Authors
Anna Geller

Anna Geller
The key benefit of the Modern Data Stack is that you can avoid vendor lock-in by selecting best-of-breed tools rather than paying expensive license fees for one inflexible solution. However, assembling your modular stack based on multiple SaaS solutions will only marginally improve that situation. It’s undoubtedly easier to swap only one component by, e.g., migrating between two SaaS BI solutions than migrating an entire all-in-one stack. However, the vendor lock-in issue remains unresolved — all you’ll achieve is multiple vendor lock-ins at a smaller scale rather than one giant lock-in. Open-core technologies and SaaS offerings built on top of them can help avoid these issues and future-proof your data stack.
This post will discuss a selection of open-core tools that you can use to build your data stack in a modular way. Specifically, we’ll leverage Airbyte, dbt, and Kestra — all of them are either source-available (Airbyte) or entirely open-source (dbt and Kestra).
Airbyte is a data integration platform that simplifies and standardizes replicating data from source systems to desired destinations, such as a data warehouse or a data lake. It provides many pre-built connectors to various databases, APIs, storage systems, and a low-code CDK for creating new custom connectors.
To start using Airbyte, you only need a workstation with Docker and a terminal. You can follow the quickstart guide to launch Airbyte on your local machine:
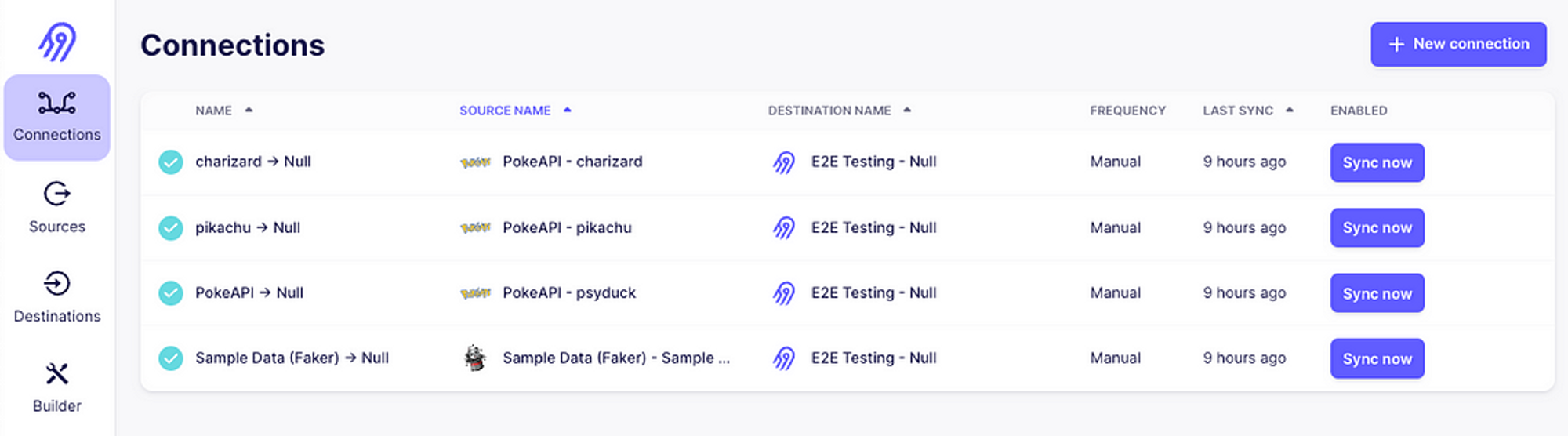
git clone https://github.com/airbytehq/airbyte.gitcd airbyte./run-ab-platform.shThen, you can begin creating your sources, destinations, and connections:
dbt is a data build tool that enables data analysts and engineers to transform data in a cloud analytics warehouse using templated SQL and a Command Line Interface (CLI). After you’ve ingested raw data with Airbyte, dbt can query it and transform it into analytics-ready datasets by executing SQL (or Python) code within your warehouse. Thanks to dbt, you can organize your business logic into modular components (models) and document and test those models. Finally, you can version control your dbt transformations to allow other people in your team to collaborate on the same project and improve the auditability and rollback of your cloud analytics warehouse.
The easiest way to get started with dbt is to leverage the dbt-duckdb package, allowing you to use an in-memory DuckDB database and run everything locally. However, you can also start using dbt for free with Google BigQuery.
