
Authors
Ludovic Dehon
Ludovic Dehon
We’ve been super busy at Kestra over the last few months, making working with data much more delightful for you. We’ve done much work to elevate the developer experience and introduce powerful features to make Kestra the best data orchestration platform.
We are proud to present to you Kestra 0.7.0 🎉.
With this release, we improve flow validation and add an autocomplete features to write flows and templates more easily, we move from the Enterprise Edition to the Open Source Edition some useful pages to show dependencies and global information on your flow executions, we add mass action and export/import features, new plugins, and much more things.
Read the full post 😉
We added a Kestra guided tour in the UI. When there is no flow already created, a guided tour will introduce you to Kestra and flow’s main concepts.
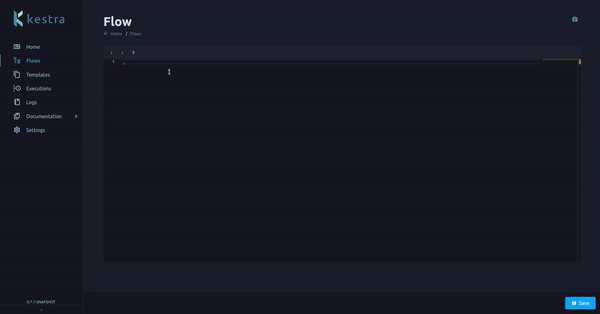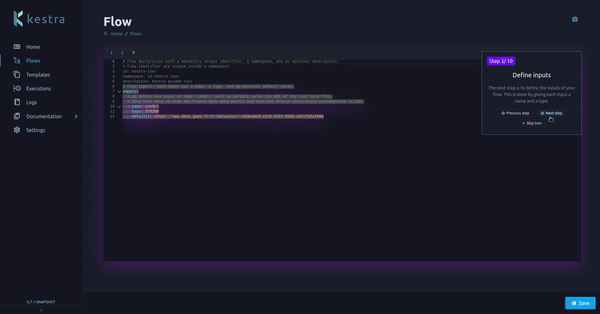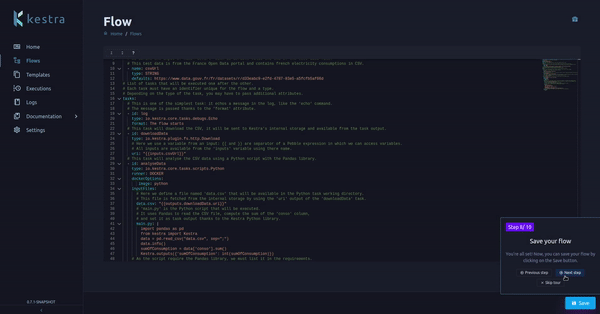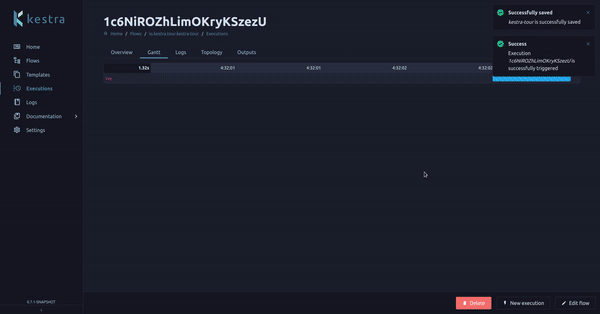
This guided tour can be re-run with the ? button as shown above.
Previously, when you create or edit your flow, we didn’t keep the flow YAML source in Kestra’s datastore but only an internal representation of the flow. This leads to formatting and comments not being kept as you intended.
We rework the way we store flow definitions in Kestra and now the exact same YAML that you wrote in the editor is kept so you can format it as you want, add spaces, add comments, reorder properties, …
When you create a flow, you must enter each task’s type and attributes. But task types are challenging to remember, they are Java fully qualified class names that can be quite long, and tasks can have multiple attributes!
On the flow editor, you can now use CTRL + Enter to get a suggestion of task types and attributes! This functionality was previously only available on the Enterprise Edition. We now move it from the Enterprise Edition to the Open Source Edition, making it available for everyone!
