularly challenging was managing context passage due to complexities with Lombok builders.To ease the transition for existing users, we introduced a default tenant strategy, represented by a null tenantId. This approach, while intended to simplify migration, introduced its own set of complexities and bugs..
The process of embedding multi-tenancy into Kestra revealed the complexities of altering a system’s foundational architecture to accommodate such a significant feature. Through this journey, we’ve gained insights into both the potential and the pitfalls of implementing multi-tenancy, setting a solid foundation for Kestra’s evolution as a platform.
In conclusion, multitenancy is essential when setting up a SaaS, and once you’ve carefully chosen your implementation model, you can expect a long, laborious and bug-prone implementation. To mitigate the risk of bugs, we choose to merge the PR on the multi-tenant at the start of the release cycle, which enabled us to test it for a month on our own test environments before delivering it to our users, thus uncovering many of the bugs that had been introduced.
As a final note I strongly recommend that you plan a substantial testing period, as we did. implementing a multi-tenant architecture isn’t easy, ideally, it needs to be implemented as early as possible in a code base.
Stay tuned for more insights on our engineering journey!
this blog post was originally posted in my personal blog you can check it here
If you have any questions, reach out via Slack or open a GitHub issue.
If you like the project, give us a GitHub star and join the community.

Stay up to date with the latest features and changes to Kestra