Authors
Ludovic Dehon

Ludovic Dehon
When we have launch Kestra officially few month ago, we wanted to have the most complete, reliable, scalable product to show you. We are really proud to have the first cloud native orchestration & scheduling platform running only with technologies like Kafka and ElasticSearch. Theses bring an architecture with no single point of failure and high throughput in order to scale to millions of executions without the pain.
Since this is pretty cool, not everyone is Uber, LinkedIn, (add any another big tech startup) that need to have these hard requirements of scalability, and we see some comments about the product that ElasticSearch or Kafka can be a pain to manage. In fact, we already know that, but we don’t even think that this one can a stopper.
We have interview many people on our slack community, twitter, … also that confirm us that the stack can be a real blocker for small company as they are afraid of managing a full cluster.
For now, we continue to think a high-availability solution is a must-have, a solution that can ensure you that if your needs increase, you will have a solution to scale without having to do without the features. So we decide to create a new version of Kestra (in Beta for now) that will work for a Medium-sized environment.
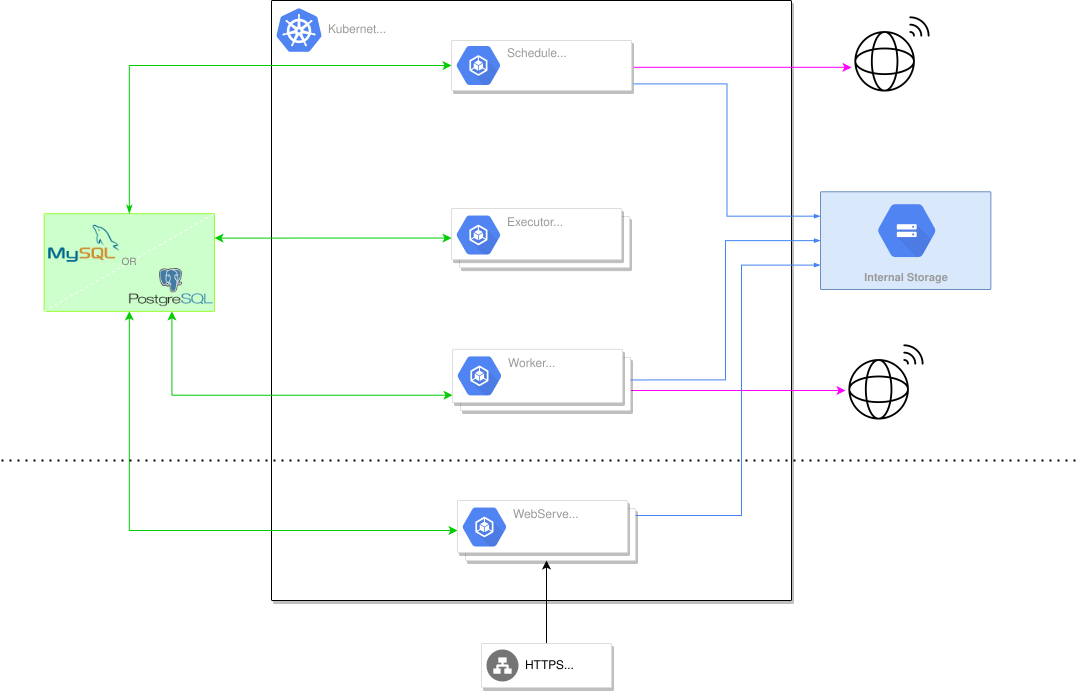
The solution is to remove the dependencies of Kafka & ElasticSearch and to allow to replace them with a simple MySQL of Postgres database for the both of them.
Since MySQL or Postgres are largely common, people are not feared of hosting these services. In general, multiple instances are already running on your company. Moreover, the most cloud provider can offer you this as managed service, or you can easily find one provider handling that.
The new version is possible since Kestra thought since its inception as pluggable architecture, and we only need to implement a new repository and a new queue.

We have worked harder to be able to have the more fluent change using a database, but we have made some tradeoffs for now (maybe you can go deeper depending on your feedback for a certain point).
Here is some tradeoff now:
All the other features are the same!
Since we have implemented MySQL and Postgres, and java has a strong abstraction of database (with JDBC and JOOQ), we are also able to bring you the last version with no database at all.
This implementation relies on an H2 database that is an in-memory database or file-based one. To illustrate this, just grab the executable from Kestra, install java 11+ and start the server with:
# unix or macos./kestra server local
## windowsrename kestra-0.5.0 kestra-0.5.0.cmdkestra.cmd server localGo to the UI on http://localhost:8080, you are up and running. This one is suitable for the development environment and will allow all your developer to have a running version of Kestra without any painful setup.
Please go here for the full getting started for local server.
For this implementation, just note that you will need to have a docker daemon running to be able to use Bash or Python with runner: DOCKER. A special warning for Windows users, since Kestra was thought to be deployed on a Linux server, but our primer test seems to be nice and functional.
This feature needs a large refactoring of Kestra to remove some assumptions (for example, we used Lucene query of ElasticSearch on the whole UI). So we have released a new BETA version 0.5.0-BETA to gather the much feedback as possible and to be sure to avoid bugs introduce by this major version. Please go ahead, test it and send as much feedback as possible.
We hope that will enjoy this new feature and that you will imagine more use cases with Kestra, stay connected and follow us on GitHub, Twitter, or Slack.

Stay up to date with the latest features and changes to Kestra