This works thanks to our validation based on a JSON Schema computed for each task. It will also underline errors like missing mandatory properties when you save your flows.
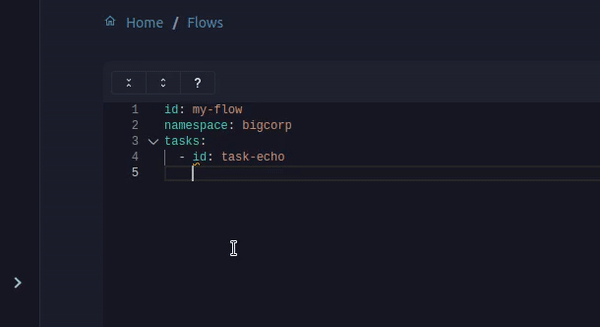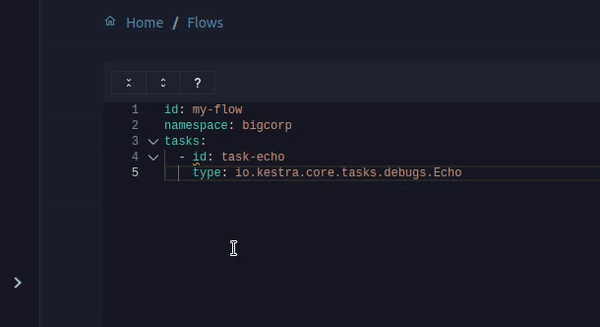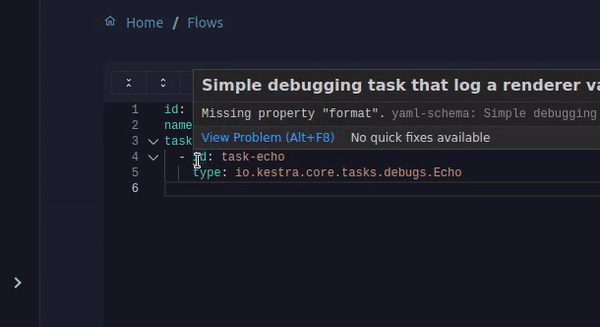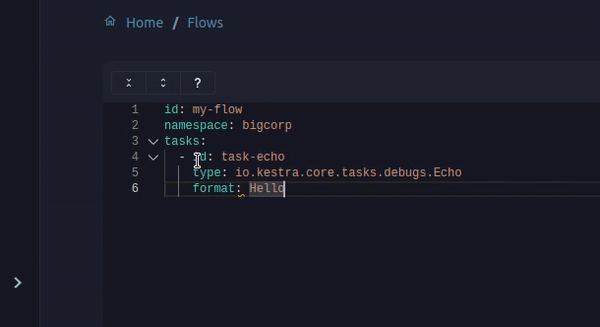
We have improved the flow validation in Kestra. Flows are now validated with Plugin Defaults, meaning no more issues when a mandatory field is set in plugin defaults and not directly in the flow definition.
Flow validation is also now performed in the editor before you save your flow so it is no more possible to create invalid flows and templates.
In Kestra, the number of flows you develop can grow quickly, and maintaining them can get challenging. CI/CD pipelines are a great way to automate your flows’ validation and deployment.
This was one of the most requested features by the Kestra community. Earlier, we only supported Terraform to manage your flow and templates definitions. We have now added support for GitHub Actions. Read more about how to use CI/CD with Kestra. This documentation page also provides an example GitLab CI/CD workflow using the Kestra CLI.
If you wonder how to get access to all the existing flows and templates of your running Kestra instance, we added an Export All button for flows and templates in the Settings page.