Orchestration is a critical aspect of end-to-end data management, as it helps you coordinate all steps, control and monitor their execution, and respond to failure scenarios. For instance, you can ensure that transformation steps run only after your data has been successfully ingested. If something fails, you can retry it and get notified about that failure.
Kestra is a simple, event-driven orchestrator that helps to maintain orchestration logic as code while bridging the gap between engineers and domain experts. The declarative YAML syntax opens the process of building data workflows to domain experts who are not programmers, as well as programmers working on a different stack (a language-agnostic interface rather than only Python).
Let’s look at how you can combine Airbyte, dbt, and Kestra to build an end-to-end workflow.
First, download Kestra’s Docker Compose file, for example, using curl:
curl -o docker-compose.yml https://raw.githubusercontent.com/kestra-io/kestra/develop/docker-compose.ymlThen, run docker compose up -d and navigate to the UI under http://localhost:8080/. You can start building your first flows using the integrated code editor in the UI.
The UI ships with Blueprints, which provide ready-to-use flow examples. For instance, you can use the following Blueprint that combines all steps needed to orchestrate Airbyte, dbt, and Kestra:
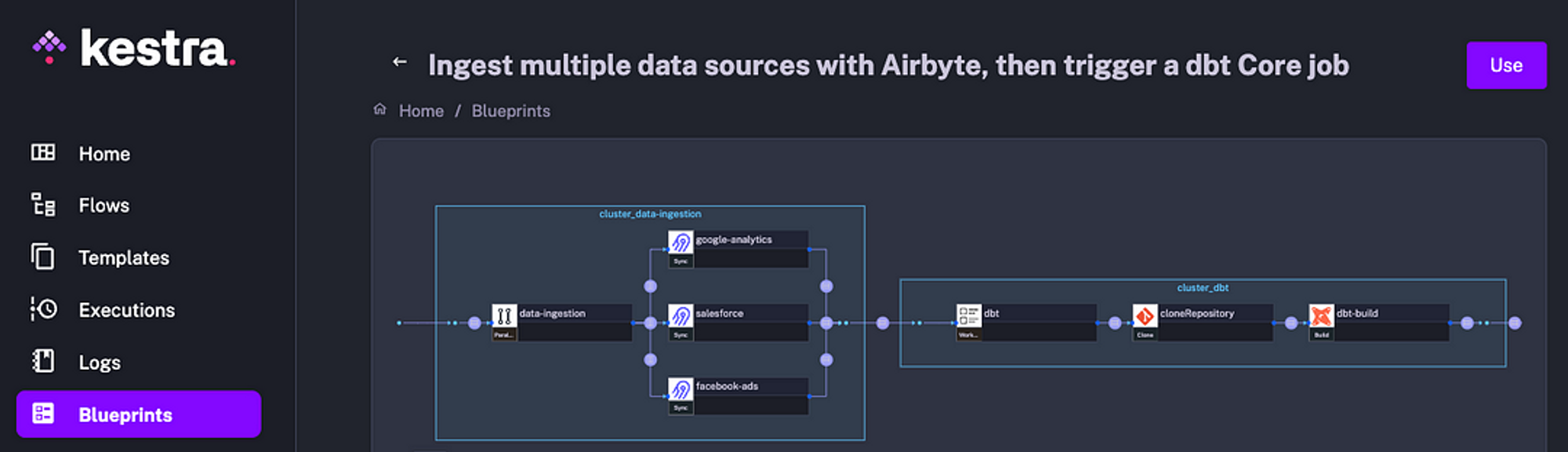
Here is a copy of that Blueprint. Make sure that you copy the ID of each connection from the Airbyte UI and paste those into the Airbyte task:
id: airbyteDbtCorenamespace: company.team
tasks: - id: data-ingestion type: io.kestra.plugin.core.flow.Parallel tasks: - id: psyduck type: io.kestra.plugin.airbyte.connections.Sync connectionId: 4de8ab1e-50ef-4df0-aa01-7f21491081f1
- id: sample-data type: io.kestra.plugin.airbyte.connections.Sync connectionId: 71291950-ccc1-4875-91b7-e801376c549e
- id: charizard type: io.kestra.plugin.airbyte.connections.Sync connectionId: 9bb96539-73e7-4b9a-9937-6ce861b49cb9
