Authors
Ludovic Dehon

Ludovic Dehon
A conversation about data pipelines is never complete without discussing ingestion practices: ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform). While they appear similar, the difference lies in the order and location of the Transform phase. Choosing between ETL and ELT involves considerations of data complexity, data warehousing technologies, and the requirements of data projects. But, what if you didn’t have to choose and could leverage both using Kestra?
Each practice is rooted in strong business needs, and are necessary parts of modern data flow practices. Discussions about those practices are often couched in a competitive narrative, asking which one is better. You’ll find plenty of “ETL vs ELT” publications. However, there are strong reasons why both are seen in use today, and neither one is going away anytime soon. So in this article, we’ll cover these two methods, the reasons they are so often pitted against one another, the situations in which one or the other thrive, and why, with Kestra’s unique capabilities, you might want to consider a hybrid solution. Let’s get started, shall we?
ETL and ELT share the same stages but follow a different sequence:
Extract: Pulling source data from the original database or data source. With ETL, the data goes into a temporary staging area. With ELT, it goes immediately into a data lake storage system.
Transform: Changing the format/structure of the data to integrate with the target system.
Load: Inserting data into a data storage system. In ELT scenarios, raw/unstructured data is loaded, then transformed within the target system. In ETL, the raw data is transformed into structured data prior to reaching the target.
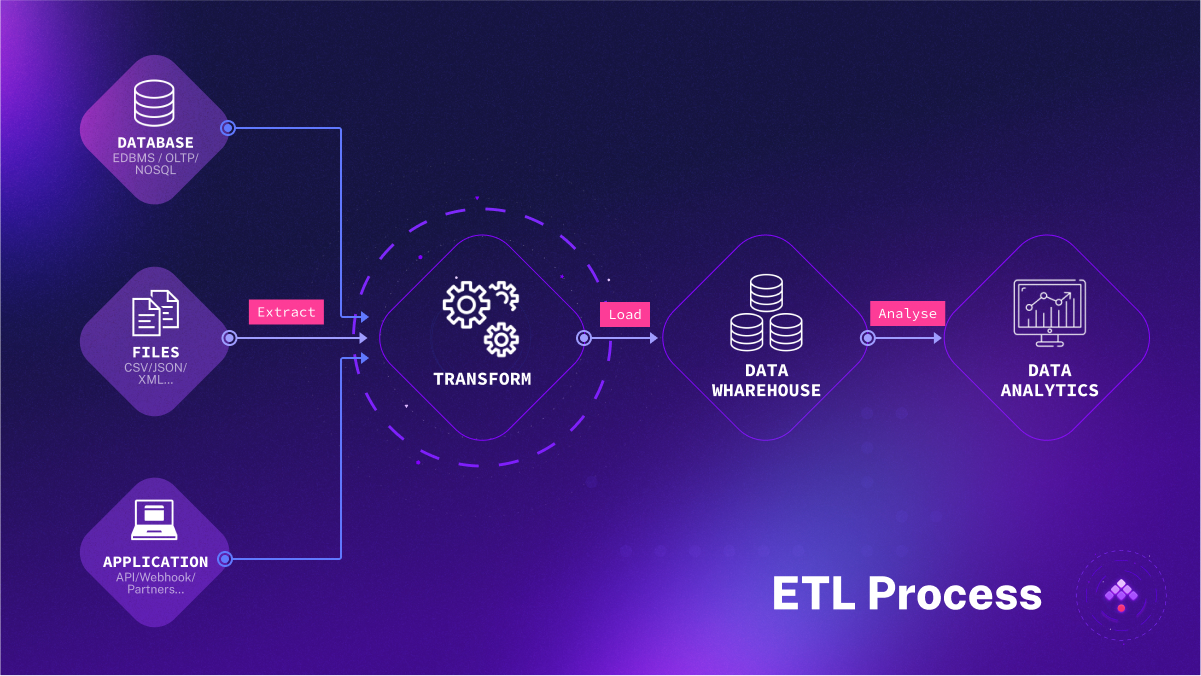
ETL surfaced in the 1970s. Born in an era of expensive storage, ETL transformed raw data into a usable format before delivery to the analytical system.