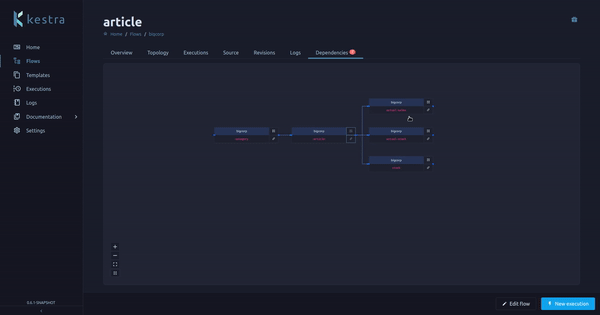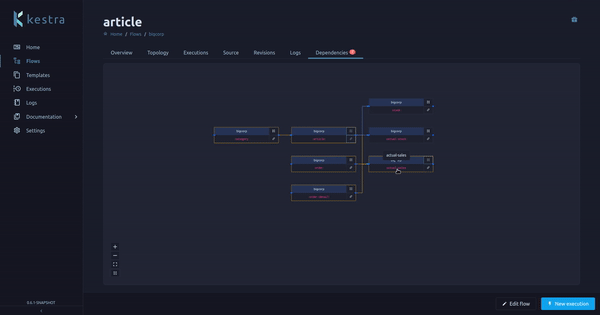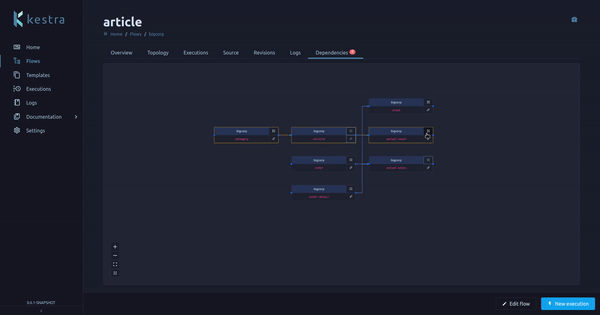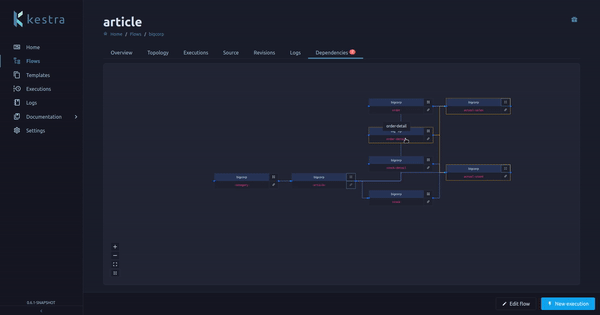
A flow can have one or multiple dependencies, a dependency is another flow that triggers this flow.
We had a flow page tab on the Enterprise Edition displaying these dependencies (and the dependencies of the dependencies, recursively). We now moved this tab from the Enterprise Edition to the Open Source Edition, making it available for everyone!
You can have a lot of flows and executions in your Kestra instances. Until now, actions on flows or executions could only be done one by one. That made it challenging to manage a large number of resources.
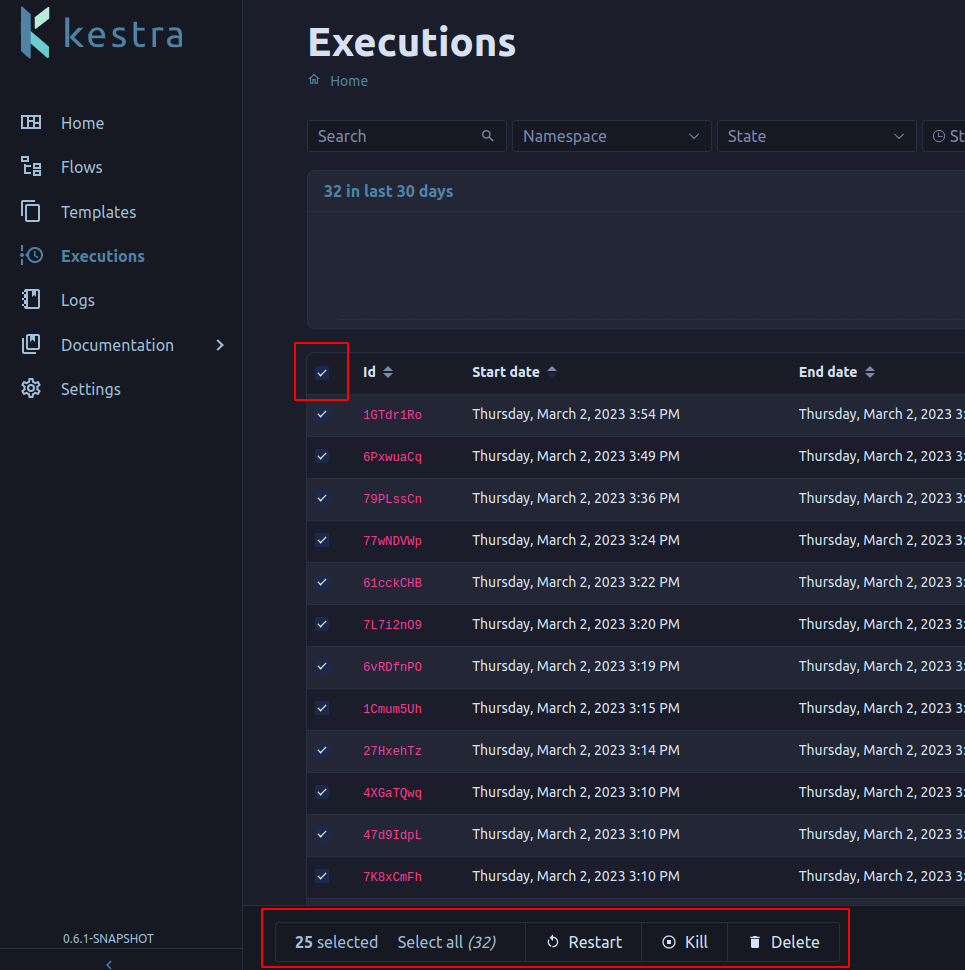
We added support for mass actions for flows, templates, and executions. You can now mass delete all your flows if you want!
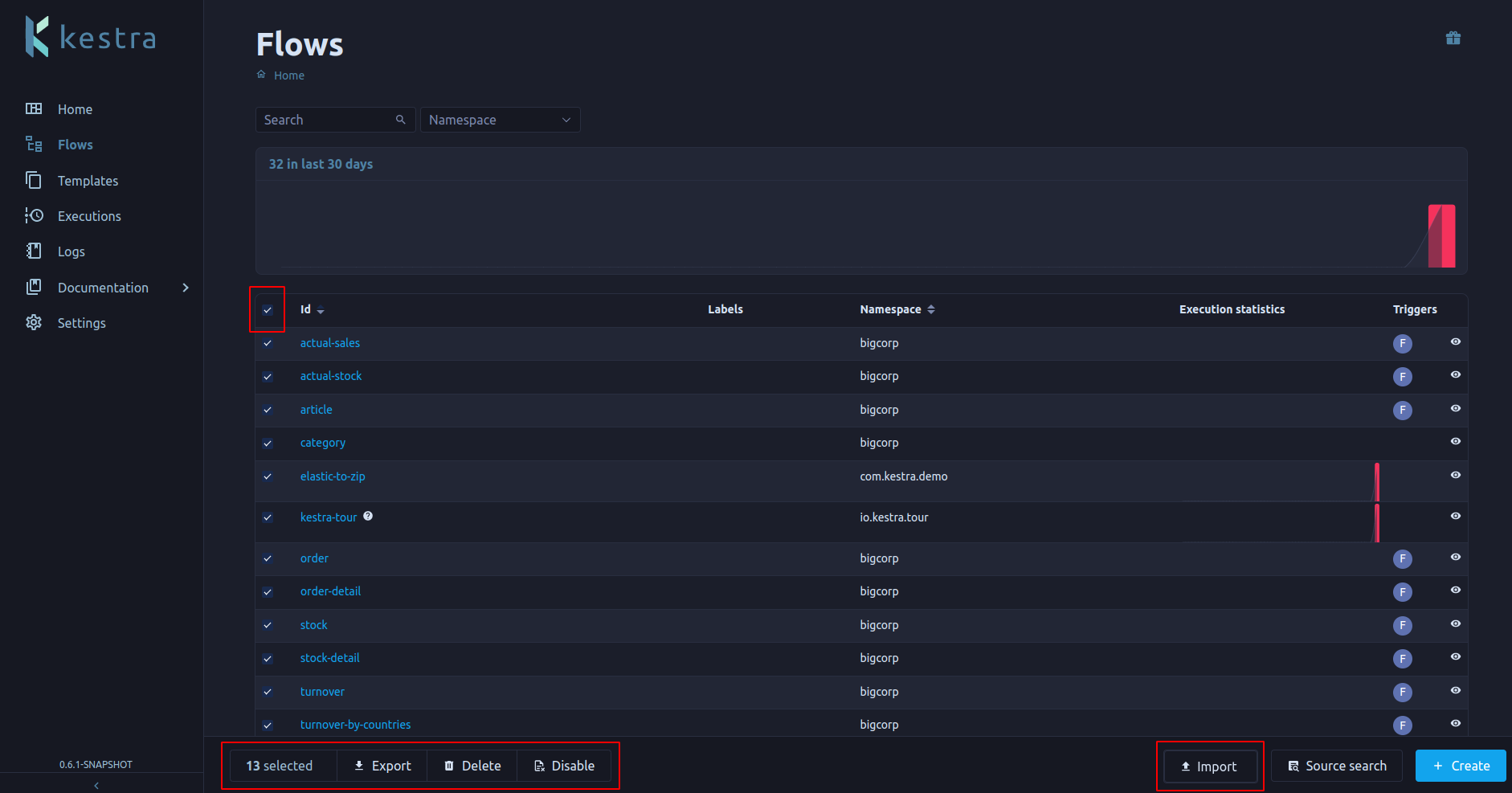
As it was already said in multiple places in this post, we added flows and templates import and export functionalities.
On the flow and template page, you can now import flows or templates from a ZIP of individual YAML files or a multi-object YAML file.
