Authors
Ludovic Dehon

Ludovic Dehon
Adeo is the leading French company in the international DIY and home improvement market; it is also one of the world’s top three companies in the industry, and is moving from strength to strength.
Leroy Merlin is the leading brand of the Adeo Group and helps residents around the world with all their home improvement projects - from renovations and extensions, to decoration and repairs. With more than 450 stores across the globe and 140 in France alone, Leroy Merlin France has strong data values and a need to deliver on their KPI to their 80,000+ employees to drive their expansion.
In this article, we will explore Leroy Merlin’s data architecture, their development project in the cloud, and how our Kestra orchestration platform contributed to perfectly meet the constraints and ambitions of our partner.
Leroy Merlin, has historically used the following stacks in order to manage their data pipelines:
These methods were at one time commonplace, but today are outdated. This became more and more obvious in recent years with competitors ever increasing cloud adoption. Below are just some of the challenges to their on-premise approach:
These issues could be directly attributed to tools that no longer performed adequately, and the solution’s general lack of cloud readiness.
In 2019, Leroy Merlin and Adeo decided to move from an on-premise server to a cloud-based system. They needed a solution that could not only handle all the previous use cases, but improve upon them, and find a new way to work, all with an ambitious objective: being a fully cloud-based operation by 2022!
They decided to create an entirely new team with that goal in mind, and took an empty page and filled it with a brand new solution for the migration process. They needed to define each component of the future data platform (from storage, pipeline, source code, etc.), build the platform, and demonstrate how to use it for all data engineers (approximately fifty people).
Adeo has a strong partnership with Google, and since Leroy Merlin is a subsidiary, the storage choice was Google BigQuery. Second decision: everything needed to be hosted on GitHub and to have a strong CI/CD process in order to go to production. Terraform was the obvious choice here due to the large ecosystem and native integration with BigQuery and other GCP resources.
Next, they needed to decide on how to transfer the data, load it in BigQuery, and transform and aggregate the data. For the transport layer and load, no obvious choice had presented itself. So, they decided to build a custom solution (based on the GCP (Google Cloud Platform) service). For the orchestration, a lot of people were using Airflow, so why not use such a popular system? What’s more, GCP even had a fully managed orchestration service: Cloud composer.
Leroy Merlin decided to start each of these new projects on the cloud directly before beginning the migration of existing projects. The first projects were coming along, the build was done, and more projects were in production — now they could start the process of concluding past projects.
Whilst not entirely successful, the initial process revealed some points that helped them to find their direction; the following findings were particularly helpful:
One major flaw: The custom tools were made in Python and needed to be installed on the system that would send the data. Since Python has a complicated lifecycle, there are systems that just can’t install Python 3, leaving only one option: develop multiple versions of the tools to target all systems, which would be unsustainable.
The choice of Airflow seemed to be a good one as it gave us the ability to handle a lot of complex workflows with simple Python code. So, the custom transfer tools would trigger Airflow DAG after the load on BigQuery. Airflow would handle all the other tasks: transform/aggregate/reverse ETL, and so on.
But it failed at Leroy Merlin. First, the implementation by Google: Google Cloud Composer had various limitations and was quickly rejected. So Leroy Merlin decided to install their own Airflow on Kubernetes Clusters. This appeared to have been a better option; more control, more stability. However, it still presented a lot of issues:
BigQueryToGCSOperator, BigQueryToMySqlOperator, BigQueryToBigQueryOperator, …). - It would not scale to develop many operators.Even when we persevered with it, the performance level was not there; Airflow failed on the first project; the duration of the flow was twenty times longer than the same flow with Stambia, and the analysis showed that this duration would increase over time and would not scale to the number of DAGs and executions wanted.
Decision
By this time, Terraform and BigQuery had demonstrated their strengths and, Airflow, custom transfer and load tools had been rejected. Leroy Merlin needed to find another option, and no solution had presented itself.