- id: pikachu type: io.kestra.plugin.airbyte.connections.Sync connectionId: 39c38950-b0b9-4fce-a303-06ced3dbfa75
- id: dbt type: io.kestra.plugin.core.flow.WorkingDirectory tasks: - id: cloneRepository type: io.kestra.plugin.git.Clone url: https://github.com/jwills/jaffle_shop_duckdb branch: duckdb
- id: dbt-build type: io.kestra.plugin.dbt.cli.Build debug: true runner: DOCKER dockerOptions: image: ghcr.io/kestra-io/dbt-duckdb:latest dbtPath: /usr/local/bin/dbt inputFiles: .profile/profiles.yml: | jaffle_shop: outputs: dev: type: duckdb path: ':memory:' extensions: - parquet target: devpluginDefaults: - type: io.kestra.plugin.airbyte.connections.Sync values: url: http://host.docker.internal:8000/ username: "{{envs.airbyte_username}}" password: "{{envs.airbyte_password}}"When you execute that workflow, you should see a similar output:
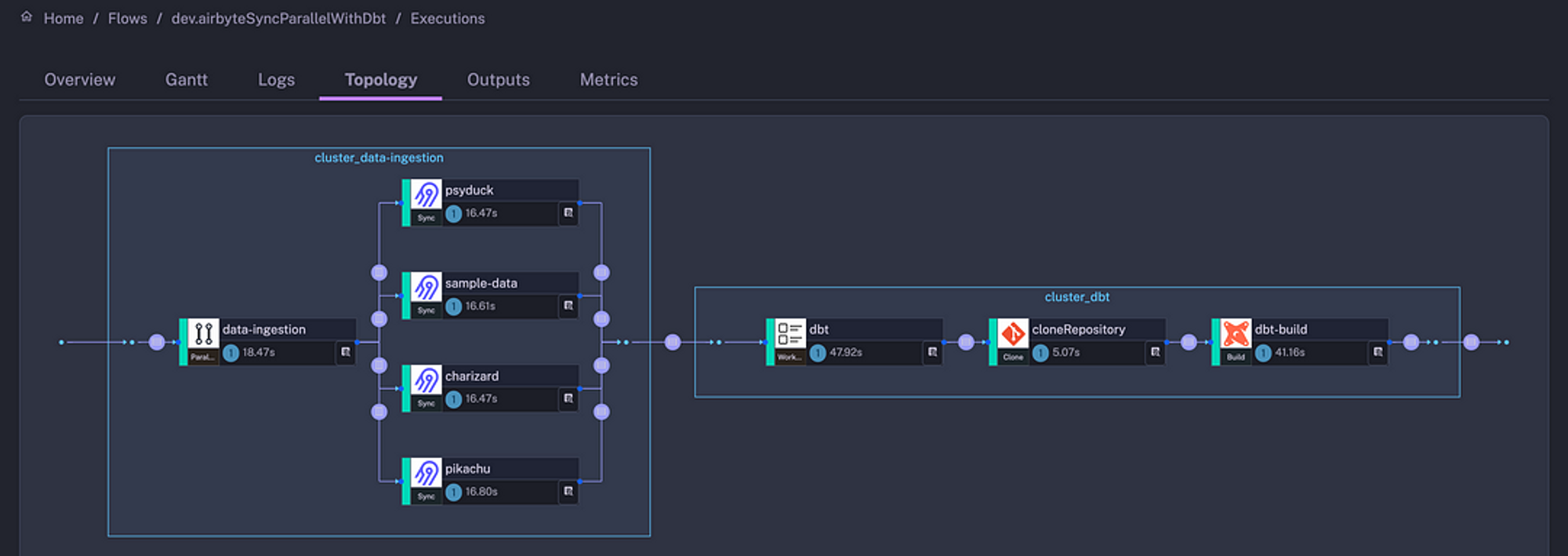
The flow runs four Airbyte data ingestion processes in parallel. Once raw data is successfully ingested, the flow clones a Git repository and runs dbt CLI commands that build models committed to that Git repository.
The topology view shows the duration of each task. The entire flow, executing four Airbyte syncs and dbt build, took just one minute to run — all that without having to manually install any dependencies or build a CI/CD. To schedule that flow, you can add a simple CRON-based trigger:
triggers: - id: everyMinute type: io.kestra.plugin.core.trigger.Schedule cron: "*/1 * * * *"This post covered how combining Airbyte, dbt, and Kestra can simplify data management. Using these open-core technologies, you can avoid vendor lock-in and get the most out of the Modern Data Stack. If you encounter anything unexpected while reproducing this demo, you can open a GitHub issue or ask via Kestra Community Slack. Lastly, give us a GitHub star if you like the project.

Stay up to date with the latest features and changes to Kestra