You can also select any flows or templates thanks to the new mass action button and export them.
Flow imports and exports can be very handy when switching between Kestra instances or initiating a CI/CD pipeline. If you need to export everything we added new buttons for this in the Settings page.
On the Enterprise Edition, we had a dashboard on the homepage with many charts, giving some indicators about success, errors, number of executions,…
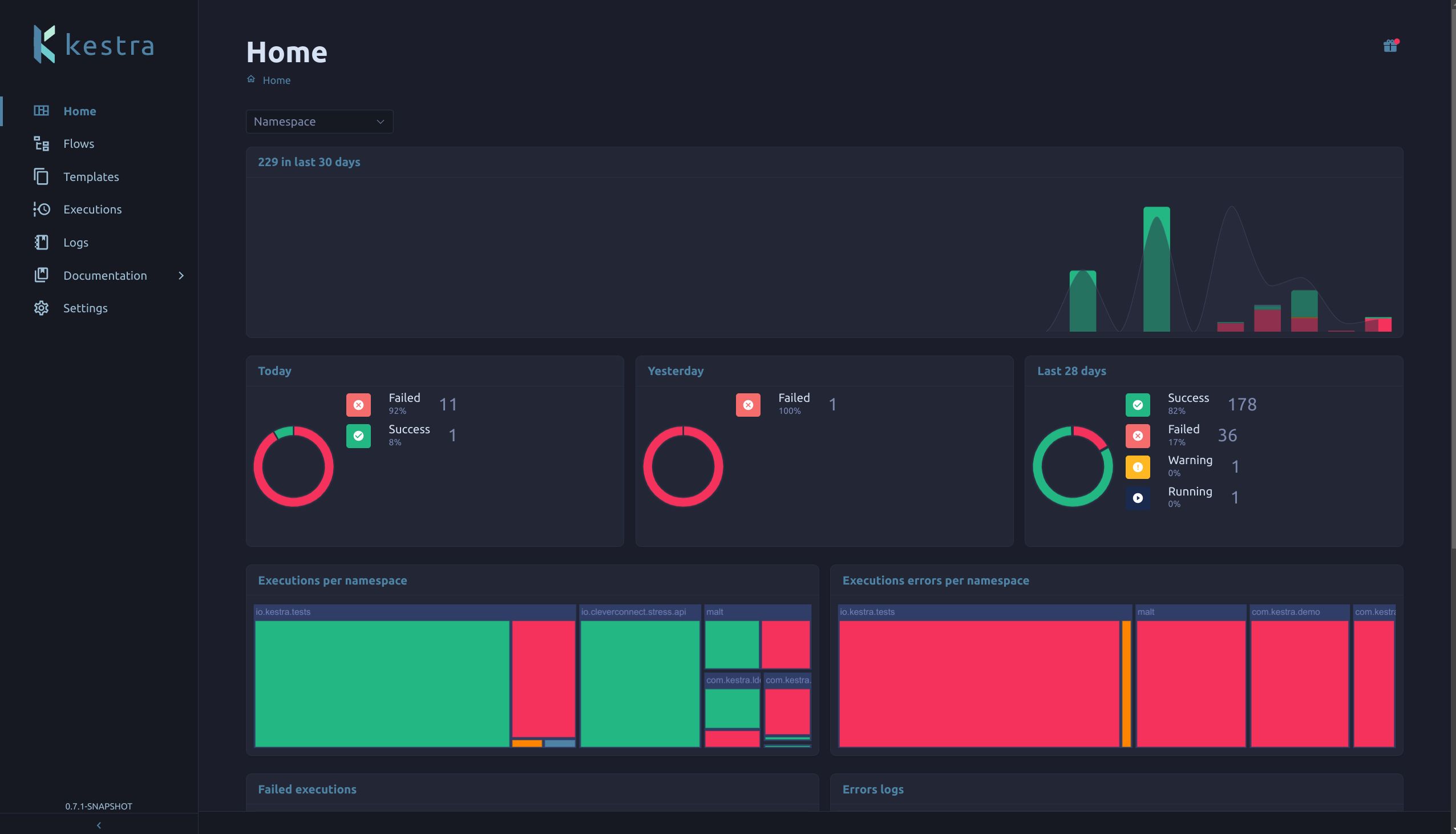
We now moved this dashboard from the Enterprise Edition to the Open Source Edition, making them available for everyone!
We moved Kafka and Elasticsearch from the Open Source Edition to the Enterprise Edition.
On this release, we generously bring a lot of functionalities from the Enterprise Edition to the Open Source Edition as we want to clarify our enterprise offering. By default, everything will be open-sourced for now, except authentication, enterprise security (audit log, secrets, …), and our highly available and highly scalable runtime based on Kafka and Elasticsearch. Everything else will stay open-sourced including all our plugins of course.
We think this is the first and last functionality moving from the Open Source Edition to the Enterprise Edition (but the contrary may not be true 😉).