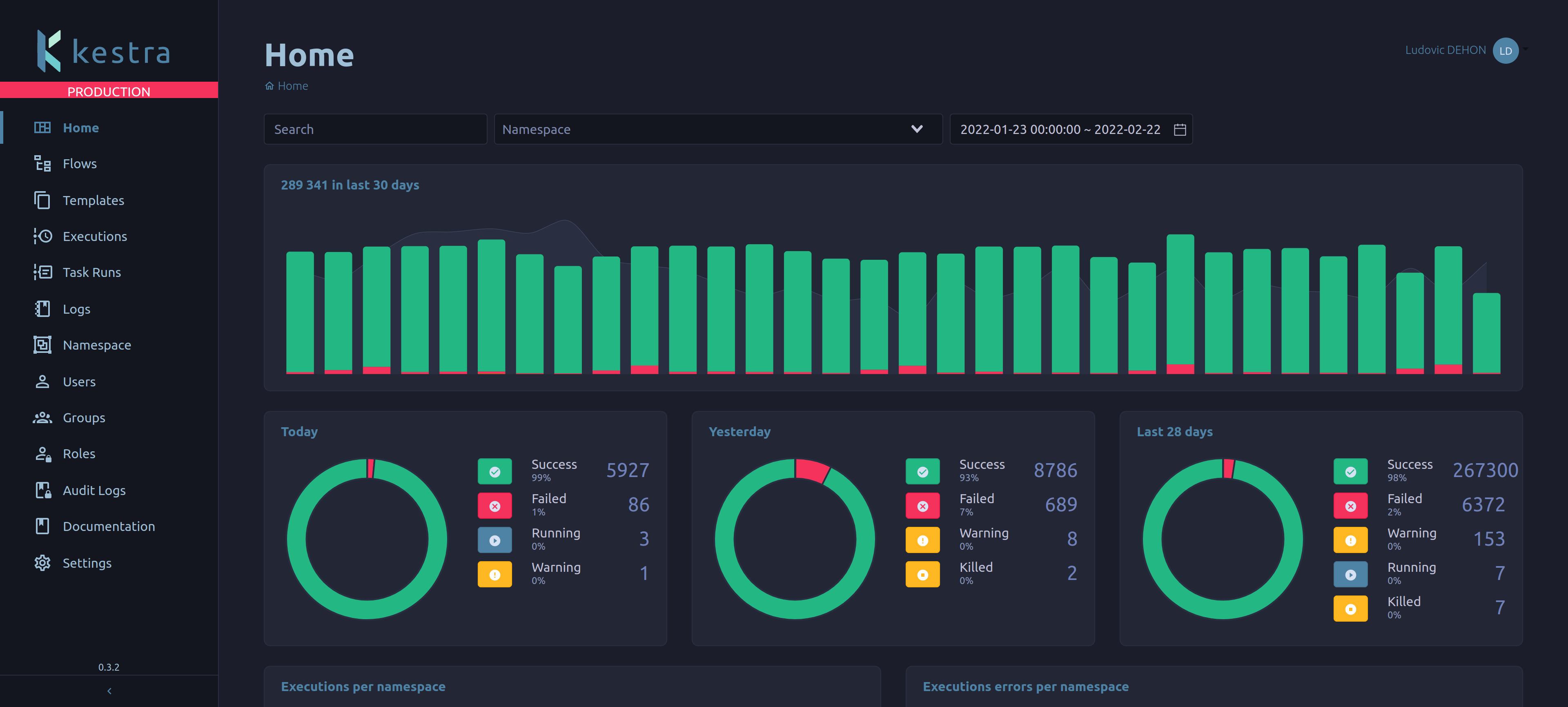
In the meantime, the Kestra team had started working on the Kestra platform and presented the first version to Leroy Merlin. The LM team leaders were very interested and decided to test the solution for a few months. Since some features were missing at this point, they also decided to contribute to the open-source project and some new plugins.
They also moved with great speed to develop a Kestra plugin to help simplify the ingestion process called DataPlatformIngest. Removing the burden of loading data, the plugins:
The transfer of the data was in HTTPS directly to the Kestra API in order to free any dependencies. The operational system used most frequently was a simple curl command in order to trigger ingestion or develop a simple HTTP client reaching the Kestra API.
This single task handled all the complexities of loading data — it would create ten to twenty tasks:
id: locknamespace: fr.leroymerlin.services.product.orchestrator-inputs: - id: stock type: FILEtasks: - id: 01_ingest_ods_stock type: com.leroymerlin.dataplatform.dcp.tasks.DataPlatformIngest avroOptions: dateFormat: yyyy-MM-dd datetimeFormat: yyyy-MM-dd' 'HH:mm:ss nullValues: - \N - "1900-01-00 00:00:00" schema: |- { "type": "record", "name": "stock", "namespace": "io.kestra", "fields": [ { "name": "name", "type": "string" }, { "name": "lock_until", "type": [ "null", { "type": "long", "logicalType": "timestamp-millis"} ] }, { "name": "locked_at", "type": [ "null", { "type": "long", "logicalType": "timestamp-millis"} ] }, { "name": "locked_by", "type": [ "null", "string" ] } ] } csvOptions: fieldSeparator: "|" dataset: supply fileType: CSV from: "{{ inputs.stock }}" table: stock version: 1At Leroy Merlin, there are over eighty data engineers and data scientists. They each needed to learn how to use Kestra; but since it was based on a simple declarative language (based on YAML), this process was quick and people were able to use it within a few hours.
Also, as there was a rich UI, the deployment process was really easy at the beginning — just save on the UI, and you’re good to go!
Subsequently, Leroy Merlin started using Terraform in order to deploy every cloud resource; they also deploy Kestra resources using terraform providers. They were able to reach a full DataOps lifecycle, all deployment is atomic with a git push and a strong CI/CD applying resources from terraform.
Reach a fast time to market
Before this DataOps lifecycle was implemented, the deployment involved a number of teams: a transfer team that moved the files between systems, an orchestration team which triggered the job after the transfer, a data team that would develop the loading of the data in addition to a manual operation in order to create a resource on the data warehouse. All these operations needed to synchronize with the internal ticket that was now in service.
