
Authors
Benoit Pimpaud
Benoit Pimpaud
Accessing football data has never been more convenient than it is today. With public websites featuring user-friendly bot policies and private companies opening up their datasets, getting started with football analytics is a far smoother journey than it was just a few years ago.
But, here’s the real challenge: once you have the data, how do you effectively process and analyze it? While the traditional route may involve opening a Jupyter Notebook or an RStudio session, it often lacks the simplicity of replication, automation, and clean semantics.
Until recently, orchestrating data ingestion, constructing robust analysis, and automating the entire process seemed like a task requiring a Ph.D. in data engineering.
Is there a more straightforward approach to enhance the reliability of our analysis and automate data scraping?
In this blog post we will see how using the last data tool kids in the block helps us to fetch football data, perform powerful yet simple queries, and seamlessly manage the entire process.
fbref.com is a well-known website for football analytics enthusiasts: it covers many competitions with a lot of statistical details for games, teams, players, etc.
From a data-engineering perspective, fbref facilitates the task for us: it has quite nice scraper policies and has a very simple design making the scraping task not a painful challenge.
You could find a specific scraper project in this repository: at the moment of writing it contains parsers for the matches/ and the fixtures/ endpoints.
It’s quite straightforward, as we only need to retrieve table tags and write them as proper CSV files. Here is an example of how we parse the table for the competition fixtures pages:
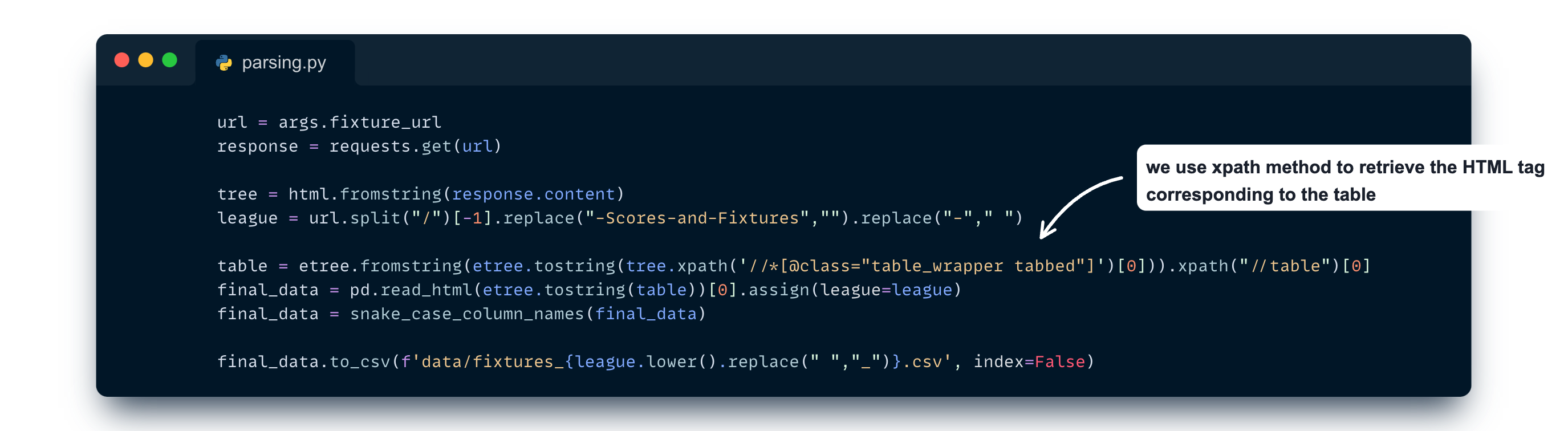
If you’re willing to explore the whole parsing strategies and dedicated CLI, check out the project on GitHub.
Once we have some data we can start diving into analysis. To do so, we’ll use the new language introduced by some Google fellows recently : Malloy. If you don’t know Malloy already, I urge you to watch this talk made during the Data Council conference in 2023.
Long story short: Malloy is an open source language that offers a new way to compose with data. When you’re working with complex data, and want to see the relationships between data, you often end-up in complex queries.
Malloy wants to break the “rectangle shapes” of data. Most data exists in hierarchies (orders, items, products, users). Most query results are better returned as a hierarchy (category, brand, product).
Malloy provides a smart semantic to deal with hyper-dimensional data, nested queries and dimension/measure modelling.
