Authors
Ludovic Dehon
Ludovic Dehon
Snowflake is one of the most popular cloud data warehouse technologies. This post demonstrates Kestra plugins for Snowflake data management, including event-driven triggers based on changes in your Snowflake data, file management, and queries.
With Snowflake, companies can build scalable data workloads that can perform strong data analysis on structured, unstructured, and semi-structured data to derive valuable business insights and make data-driven decisions. Additionally, Snowflake Data Marketplace allows customers to access numerous ready-to-query datasets, further reducing integration costs.
Snowflake can automatically manage its multi-cluster warehouses, dynamically scaling up and down to balance resource usage and costs.
The platform enables organizations to avoid large-scale licensing costs commonly associated with data warehousing tools, operating on a pay-as-you-go basis for storage and compute.

Data warehouse workloads are typically part of a larger technological stack. To streamline operations, orchestration, and scheduling of data pipelines are crucial. This is where Kestra comes into play.
Kestra is designed to orchestrate and schedule scalable data workflows, thereby enhancing DataOps teams’ productivity. It can construct, operate, manage, and monitor a variety of complex workflows sequentially or in parallel.
Kestra can execute workflows based on event-based, time-based, and API-based scheduling, giving complete control. Snowflake already offers many cost optimization processes like data compression and auto-scaling. However, Kestra makes it simpler to download, upload, and query data by integrating with Snowflake’s storage and compute resources.
Besides the Snowflake plugin, Kestra offers numerous JDBC plugin integrations, including ClickHouse, DuckDb, MySQL, Oracle, Apache Pinot, PostgreSQL, Redshift, SQL Server, Trino, Vectorwise, and Vertica. These plugins can effectively process and transform tabular data within relational databases, reducing the processing cost of platforms like Snowflake.
Kestra’s Snowflake plugin provides an efficient solution for creating intricate data pipelines. You can perform the download, upload, and query tasks. Let’s dive into the key functionalities provided by the plugin.
Kestra can query the Snowflake server using this task to insert, update, and delete data. The Query task offers numerous properties, including auto-committing SQL statements, different fetching operations, specifying access-control roles, and storing fetch results. When the storevalue is true, Kestra allows storage of large results as an output of the Query task.
The plugin allows the usage of multi-SQL statements in the same transaction as a full SQL script with isolation support. It allows simple queries and fetches results with fetch or fetchOne properties, enabling teams to reuse the output on the next tasks from tools like Kafka Consume, Elastic Search, Mongo Find, and more. Some Query task instances are:
The following code snippet executes a query to fetch results from one table into Kestra internal storage.
id: selecttype: io.kestra.plugin.jdbc.snowflake.Queryurl: jdbc:snowflake://<account_identifier>.snowflakecomputing.comusername: snowflakepassword: snowflake_passwdsql: select * from sourcefetchType: FETCHThis task downloads data from the Snowflake server to an internal Kestra stage which is based on Amazon ION. The Download task provides the URL of the downloaded file available on the Kestra storage server. The Download task offers properties such as data compression and access control role to streamline the download process of the connected database.
The following code snippet downloads the default database to the specified fileName location on the internal Kestra server.
id: downloadtype: io.kestra.plugin.jdbc.snowflake.DownloadstageName: MYSTAGEfileName: prefix/destFile.csvThis task uploads data to an internal Snowflake stage. Similar to Download task, Upload can perform data compression and set access control role. Snowflake also support data transformation while loading data, which simplifies the ETL process.