We’re committed to keeping the database version of Kestra forever on the Open Source Edition and investing time in it. We even already improve its performance in this release by approximately 5 times on some workloads (80% reduction of the execution time of a single flow with 44 tasks).
If you were using Kafka and you’d like to continue using the Open Source Edition without it, you’d need to:
If you’d still like to use the high availability and scalability provided by Kafka and Elasticsearch, you have two options:
More information on the Kestra Enterprise Edition can be found here.
Kestra is built of plugins that provide the many tasks that power your flows.
In this release, we also found the time to add new plugins!
We improve our AWS support by adding plugins for Amazon’s NoSQL Key/Value store DynamoDB, and for Amazon’s SNS and SQS message brokers.
We also fill our message broker support gap by providing plugins for AMQP brokers.
Google Cloud is not left out with the support of its NoSQL Document store Firestore and messaging service PubSub.
Our first plugin to support graph database has landed off: Neo4J, and we also added support for the Redis Key/Value store.
Last but not least, all existing relational database plugins (what we called the JDBC plugins) now have support for flow triggers based on query polling.
We wanted to thank all the contributors who helped us make this release.
For the next release, we plan to make it even easier to start with Kestra and create a flow. For that, we will work on some new low code functionalities so you’ll be able to write a flow without any line of YAML
Rumors say that there is a small low-code functionality already present in this release, go discover where it’s hidden 😋.
These functionalities may be delivered on multiple releases, but be sure to have some editor improvements on the next release!
We also want to keep improving our documentation and examples. We plan to write how-to guides or provide an example flow gallery. Don’t hesitate to share your needs and ideas on this topic with us!
Be sure to follow us on Twitter for the latest news. Please reach out to us on Slack if you have any questions or want to share what tutorial you’d like to see next. And if you love what we do, give a star ⭐️ on our GitHub repository.

Stay up to date with the latest features and changes to Kestra