Authors
Ludovic Dehon
Ludovic Dehon
This blog post dives into Kestra’s integrations for Google Cloud Platform (GCP), focusing on BigQuery operations. It demonstrates how to automate repetitive processes and create resilient workflows within the GCP environment using Kestra’s orchestration capabilities.
Google Cloud Platform (GCP) is one of the major cloud providers. BigQuery is GCP’s serverless data warehouse. It’s typically leveraged for storing and analyzing large datasets, including use cases such as:
gcloud CLI to analyze data stored in BigQuery using various programming languages.You can see that BigQuery offers a wide range of functionality out of the box. However, sometimes you may need to integrate additional data sources, custom scripts, or react to external events. That’s where Kestra can help.
Kestra provides a suite of plugins for various GCP services, such as Google Cloud Storage (GCS), BigQuery, VertexAI, and more. The plugins for BigQuery, in particular, make it easy to connect BigQuery data to external services beyond the boundaries of GCP.
Kestra enables standard operations in BigQuery, such as creating and deleting datasets and tables, running queries, and importing/exporting tables to/from BigQuery and GCS, and many more, using simple plugins.
Data modeling is a process that involves setting up a coherent structure for data to make it useful for a business, reflecting the organization’s goals and business logic. It’s about organizing, standardizing, and understanding the data related to business processes, workflows, and definitions. This is achieved through a series of transformations applied to the raw datasets, with the final data used for visualization, analysis, or machine learning. Kestra’s Query plugin for BigQuery can be used for this purpose.
For instance, you can apply complex aggregation on daily sales report data and use those data points in subsequent phases of transformations for gathering the daily sales trends.
Here’s an illustrative flow that implements data modeling on daily sales data and calculates average sales for each product category. This flow is triggered daily and executes several BigQuery queries to transform and aggregate raw sales data:
id: modelizationnamespace: company.teamdescription: This flow aggregates daily sales data and calculates average sales for each product category.tasks: - id: aggregate-sales type: io.kestra.plugin.gcp.bigquery.Query projectId: your-gcp-project-id destinationTable: your-project.your-dataset.sales_agg writeDisposition: WRITE_TRUNCATE sql: | SELECT DATE(timestamp) AS date, product_category, COUNT(*) as sales_count FROM `your-project.your-dataset.sales_raw` GROUP BY date, product_category
- id: calculate-average-sales type: io.kestra.plugin.gcp.bigquery.Query projectId: your-gcp-project-id destinationTable: your-project.your-dataset.sales_avg writeDisposition: WRITE_TRUNCATE sql: | SELECT date, product_category, AVG(sales_count) as avg_sales FROM `your-project.your-dataset.sales_avg` GROUP BY date, product_category
- id: query_latest_date type: io.kestra.plugin.gcp.bigquery.Query projectId: your-gcp-project-id fetchOne: true sql: | SELECT MAX(added_date) AS date FROM `kestra-dev.ETL_demo.raw_data`
- id: query_new_data type: io.kestra.plugin.gcp.bigquery.Query projectId: your-gcp-project-id destinationTable: your-project.your-dataset.sales_avg writeDisposition: WRITE_APPEND sql: | SELECT * FROM `kestra-dev.ETL_demo.source` WHERE added_date > date('{{ outputs.query_latest_date.row.date }}')
triggers: - id: schedule type: io.kestra.plugin.core.trigger.Schedule cron: "0 0 * * *"Here we have four tasks, each executing a query within a BigQuery cloud data warehouse.
Task 1 - aggregate-sales: This task aggregates the sales data by date and product category. The aggregated data is then written to a new BigQuery table sales_agg.
Task 2 - calculate-average-sales: This task calculates the average sales for each product category and date, and writes this data to another BigQuery table sales_avg.
Task 3 - query_latest_date: This task queries the latest date from the raw data table. The fetchOne: true option indicates that we’re only interested in the first row of the result.
Task 4 - query_new_data: This task selects the new data from the source table that was added after the latest date fetched in the previous task. The data is then appended to the sales_avg table.
