Authors
Benoit Pimpaud
Benoit Pimpaud
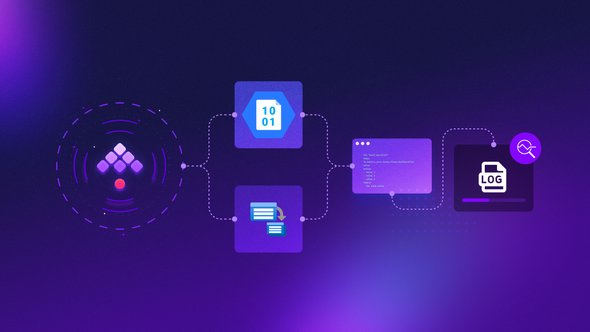
Check out how those three cloud-based technologies are working together to efficiently manage, store, and process large-scale log files.
Azure Blob Storage is a highly-scalable, cost-effective cloud storage solution for unstructured data. It’s designed to store massive amounts of data, making it perfect for serving images, documents, or even storing large-scale log files. Its pay-as-you-go pricing model and tiered storage options allow organizations to optimize storage costs and performance based on their specific requirements.
Azure Batch is a cloud-based job scheduling service that simplifies running large-scale parallel and high-performance computing applications. With its ability to automatically scale resources, Azure Batch can efficiently manage and process large volumes of data, making it an ideal choice when looking to optimize data processing capabilities.
Let’s say you want to collect millions of log files daily from various sources, such as web servers, IoT devices, and mobile applications. You will need to process and analyze these logs to gain insights, detect anomalies, and optimize the performance of your systems. To accomplish this, you can utilize Azure Blob Storage, Azure Batch, and an orchestrator such as Kestra.

The first step in the process is to store the log files in a secure and scalable environment.
Start by creating a blob storage container and configure it with the necessary access policies, to ensure that only authorized users can access the data. In our example, let’s say we consume logs directly from a Kafka topic:
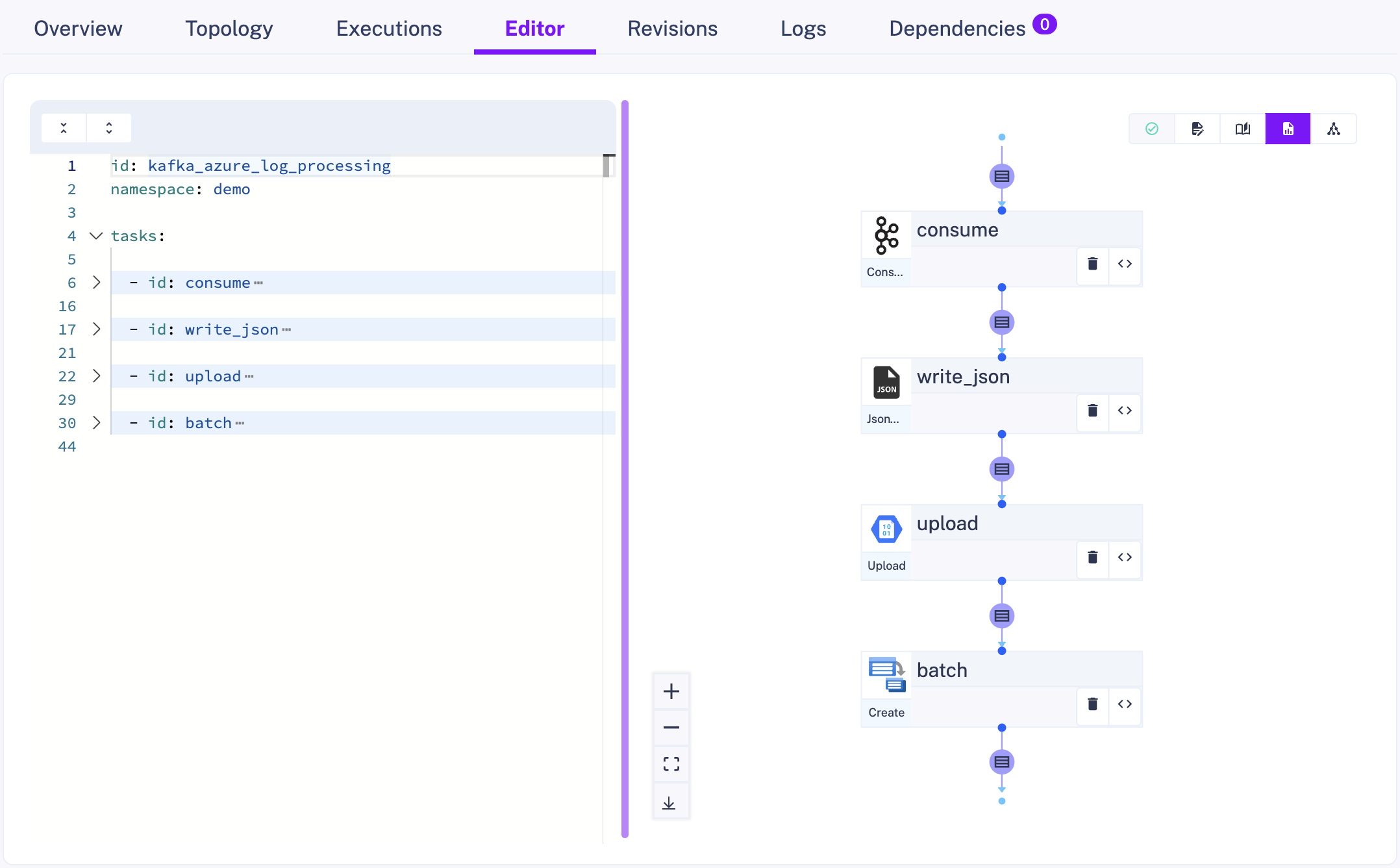
tasks:
- id: consume type: io.kestra.plugin.kafka.Consume topic: topic_test properties: bootstrap.servers: 'kafka-docker-kafka-1:9093' auto.offset.reset: earliest pollDuration: PT20S maxRecords: 50 keyDeserializer: STRING valueDeserializer: JSON
- id: write_json type: io.kestra.plugin.serdes.json.IonToJson newLine: true from: "{{ outputs.consume.uri }}"
- id: upload type: io.kestra.plugin.azure.storage.blob.Upload endpoint: "https://kestrademo.blob.core.windows.net" sasToken: "<token>" container: demo from: "{{ outputs.write_json.uri }}" name: data.jsonHere we have three tasks:
Consume data from a Kafka topic. Quite straightforward here, we just specify the topic and polling parameters. You can find more details in the Kafka plugin documentation.
Write a proper JSON file out of it. Kestra offers several ways to write and read data. Check out the documentation for more details.
