
Authors
Ludovic Dehon
Ludovic Dehon
The importance of data pipeline management and orchestration in today’s data landscape cannot be overstated. Various products available in the market, each with its unique approach to data handling, can make the task of selecting the ideal solution daunting. This article delves into comparing Debezium with Kafka Connect and Kestra, our declarative data orchestration platform for a more resource-efficient and cost-effective hybrid solution.
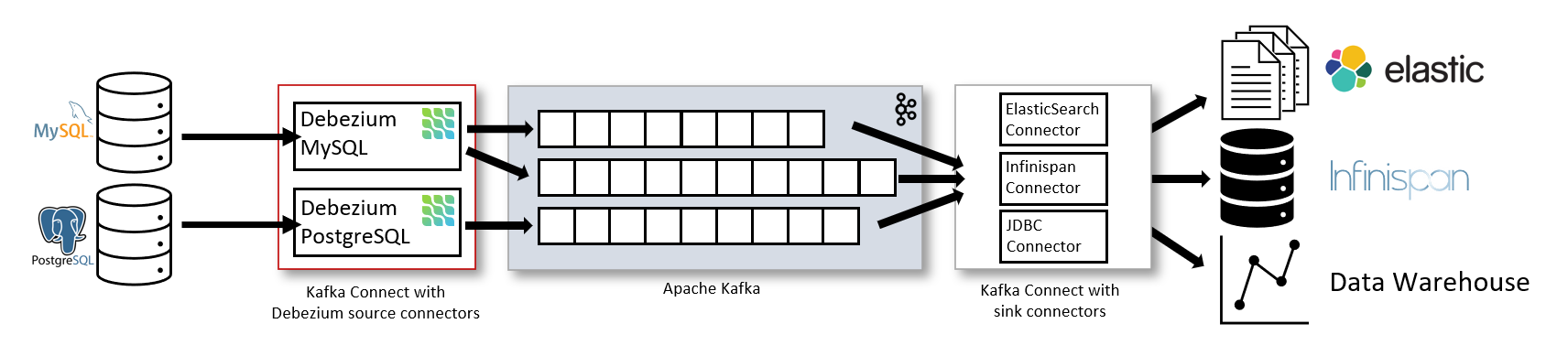
Debezium is an open-source platform developed by Red Hat that stands out in the Change Data Capture (CDC) field. It tracks and records row-level changes in your databases, enabling connected applications to respond in real time. Debezium’s strength lies in ensuring exactly-once delivery of all changes in the precise order they were made. Furthermore, Debezium’s ability to monitor changes in data from multiple sources and various types of databases makes it a highly adaptable tool in data pipeline management.
Debezium has gained traction for its real-time delivery of data changes, which applies to both streaming sources and databases under heavy workloads. To support these modern high-volume workloads, Debezium employs Kafka Connect for a constant, always-on connection, capturing data changes as they occur. While this results in robust real-time performance, it also demands significant resources, including bandwidth, CPU, and memory.
Its continuous monitoring of upstream databases is indeed one of its powerful features. For each row-level change, it generates an event that comprehensively describes those changes. However, this functionality comes with its own set of challenges.
The Kafka Connect connectors, which Debezium relies on, operate incessantly. This persistent operation means that they have to adapt to any structural changes to the tables over time, which in turn can cause events to become larger and more complex. Consequently, the processing of these events demands a higher allocation of resources.
Moreover, even in the most simplified Debezium deployment, there are typically at least two Kafka Connect connectors running concurrently. One is responsible for pulling data from the upstream source, while the other pushes the changed data out to various destinations, be it data warehouses, databases, or applications. These connectors work at a constant pace, consuming a fixed bandwidth, and require dedicated processing and memory resources to ensure almost instantaneous data receipt and delivery.
Although Debezium shines as an efficient and performance-oriented solution in real-time Change Data Capture (CDC) use cases, this perpetual operation can become a resource drain. The always-on nature of Debezium’s connectors may lead to an overuse of resources, especially in scenarios where changes are not frequent or the data volume is low. Hence, while Debezium’s continuous monitoring feature is an asset in certain scenarios, it may be an overkill and resource drain in others.
For example, from Amazon MSK connect documentation:
Each MCU represents 1 vCPU of compute and 4 GiB of memory.
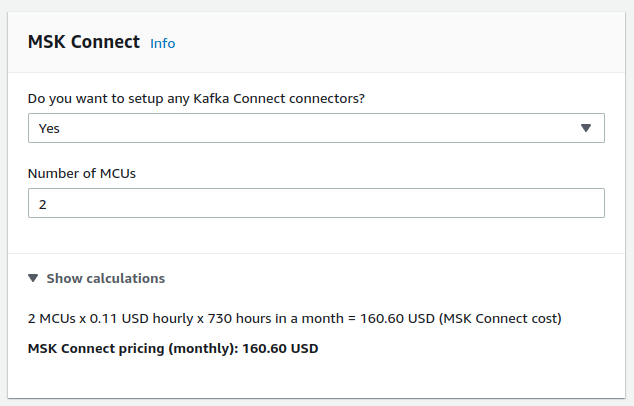
This lead to $160 for 1 source and 1 destination per month.
Chances are, in a complex deployment, a fair number of sources may not generate much traffic. It might only be a few rows per hour. For such a source, having a persistent, always-on process does not make much sense.
