Authors
Anna Geller

Anna Geller
MotherDuck is the managed cloud version of DuckDB, now generally available and used in production by engineering teams worldwide. This post covers how to get started with both DuckDB and MotherDuck, the key differences between them, and when to choose each option. Before diving in, let’s clarify what each product is.
DuckDB is considered SQLite for Analytics. It’s an open-source embedded OLAP database that can run in-process rather than relying on the traditional client-server architecture. As with SQLite, there’s no need to install a database server to get started. Installing DuckDB instantly turns your laptop into an OLAP engine capable of aggregating large volumes of data at an impressive speed using just CLI and SQL. It’s especially useful for reading data from local files or objects stored in cloud storage buckets (e.g., parquet files on S3).
In short, this lightweight embedded database allows fast queries in virtually any environment with almost no setup. However, it doesn’t offer high concurrency or user management, and it doesn’t scale horizontally. That’s where MotherDuck can help.
MotherDuck is a serverless DuckDB in the cloud with managed storage, data sharing, interactive SQL IDE, and a growing number of features. It’s described as a collaborative analytics platform allowing hybrid execution between data stored in the cloud (incl. data stored in MotherDuck databases and data stored in remote cloud storage buckets) and data available locally (incl. local files and your local DuckDB instances). MotherDuck intelligently decides what’s the best place to run a given query. You can execute JOINs between tables in your MotherDuck database and data stored locally on your laptop.
The DuckDB Foundation is a non-profit organization receiving donations that fund DuckDB development, ensuring a stable MIT-licensed open-source project.
DuckDB Labs is a research/consulting company working on the open-source DuckDB project and helping other companies adopt DuckDB, integrate it with external systems, and build custom extensions. DuckDB Labs is not competitive with MotherDuck (the company behind the MotherDuck product). They have been, in fact, partnering to help integrate MotherDuck’s SaaS into the core DuckDB, and DuckDB Labs owns a portion of MotherDuck.
MotherDuck adds several features, including the following:
Start with local DuckDB. When you hit the limits of what you can query on a single machine, the managed cloud version is worth considering, especially for hybrid execution between local and cloud-stored data.
Similarly, sharing data is already possible when persisting query results, e.g., to S3. However, MotherDuck offers a convenient way of organizing data into databases and tables accessible from anywhere, which is another advantage of MotherDuck over DuckDB.
Speaking of convenience, MotherDuck ships with a clean UI that offers a built-in collaborative SQL IDE, a dataset browser/loader, and extra features to sort and pivot query results for more productive analysis.
However, note that there are some DuckDB features that MotherDuck doesn’t support yet at the time of writing, such as UDFs, stored procedures, checkpointing, or custom extensions.
In short, MotherDuck adds collaboration, scale, (meta)data management, and convenience to DuckDB.
You can install DuckDB using Homebrew (check the install guide for your operating system):
brew install duckdbThen, start DuckDB from the CLI and run your first queries:
$ duckdb orders.db-- to load data from HTTP URL, install the httpfs extensionINSTALL httpfs;LOAD httpfs;
-- create table from a remote CSV fileCREATE TABLE orders ASSELECT * FROM read_csv_auto('https://huggingface.co/datasets/kestra/datasets/raw/main/csv/orders.csv');
-- create another tableCREATE TABLE bestsellers asSELECT product_id, round(sum(total),2) as totalFROM ordersGROUP BY 1ORDER BY 2 DESC;
-- query the resultFROM bestsellers;You should see the following output:
FROM bestsellers;┌────────────┬─────────┐│ product_id │ total ││ int64 │ double │├────────────┼─────────┤│ 1 │ 5314.9 ││ 14 │ 4983.64 ││ 9 │ 4673.32 ││ 3 │ 4462.98 ││ 2 │ 4066.66 ││ 6 │ 3831.39 ││ 19 │ 3383.04 ││ 12 │ 3273.13 ││ 17 │ 3058.31 ││ 11 │ 2778.4 ││ 10 │ 2709.66 ││ 20 │ 2382.38 ││ 16 │ 2127.31 ││ 4 │ 1953.19 ││ 7 │ 1697.64 ││ 5 │ 1525.07 ││ 8 │ 1503.9 ││ 15 │ 1383.97 ││ 18 │ 1141.83 ││ 13 │ 505.65 │├────────────┴─────────┤│ 20 rows 2 columns │└──────────────────────┘To share that bestsellers table with others in your team, you can export it as a CSV file:
COPY bestsellers TO 'bestsellers.csv' (HEADER, DELIMITER ',');You can also export it to S3 using the httpfs extension (just make sure to add the S3 credentials):
SET s3_region='us-east-1';SET s3_secret_access_key='supersecret';SET s3_access_key_id='xxx';COPY bestsellers TO 's3://yourbucket/bestsellers.parquet';So far, we’ve created just two tables: orders and bestsellers. Let’s say you kept creating more tables within the local orders.db database, and now you want to share them with a colleague. Exporting every table to a file or to S3 one by one can be tedious. MotherDuck makes data sharing and ingestion straightforward:
Let’s explain that in more detail.