At that time, data centers were far from what we know today. Co-location facilities were scarce, and for the concept of cloud computing, well… It was the 70’s! Large organizations maintained their own centralized data repositories, primarily because data storage, in contrast to modern standards, was exceptionally expensive.
The process of moving substantial amounts of data between systems was not only costly but also time-consuming. Therefore, simply storing raw, unprocessed data was inefficient and impractical. Recognizing these constraints, it became essential to transform raw data into a usable format before it reached the systems intended for data analysis. This is where ETL came into play, ensuring that the data was not only usable but also in an optimal format for the system to which it was delivered.
Today, ETL finds use mainly in on-premise solutions where processing power and/or memory is finite. Data is sorted and transformed before reaching the storage destination for analysis. Specialized ETL tools automate data gathering and processing tasks, contributing to the tool’s continued relevance.
Originally, the ETL process was often coded by hand to collect data from relational databases. Now there are specialized tools for ETL that can gather and process data from multiple sources and automate these operations. Some common tools used in this space include Oracle Data Integrator, Talend, and Pentaho Data Integration, among many others.
Implementing ETL today offers several compelling advantages:
Technology Debt/Investment: Your organization might already have significant investments in infrastructures that demand data in specific formats. The raw data your organization collects may also serve a highly particular purpose, with its received format playing a crucial role in internal processes. Modern ETL solutions have significantly improved in terms of speed and ease-of-use, reducing the urgency for organizations to shift away from their existing structures.
Consistent Processes & Defined Workflows: ETL commences by extracting data from diverse homogeneous or heterogeneous data sources. It then relocates this data to a staging area for cleansing, enrichment, and transformation. Eventually, the data finds its way to a data warehouse for storage. This systematic approach to data handling results in clean, well-structured data that’s instrumental for seamless workflows.
Regulatory Compliance: ETL becomes particularly significant in scenarios where regulations mandate restrictions on data storage, especially unencrypted data, outside specific regions or countries. Businesses adhering to protocols like GDPR, HIPAA, or CCPA often need to employ data field removal, masking, or encryption. ETL processes offer a secure way to accomplish these operations since they transform potentially sensitive data before loading it, unlike ELT. With ELT, raw data is loaded first, making it available in logs accessible to system administrators. This could lead to GDPR compliance violations, as non-compliant data might cross EU borders before it’s secured in a data lake or equivalent storage medium.
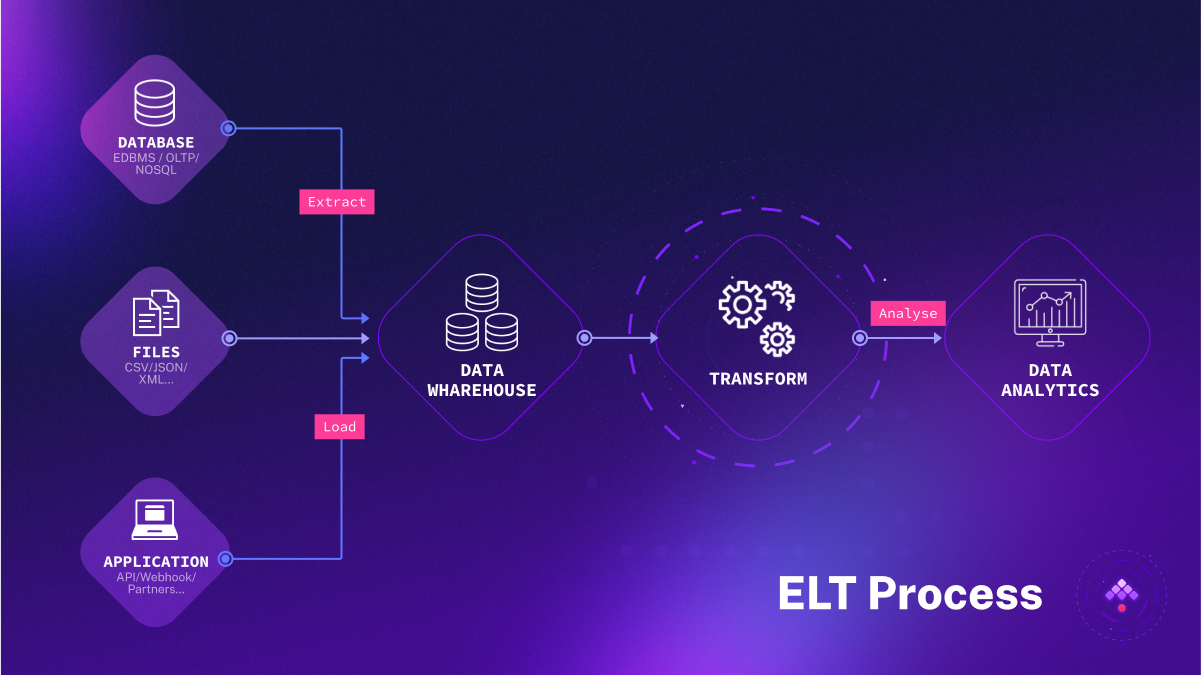