Triggers are events that start the execution of the flow. Here, a Schedule trigger is used, which triggers the flow based on a cron expression, allowing you to automate the execution of the data pipeline. In this case, the pipeline is run daily at midnight (0
).This is used to run SQL queries on BigQuery tables. It’s used for data transformation and aggregation in our tasks. fetchOne: true is used when we want the first row of the query result, and destinationTable is used to specify the table where we want to write our query results.
This option controls the behavior when writing query results to a table that already exists. WRITE_TRUNCATE will delete all rows in the table before writing the results, while WRITE_APPEND will add the results to the existing table content.
Kestra supports the use of template variables, which are denoted by {{ }}. In the query_new_data task, date(’{{ outputs.query_latest_date.row.date }}’) fetches the output date from the query_latest_date task and uses it in the SQL query.
The LoadFromGcs plugin is used to import the data from GCS and store it in the BigQuery table directly. This can be especially helpful to analyse and generate insights from the static data files stored in GCS. This plugin can take the input data files for various file formats like Avro, JSON, PARQUET, ORC, and CSV.
Here is an example of a flow that load the data from GCS and store it in a BigQuery table with specified inputs.
- id: load_from_gcs type: io.kestra.plugin.gcp.bigquery.LoadFromGcs destinationTable: ETL_demo.raw_data ignoreUnknownValues: true schema: fields: - name: Survived type: STRING - name: Sex type: STRING - name: Age type: STRING format: CSV csvOptions: allowJaggedRows: true encoding: UTF-8 fieldDelimiter: "," from: - gs://sandbox-kestra-dev/sandbox/titanic.csvOn the other side, the ExportToGCS plugin is designed to extract tables from BigQuery and store them at a specified GCS bucket path. This comes in handy when a BigQuery table is needed for utilization in other services or platforms, like creating backups to save on BigQuery storage costs or generating a dataset for ML model training.
Here’s an example of a flow that allows exporting data back to GCS:
id: export_to_gcstype: io.kestra.plugin.gcp.bigquery.ExtractToGcsdestinationUris: - gs://sandbox-kestra-dev/sandbox/{{ inputs.destinationFile }}.csvsourceTable: kestra-dev.ETL_demo.analysis_dataformat: CSVfieldDelimiter: ;printHeader: trueInputs for flow execution in Kestra can be provided either via the UI or when executing the flow via an API call, for example using the curl command. Here is an example curl command that you can use to execute the flow from other applications:
inputs: - id: destinationFile type: STRING required: trueThe CURL command (complete API) can also be used to trigger the flow if you need to automatize the execution from another application. Here is a sample CURL for such a use case.
curl -v "http://localhost:8080/api/v1/executions/trigger/io.kestra.gcp/extract-to-gcs" -H "Transfer-Encoding:chunked" -H "Content-Type:multipart/form-data" -F destinationFile="analysis_data_18"The StorageWrite plugin is used for importing data from various sources, including databases, distributed message queues, or other plugins, into BigQuery. This is especially useful when data is stored externally. Another advantage of using this plugin is to avoid quotas limitation during streaming and batch data ingestion.
Below is an example flow that streams data from a Kafka topic to a BigQuery table using the Storage Write API from BigQuery:
tasks: - id: consume type: io.kestra.plugin.kafka.Consume topic: TRANSACTIONS-LOG-V1 properties: bootstrap.servers: "<CONFLUENT-URI>.gcp.confluent.cloud:9092" security.protocol: SASL_SSL sasl.mechanism: PLAIN sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="<USERNAME>" password="<PASSWORD>"; serdeProperties: schema.registry.url: https://<CONFLUENT-URI>.aws.confluent.cloud basic.auth.credentials.source: USER_INFO basic.auth.user.info: <USERNAME:PASSWORD> keyDeserializer: STRING valueDeserializer: AVRO - id: storage_write type: io.kestra.plugin.gcp.bigquery.StorageWrite bufferSize: 100 from: "{{ outputs.transform.uri }}" destinationTable: "kestra-dev.ETL_demo.transactions_logs"Kestra also allows you to create dynamic data pipelines that can be triggered based on external events. For example, your data pipeline might need to start when a new table is ingested into BigQuery, or when a file is uploaded into a Google Cloud Storage (GCS) bucket. Kestra supports such event-driven workflows via trigger plugins for BigQuery and GCS.