The following code snippet uploads data to the specified fileName location.
id: uploadtype: io.kestra.plugin.jdbc.snowflake.UploadstageName: MYSTAGEprefix: testUploadStreamfileName: destFile.csvWith its rich set of features, Kestra’s Snowflake plugin offers you the ability to build highly customizable and robust data pipelines:
id: conditional_selecttype: io.kestra.plugin.jdbc.snowflake.Queryurl: jdbc:snowflake://<account_identifier>.snowflakecomputing.comusername: snowflakepassword: snowflake_passwdsql: SELECT * FROM source WHERE id > 1000fetchType: FETCHid: trigger_on_updatetype: io.kestra.plugin.jdbc.snowflake.triggerurl: jdbc:snowflake://<account_identifier>.snowflakecomputing.comusername: snowflakepassword: snowflake_passwdsql: SELECT MAX(updated_at) FROM sourceinterval: PT1MfetchType: FETCHid: selective_downloadtype: io.kestra.plugin.jdbc.snowflake.DownloadstageName: MYSTAGEsql: SELECT column1, column2 FROM sourcefileName: destFile.csvid: transformed_uploadtype: io.kestra.plugin.jdbc.snowflake.UploadstageName: MYSTAGEprefix: transformedDatafileName: destFile.csvfileFormat: (type = 'CSV', field_delimiter = ',', skip_header = 1, NULL_IF = ('\\N'))Kestra provides flexibility and control to data teams, it can orchestrate any kind of workflow with ease using the rich UI that monitors all flows.
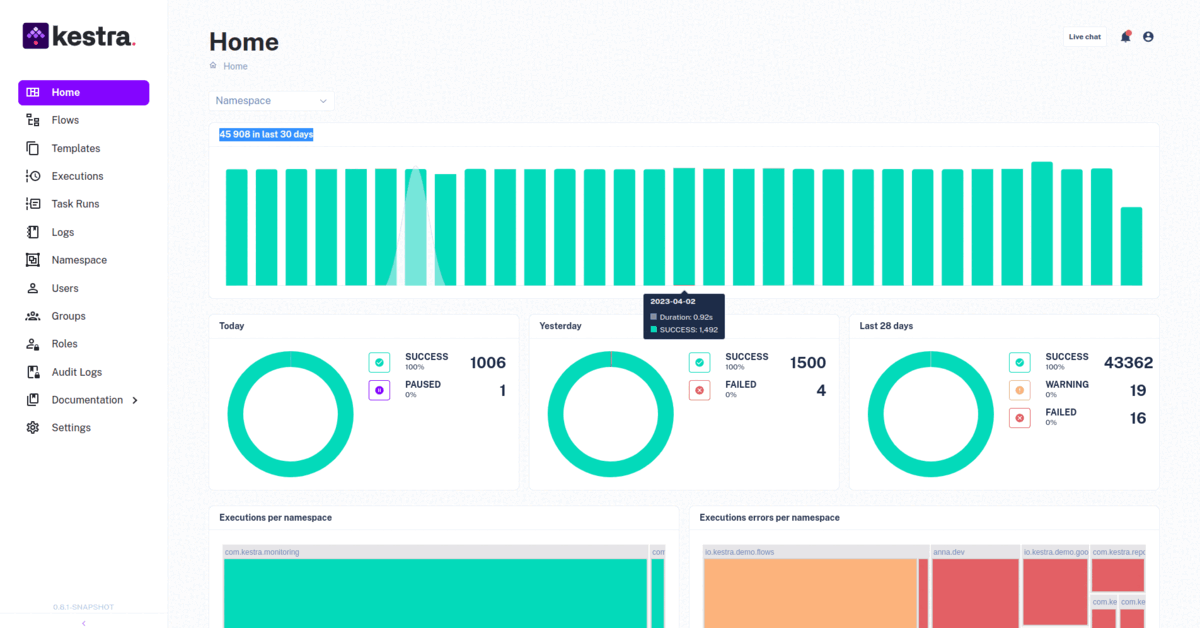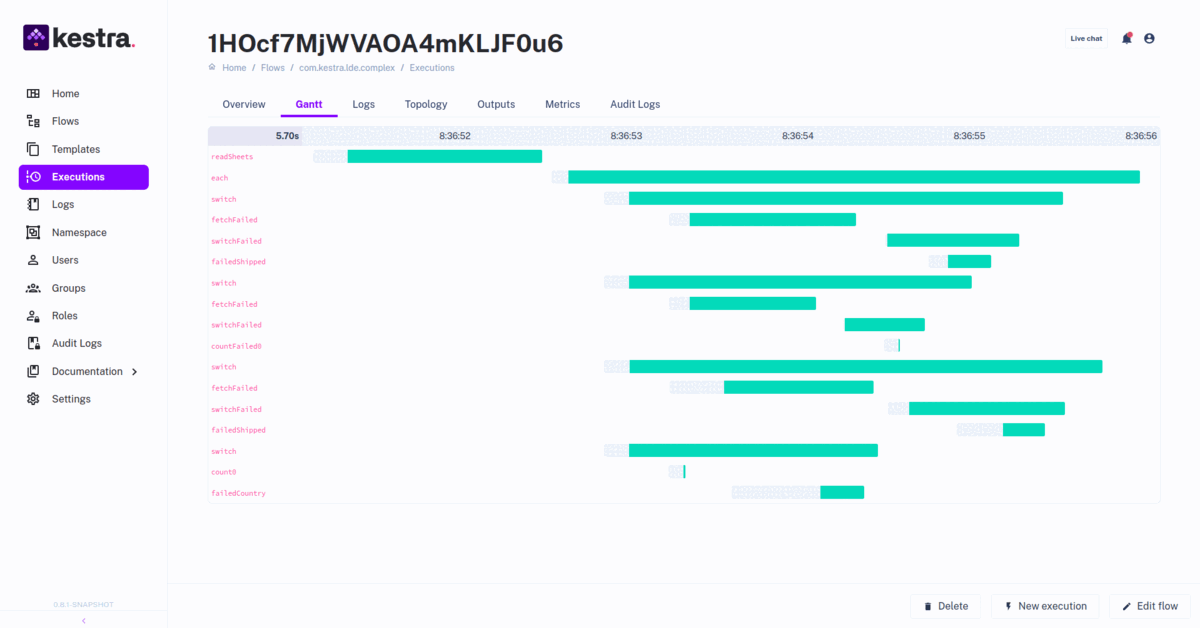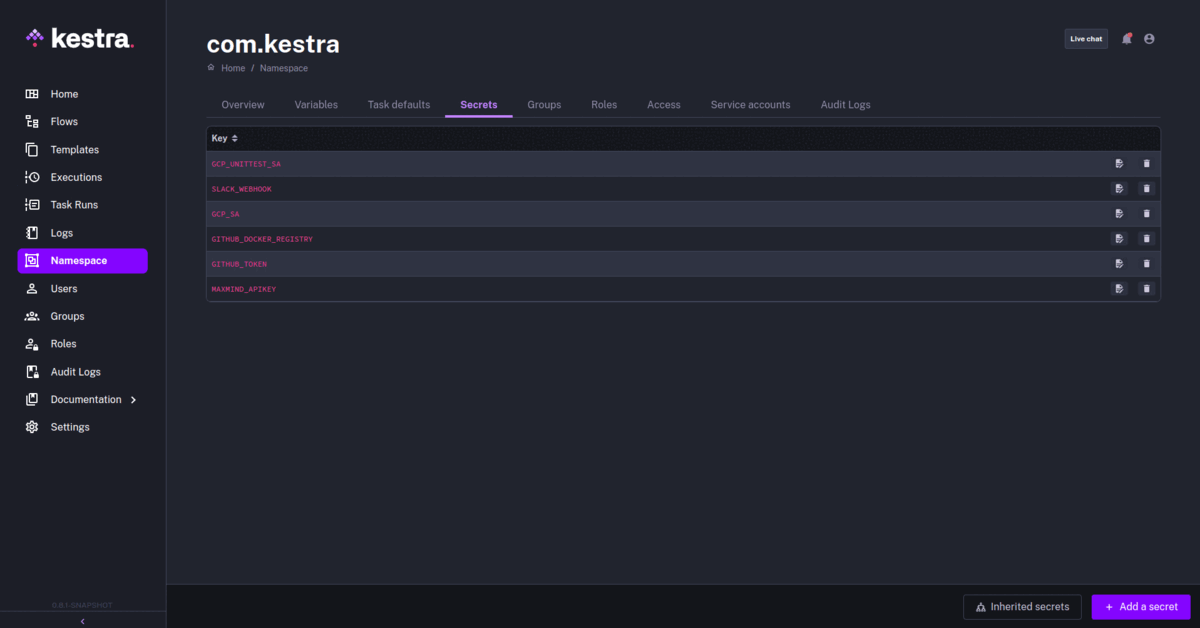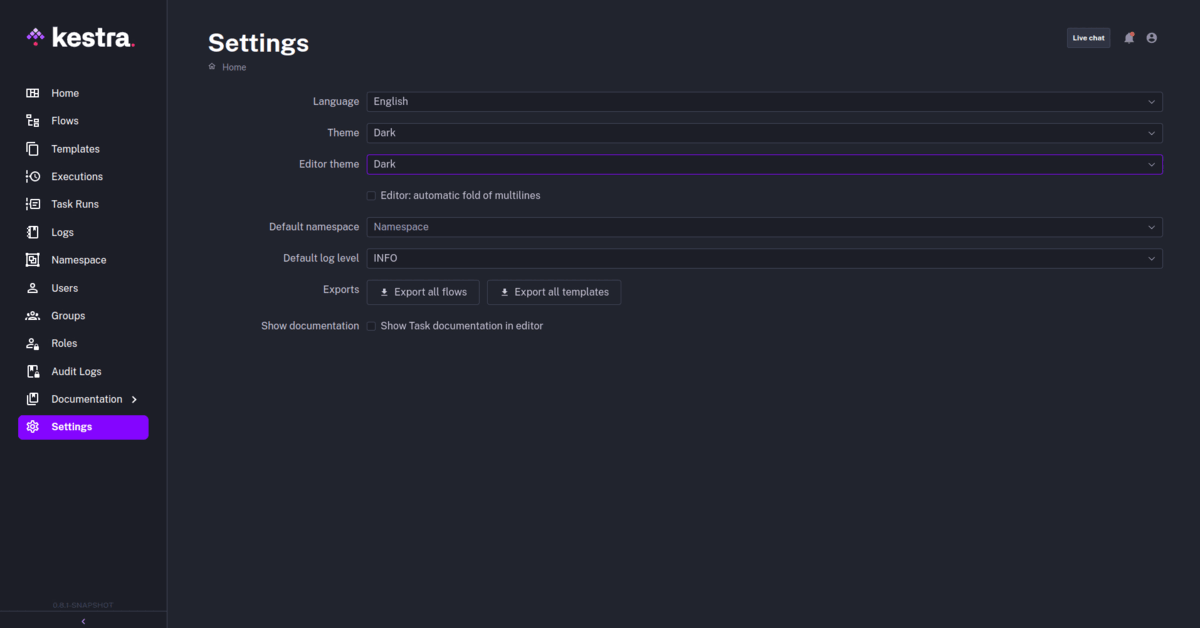
Kestra’s Snowflake plugin makes data warehousing simple even for non-developers thanks to YAML. Your Snowflake storage pipeline can accommodates raw data from multiple sources and transforms it using ETL operations. Additionally, you can skip the transformation and directly load data into the warehouse using the ELT pipeline. Kestra can manage both workflows simultaneously. In any case, Kestra ensures that the data is readily available to perform analysis and learn valuable patterns.
Join the Slack community if you have any questions or need assistance. Follow us on Twitter for the latest news. Check the code in our GitHub repository and give us a star if you like the project.

Stay up to date with the latest features and changes to Kestra