This situation can be exacerbated by your company ACLS. Because you do not want every user in your organization consuming the entirety of your dataset, you may need to define fine-grained role-based access control, and these rules, once applied, can necessitate numerous additional connectors (Kafka Connect), each requiring and competing for the same system resources.
In short, the same features that make Debezium’s performance in streaming / high volume scenarios can quickly become inefficient if the requirements are less stringent.
Kestra is designed to streamline the construction, execution, scheduling, and monitoring of complex data pipelines. workflows can be built in real-time, no matter how complex they are, and can connect to multiple resources as needed (including Debezium).
It offers batch or micro-batch processing capabilities, thereby scaling performance based on specific requirements from periodic updates to near-real-time scenarios. This adaptability optimizes resource usage, particularly when real-time performance isn’t required. Kestra’s Role in Resource Efficiency
When combined with Debezium, Kestra can offer a solution that uses resources precisely based on specific use cases. For example, a dashboard or KPI might only need to be refreshed once a day, or every few hours, for example. Whether it is cloud services or on-premises, resources cost money, and the challenge is to make the most efficient use of resources based on your requirements. Bandwidth, compute resources, or services based on throughput (such as BigQuery) are all expensive commodities, especially if they are always running.
If real-time performance is not necessary, then why waste money on resources you do not need? This approach avoids the application of resource-intensive streaming resources to every process. The result is an efficient solution that maximizes resource usage and saves money, while still ensuring comprehensive capture of all row-level changes.
Kestra is perfect for such situations and can scale performance up or down as needed from periodic updates to near-real-time scenarios. This functionality is possible due to the use of batch or micro-batch processing. Batch processing sends data at intervals, rather than in real-time. It is typically used when data freshness is not a mission-critical issue, and when you are working with large datasets and running complex algorithms that require a full dataset (sorting for example). Micro-batch processing is a similar process but on much smaller data sets, typically about a minute or so’s worth of data. This allows for near-real-time processing of datasets and is perfect for low-flow situations where a few minutes of delay is acceptable. In many cases, micro-batch processing and stream processing are used interchangeably in data architecture descriptions, because, depending on configuration, they can offer nearly the same performance.
A complex use case involving multiple data sources might have varying requirements, some real-time, some more forgiving. For these, a hybrid solution might be advisable. Debezium can be used (with the Kafka Connect service) for those streams that require real-time CDC. For near-real-time or batch processing, you can leverage Kestra. Kestra can consume events directly (without configuring a Kafka Connect service) by leveraging Debezium Engine and forward to any destination supported by Kestra (BigQuery, JDBC, Cloud Storage, and more), without a streaming pipeline. Changes/transfers can be scheduled for any interval, every 5 minutes, every hour, every day, whatever is required. Triggers can also be used to create an execution whenever there is data available. Kestra can also be leveraged to transform data before sending it to the destination.
Debezium leverages Kafka and Kafka Connect to deliver streaming performance, and the larger and more complex the deployment, the more challenging it can be to deliver enterprise-grade 99.9% availability while still managing resources and costs. Managing it in the cloud can be even more challenging. This involves picking the appropriate compute instance for the brokers, sizing the non-ephemeral storage accordingly, applying end-to-end security, ensuring high availability across availability zones, and more. These same challenges apply when Kafka is a component of another service as well - there is a reason that many organizations turn to managed services rather than deploying their own instance on-premise. There are challenges to visibility as well - users must be familiar with Kafka eccentricities to troubleshoot issues via logs and dashboards.
Kestra also allows for iterative changes to pipelines without causing disruptions. For example, a new pipeline can be added in minutes with a few lines of YAML code. Here is an example:
id: debezium-mysqlnamespace: company.team
tasks: - id: capture type: io.kestra.plugin.debezium.mysql.Capture hostname: 192.168.0.1 maxDuration: "PT1M" password: mysql_passwd username: root - id: fileTransform type: io.kestra.plugin.scripts.nashorn.FileTransform from: "{{ outputs.capture.uris.users }}" script: | if (row['contactName']) { row['contactName'] = "*".repeat(row['contactName'].length); } - id: jsonWriter type: io.kestra.plugin.serdes.json.IonToJson from: "{{ outputs.fileTransform.uri }}" - id: load type: io.kestra.plugin.gcp.bigquery.Load destinationTable: my-project.demo.users format: JSON from: "{{outputs.jsonWriter.uri }}" writeDisposition: WRITE_APPENDThis code snippet demonstrates how Kestra uses YAML to manage data pipelines. It captures changes from a MySQL database, transforms the data, writes it into JSON format, and then loads it into a BigQuery table.
Kestra’s flexibility and versatility, underlined by its extensive range of plugins, makes it an ideal tool for creating complex workflows with deep integrations with multiple systems. For systems without existing plugins, Kestra’s compatibility with containers such as Docker and Kubernetes makes integration straightforward.
Kestra’s Debezium plugins include connectors for Postgres and MySQL, PostgreSQL, Oracle, SQL Server, and more. The ongoing development aims to continually improve and expand the product’s capabilities.
by integrating Kestra and Debezium, you can leverage the strengths of both tools to create a more efficient and cost-effective solution for data pipeline management. This hybrid solution is adaptable to various requirements, ensuring the most efficient use of resources and providing a robust platform for complex data pipeline workflows.
Join the Slack community if you have any questions or need assistance.
Be sure to follow us on Twitter for the latest news. And if you love what we do, give a star on our GitHub repository.

Stay up to date with the latest features and changes to Kestra