Upload those logs to Azure blob storage. We pass data between tasks thanks to the {{ outputs.consume_logs.uri }}. Kestra supports main features of Azure blob storage such as uploading or downloading blobs, list containers, etc.
Once the log files are securely stored, the next step is to process and analyze them. Azure Batch enables you to run large-scale batch workloads. By using Azure Batch, you can create a pool of virtual machines (VMs) to execute tasks in parallel, thereby processing the logs more efficiently.
You can also deploy an Azure Batch application that processes the logs according to your requirements. For instance, the application could extract relevant data, such as IP addresses, timestamps, and error codes, and aggregate them for further analysis.
Here we can create a Batch task having the logic of analyzing the logs encapsulated in a custom Docker image.
- id: batch type: io.kestra.plugin.azure.batch.job.Create endpoint: https://kestrademo.batch.azure.com account: kestrademo accessKey: <access-key> poolId: <pool-id> job: id: process_log tasks: - id: process commands: - 'python process_logs.py' containerSettings: imageName: custom_pythonIt’s worth mentioning that credentials can be set in plain text, but this is not recommended for security reasons. Kestra offers more secure methods for storing secrets, which you can learn about in the documentation. For further details, please refer to the Kestra Administrator Guide.
Kestra can be used to manage the process of transferring logs from your sources to Azure Blob Storage and orchestrating the execution of the Azure Batch application.
You can create a Kestra workflow that gets triggered whenever a new log can be consumed from Kafka. The workflow can perform tasks such as validating the log file’s format, uploading it to Azure Blob Storage, and initiating the Azure Batch application to process the logs. Kestra can also monitor the progress of the Azure Batch application, send notifications in case of any issues, and store the results in a designated location.
Here are some resources if you want to reproduce such a use case:
The combination of Azure Blob Storage, Azure Batch, and Kestra offers a powerful solution for managing, storing, and processing large-scale data workloads. By leveraging these technologies, organizations can efficiently process vast amounts of data and derive valuable insights to drive their business decisions.
Join the Slack community if you have any questions or need assistance.
Be sure to follow us on Twitter for the latest news. And if you love what we do, give a star on our GitHub repository.

Stay up to date with the latest features and changes to Kestra