The BigQuery Trigger will check for new data in a specified BigQuery table and, when found, invoke a flow for each new row with loop (EachSequential task) (This has since been replaced by ForEach). Here’s how you could set up such a flow:
id: Trigger_flownamespace: company.teamrevision: 1tasks: - id: each type: io.kestra.plugin.core.flow.EachSequential tasks: - id: return type: io.kestra.plugin.core.debug.Return format: "{{taskrun.value}}" value: "{{ trigger.rows }}"triggers: - id: watch type: io.kestra.plugin.gcp.bigquery.Trigger interval: PT30S sql: SELECT * FROM `kestra-dev.ETL_demo.raw_data`In this YAML flow configuration, the io.kestra.plugin.gcp.bigquery.Trigger is set to watch a BigQuery table. When new rows are added to this table, it triggers the flow and executes a task for each row.
Similarly, Kestra can trigger a flow when a new file is uploaded to a specific GCS bucket. This flow could then, for example, move the uploaded file to an archive folder. Here’s a YAML example of such a flow:
id: gcs-listennamespace: company.teamtasks: - id: each type: io.kestra.plugin.core.flow.EachSequential tasks: - id: return type: io.kestra.plugin.core.debug.Return format: "{{taskrun.value}}" value: "{{ trigger.blobs | jq '[].uri' }}"triggers: - id: watch type: io.kestra.plugin.gcp.gcs.Trigger interval: "PT5M" from: gs://my-bucket/kestra/listen/ action: MOVE moveDirectory: gs://my-bucket/kestra/archive/This flow is triggered by the io.kestra.plugin.gcp.gcs.Trigger whenever a new file is uploaded to the specified GCS bucket. It then moves the new file to an archive directory.
With Kestra, the process of analyzing your flow (DAG) executions becomes intuitive and informative. Accessible through the “Execution” section, each execution instance is logged with specific details, such as its trigger source (manual or automated), as well as a unique Execution ID. This meticulously detailed record of each flow allows for comprehensive data lineage views encompassing Gantt charts, logs, topology, and outputs.
A key aspect of data lineage visualization is the Gantt chart, which provides a clear overview of the time taken for each task’s data processing within the flow. In parallel, the Topology feature enables the user to identify and debug the sequence of tasks along with their dependencies.
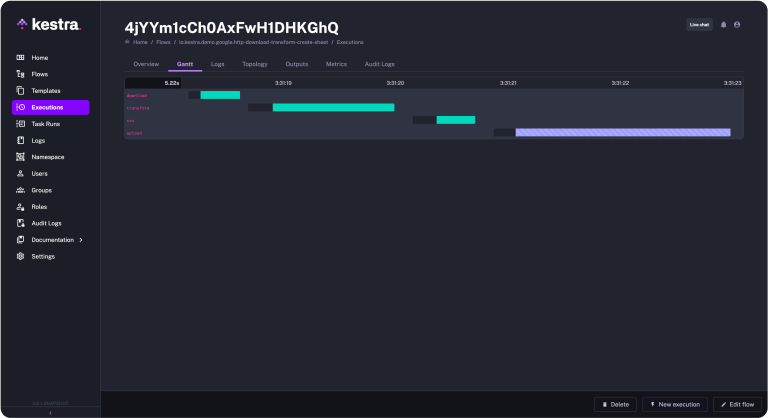
Accessing specific information about the flow is simple, requiring only the unique execution ID. This enables efficient data lineage tracking of the flow. You can leverage Kestra’s null variable to add any execution identifier to separate different executions in the flow. Furthermore, you can inject a null variable into SQL queries for enhanced data tracking.
If you would like to see more posts diving into GCP integrations or integrations with other cloud providers, let us know. We’d love to hear your feedback and the use cases you would like us to cover next.
Join the Slack community if you have any questions or need assistance. Follow us on Twitter for the latest news. Check the code in our GitHub repository and give us a star if you like the project.

Stay up to date with the latest features and changes to Kestra