First, sign up (or sign in) to app.motherduck.com. Then, copy the service token from the UI, and save it somewhere safe, e.g., as an environment variable:
export MOTHERDUCK_TOKEN=your_tokenWithin your duckdb terminal session, run the command .open md:my_db?motherduck_token=xxx, where:
md stands for MotherDuckxxx is a placeholder for your MotherDuck service token.To verify successful authentication, you can show available databases:
$ duckdb orders.dbD show databases; -- local DB is named orders; no other DBs are attached┌───────────────┐│ database_name ││ varchar │├───────────────┤│ orders │└───────────────┘D .open md: -- connect to MotherDuckD show databases; -- orders DB is not displayed as it's not in MotherDuck yet┌───────────────┐│ database_name ││ varchar │├───────────────┤│ my_db ││ sample_data │└───────────────┘The SQL statement CREATE DATABASE dbname FROM 'orders.db'; will upload the entire local orders.db to the cloud, including all tables we’ve created so far:
D CREATE DATABASE orders FROM 'orders.db';D show databases; -- verify that orders database got ingested┌───────────────┐│ database_name ││ varchar │├───────────────┤│ my_db ││ orders ││ sample_data │└───────────────┘The local orders database is now in the cloud, and you can run queries from a friendly, lightweight notebook interface.
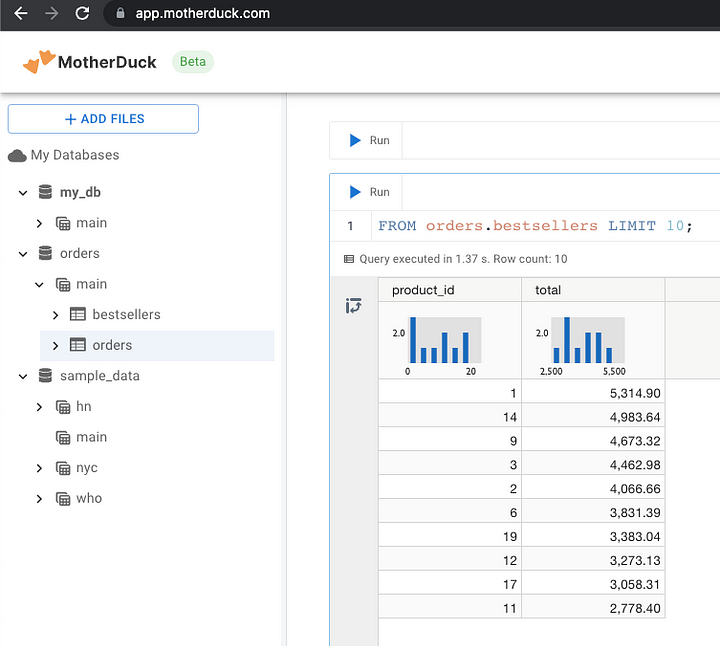
Our local orders database is now in the cloud — image by the author
Here is the SQL statement to create a share URL:
D CREATE SHARE orders_share FROM orders;┌───────────────────────────────────────────────────────┐│ share_url ││ varchar │├───────────────────────────────────────────────────────┤│ md:_share/orders/6714ca1e-2e1e-46ef-b098-1e306fcf01e6 │└───────────────────────────────────────────────────────┘Another person with a MotherDuck account can now access that dataset using the command:
ATTACH 'md:_share/orders/6714ca1e-2e1e-46ef-b098-1e306fcf01e6' AS orders_db;USE orders_db;FROM bestsellers;So far, we’ve executed standalone queries. Let’s now cover some end-to-end use cases that will leverage MotherDuck for reporting and ETL data pipelines. The examples shown below use Kestra — an open-source orchestration tool with a dedicated DuckDB plugin. However, note that MotherDuck also integrates with other orchestrators, such as Apache Airflow.
To get started with Kestra, you can download the Docker Compose file, run docker compose up -d and launch the UI from http://localhost:8080. From here, you can find several built-in DuckDB examples available in the UI as Blueprints.