The advent of cheaper storage and cloud advances led to the emergence of ELT in the past decade. ELT eliminates the need for data staging and can handle any data type, unstructured, structured, semi-structured, or even raw data. This flexibility is key to its strong adoption in modern solutions, particularly when large datasets and streaming are involved.
The ELT process is particularly suited to data lakes. Data Lakes are large repositories that are data agnostic, in other words, capable of storing data in any and all formats. Because of this, it can be far more efficient to avoid the bottleneck of a staging area capable of handling a comparatively limited dataset.
The ELT process, characterized by its adaptability and streamlined operations, provides several significant benefits:
Reduced maintenance: ELT leverages existing database resources for data transformation, providing a wide array of readily available options. This inherent efficiency translates into less maintenance and a more streamlined workflow.
Accelerated Data Loading: As ELT does not necessitate data transformation prior to loading, it facilitates quicker ingestion. This lack of an intermediate transformation step effectively eliminates potential bottlenecks, accelerating the overall process.
On-Demand Transformation: One key feature of ELT is its “transform as needed” approach. Data can be transformed post-loading, and more importantly, it isn’t mandated to be immediately transformed. The transformation can be performed as and when it is required for a specific purpose, providing an added layer of flexibility.
High Data Availability: With ELT, the data, once loaded, remains consistently accessible. This continuous availability is advantageous for utilizing a range of tools, regardless of whether they work with unstructured or structured data, broadening the scope for data exploration and analysis.
ELT democratizes data gathering processes, because the source can equally be anything. Just as the target (usually a data lake or large scale database) should be able to handle any type of data, the sources can be equally disparate. This is important for modern workloads, because modern use cases stream data from IoT sources, raw data, video, documents, files, and more. This is not to mention multi-cloud processes. Sometimes data integrations occur across organizations, across different cloud platforms, across regions. Flexibility is key to making these modern processes work. ETL processes simply cannot handle the volume, nor the variances involved. Certainly not in a real-time scenario.
A primary drawback of ELT is that it can expose raw, unencrypted data during the initial loading phase. This stems from the process structure, where transformation occurs after loading the data into the target system. The implication is that the raw data can be accessible at any time before the transformation is completed. This vulnerability poses a significant risk to the security of data.
In the digital age, data often crosses international borders, making adherence to regional and global data protection regulations crucial. In many instances, encryption is not just a preferred practice—it’s a mandated requirement. Given ELT’s sequence, with transformation occurring after loading, there is a risk of exposing unencrypted data. This exposure could potentially result in compliance violations, creating another hurdle in the ELT process.