Thanks to Kestra, they moved to full autonomy and reduced the time to market from days to only a few hours
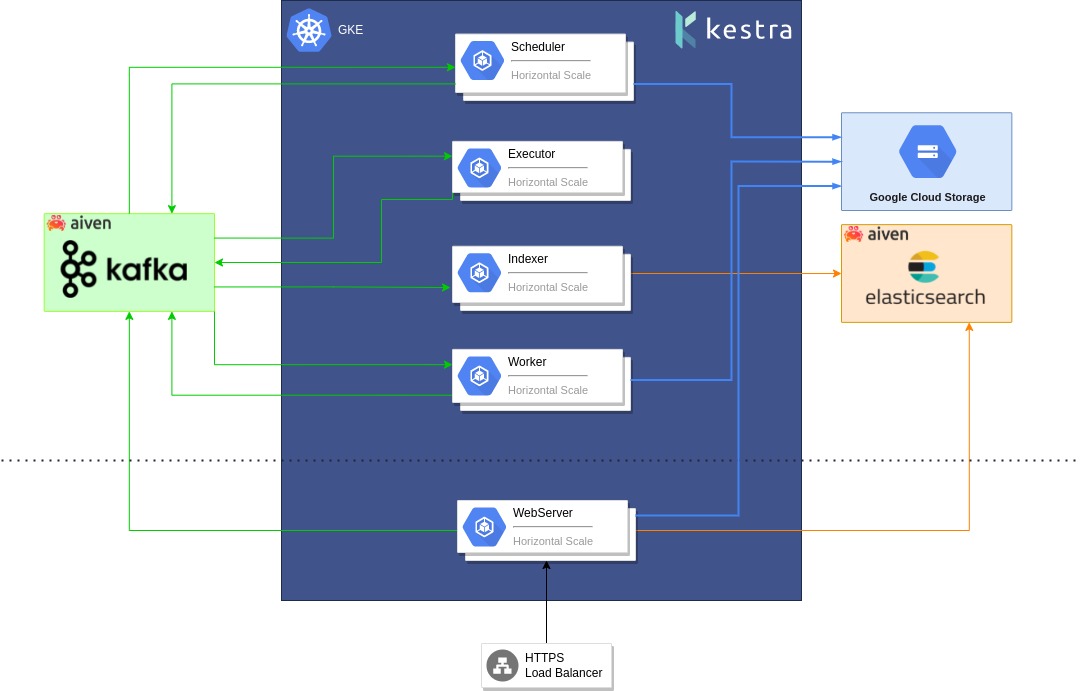
After a few months, Kestra was confirmed and was deployed to a production environment in May of 2020. They also decided to move to the Enterprise Edition of Kestra in August 2020 as they needed to have fine-grained security, role-based access control and single sign-on.
The usage grew exponentially over the coming months, and the kinds of usage are becoming increasingly varied: (starting flows based on file detection from buckets, syncing data warehouses directly from operation postgres database, developing a simple python program to fetch APIs from a partner, starting long-running data science processes over Kubernetes, fetching data from Google Drive and writing results back to Google Sheets, and so on.).
Here are some numbers that show the current usage for January 2022 ( for production environment only):



Leroy Merlin has strongly supported the development of Kestra. As with any software, its young age could be a source of frustration for users. They needed to handle missing features, report some bugs, suffer some time loss from instability. But what was astounding was the realization that the pain was far less than the gain, and we obtained many good reports on software internal notation tools. It proved to be a solution that users really love and uphold.
Here’s what people shared with us:
“Tool responds perfectly to the need. Very easy to use; it manages all the complexity behind to offer a saving of time and huge savings.”
“Kestra is a tool that is very easy to use with constant improvement in functionality. It covers almost all data pipeline setup needs.”
“Kestra is very easy to learn, with a large number of functionalities covering a large number of use cases (scheduled workflows, API calls, triggers, flow synchronization, data and file transfers, etc.). The Web interface facilitates the monitoring of flows and the consultation of logs. New features are added very regularly, often in response to needs. Kestra is evolving rapidly.”
“After suffering with Airflow to schedule different treatments, Kestra’s arrival was more than saving. The ecosystem of plugins is evolving rapidly and greatly facilitates integration with different bricks, especially on GCP (BQ, GCS, Cloud SQL, etc.) A tool that deserves to be known more.”
Leroy Merlin was a great help to Kestra by supporting it in its infancy; but we really think it was a win-win partnership. Kestra is a tool that allowed Leroy Merlin to successfully conduct its cloud migration and embrace the DataOps development design.
According to the Leroy Merlin manager, the true revolution was:
“Kestra is the first tool that allowed us to develop without installation, use your browser and start to build a true business use case within few hours. Since the learning curve is easy, you can easily onboard new teammates due to its descriptive language. And, moreover, it handles all parts of the data pipeline: the transport, load, transform, data modeling, data quality and monitoring of all our data pipeline. Since the tool offers strong role-based access and security on the Enterprise Edition, we are safe to share it in Software as a Service to all applications allowing us to also embrace the Data Mesh pattern.”

Stay up to date with the latest features and changes to Kestra