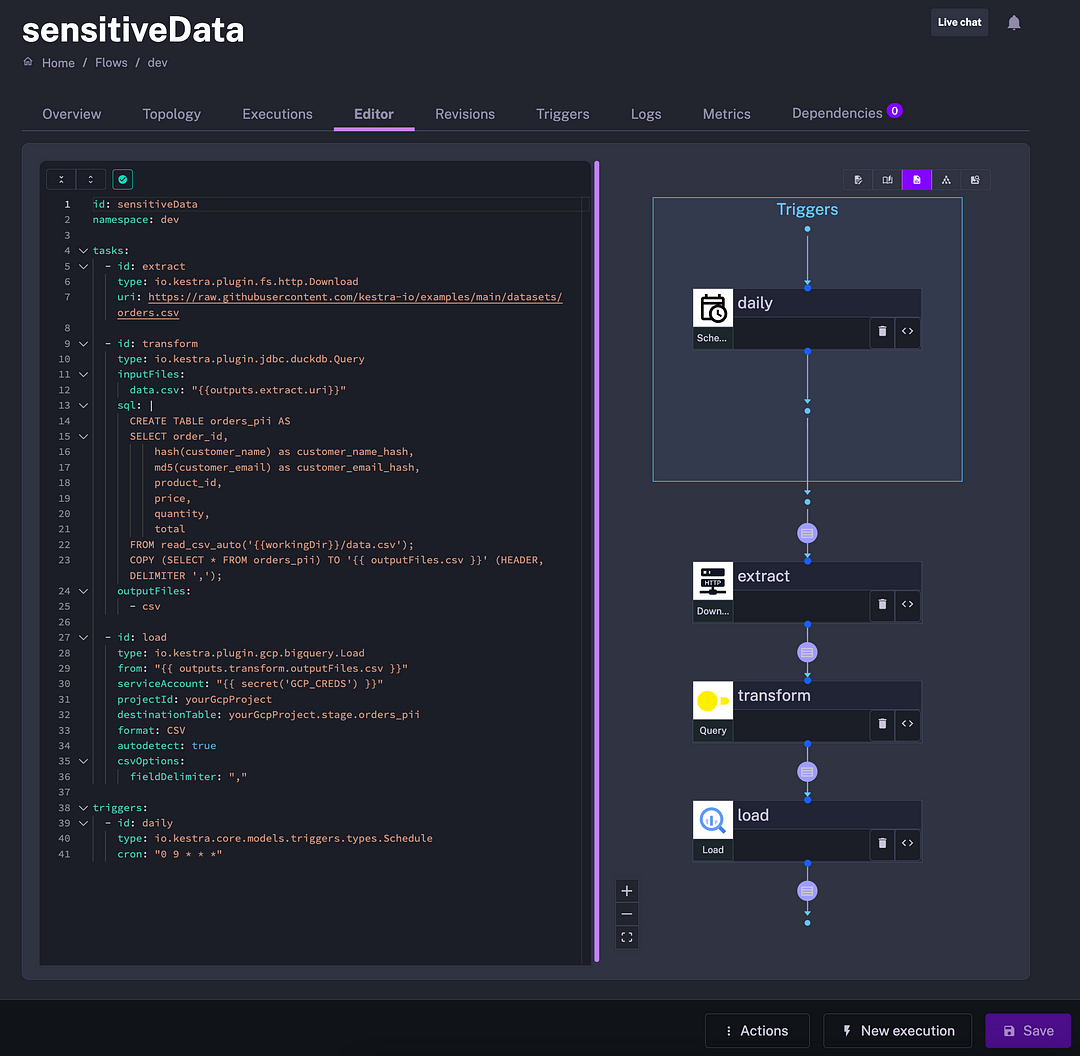
I found the blueprint “Extract data, mask sensitive columns using DuckDB and load it to BigQuery” particularly useful. Source systems often contain sensitive data that requires pseudonymization before you are allowed to load that data to a data warehouse and use it for analytics. DuckDB provides utility functions such as hash() and md5() that can mask sensitive columns between the extract and load steps in a data pipeline. The example shown in the image below illustrates how DuckDB helps solve fairly complex problems in a simple SQL query.
Here is a brief summary of other data pipeline blueprints using DuckDB:
This post covered what is DuckDB and MotherDuck, and when you should move from a local DuckDB to the cloud. We looked at various ways to use MotherDuck and how you can integrate it into your data pipelines.
This post didn’t cover all MotherDuck’s features, such as using AI to query data. Check the documentation for full coverage of what you can do with that managed DuckDB service.

Stay up to date with the latest features and changes to Kestra