Attempting to rectify the aforementioned issues by deleting the raw data comes with its own set of problems. Data deletion processes, especially when dealing with large volumes of information, can be unreliable and prone to crashes. This could be particularly problematic when handling sensitive data, such as hospital records or financial details.
Many data warehouses lack robust transaction support, which is necessary for ensuring the successful execution of data deletion queries. Without this support, there is a risk of failed deletion, adding another layer of complexity and potential security risk to the ELT process.
ETL processes were conceived in an era where data was not as voluminous as it is today. With the advent of big data, the ETL model can struggle to efficiently handle large data volumes. Similarly, the proliferation of disparate data types and sources – IoT devices, social media feeds, cloud platforms, and so forth – challenges the traditional ETL structure, which can be ill-suited to handle such diversity in real-time.
ETL processes typically require a significant amount of processing power and memory to carry out transformations before loading the data. In scenarios where computational resources are limited, this can present a constraint. This is particularly evident in legacy systems or on-premise solutions where upgrading infrastructure might be cost-prohibitive.
ETL’s linear and rigid workflow can be a drawback in environments that require more flexibility. With ETL, any alterations or changes in business requirements often necessitate modifications in the ETL process, which can be time-consuming and potentially disruptive to business operations.
ETL operations often require the use of specialized tools and can demand specific expertise to build and maintain ETL pipelines. This can potentially create a bottleneck in operations, as a shortage of trained personnel on the given platform can slow down or halt the creation of new data pipelines.
Whether you need ETL or ELT processes in your solution, Kestra can manage both in the same solution, handling even the most complex workflows. ETL processes can be used to scrub sensitive data, ensuring compliance, loading the transformed data within a temporary table. With Kestra’s capacity for parallel flows, the rest of the data can be handled by ELT.
Kestra is able to perform ELT workloads on its own or with integrations to many popular solutions. It can handle loading data from BigQuery, CopyIn, Postgres, and more. A simple query can be performed to move the data, for example, SQL INSERT INTO SELECT statements. Dependencies between flows can be handled with Kestra’s trigger mechanisms to transform the data within the database (cloud or physical).
ETL is just as easily managed by Kestra’s flexible workflows. FileTransform plugins are one possible method. You can write a simple Python/Javascript/Groovy script to transform an extracted dataset data row per row. For example, you can remove columns with personal data, clean columns by removing dates, and more. Integrating a custom docker image into your workflow is another method that can be used to transform the data. Not only can you transform data row per row, you can potentially handle conversion of data between formats, for example, transforming AVRO data to JSON or CSV, or vice versa.
id: my-first-flownamespace: company.teaminputs: - id: uploaded type: FILEtasks: - id: csvReader type: io.kestra.plugin.serdes.csv.CsvToIon from: "{{ inputs.uploaded }}" - id: fileTransform type: io.kestra.plugin.scripts.nashorn.FileTransform description: This task will anonymize the contactName with a custom nashorn script (javascript over jvm). This show that you able to handle custom transformation or remapping in the ETL way from: "{{ outputs.csvReader.uri }}" script: | if (row['contactName']) { row['contactName'] = "*".repeat(row['contactName'].length); }This is not usually possible with most solutions. Most ELT tools often prevent ETL processes by design because they cannot handle heavy transform operations. Kestra is able to handle both because all transformations are considered to be row per row, and therefore do not use any memory to perform the function, only CPU.
With Kestra’s innate flexibility, and many integrations, you are not locked into the choice of one ingestion method or the other. Complex workflows can be developed, whether in parallel or sequentially, to deliver both ELT and ETL processes. Simple descriptive yaml is used to connect plugins, and to create flows. Because workflows created in Kestra are represented visually, and issues can be seen in relation to individual tasks, there is no need to fear complexity. Trouble can be traced to its source in an instant, allowing you to try new things and come up with a new solution without fear.
Join the Slack community if you have any questions or need assistance. Follow us on Twitter for the latest news. Check the code in our GitHub repository and give us a star if you like the project.

Stay up to date with the latest features and changes to Kestra