Let’s start with a simple example on our freshly scraped data:
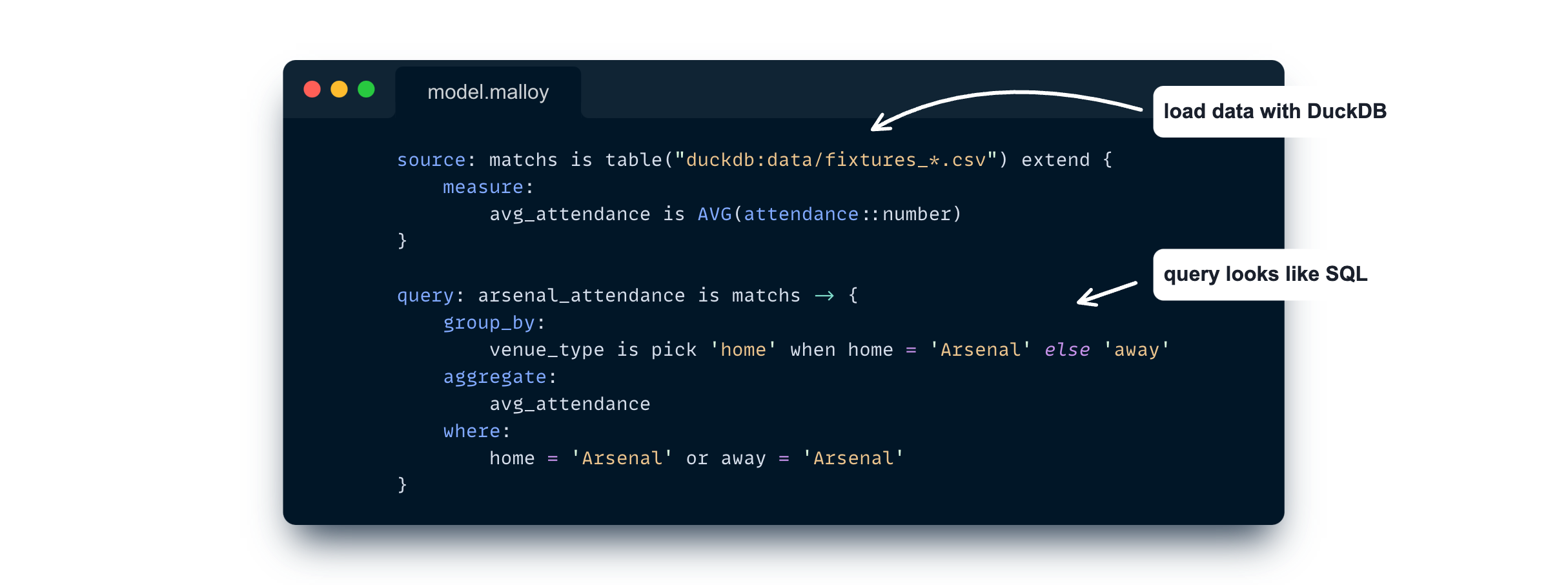
This query allows us to compute the average attendance of Arsenal team depending on the game venue (home or away).
Malloy currently supports reading data from BigQuery, DuckDB and Postgre. We’re using the DuckDB engine here for easier reproducibility.
They are many interesting things to notice in this simple example:
Malloy can be run directly in your VS Code editor, from Python, Node or with a dedicated CLI. It also comes with a notebook-like component, which is great to create complex reports.
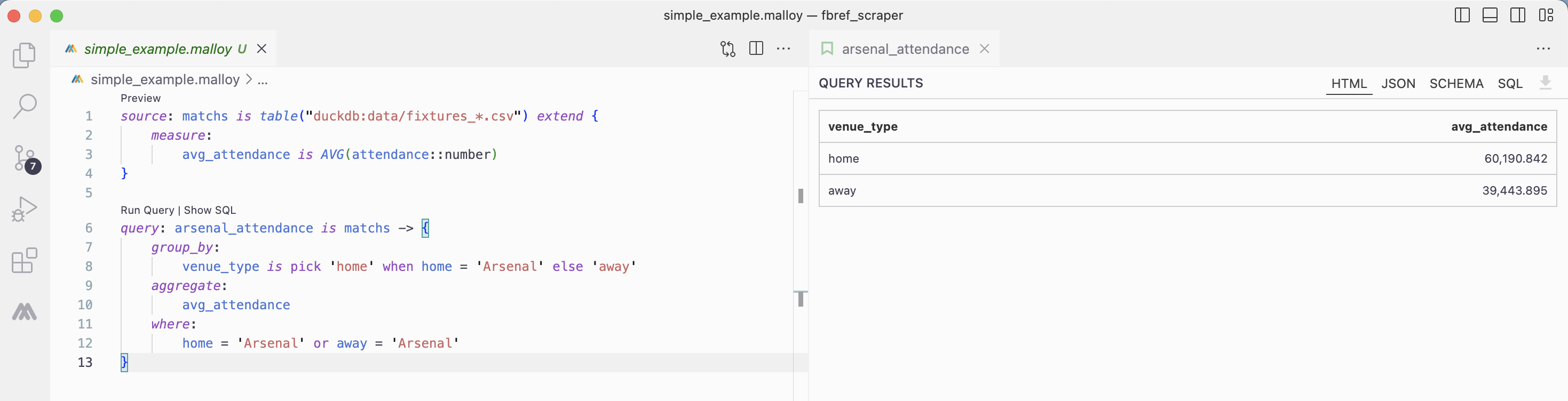
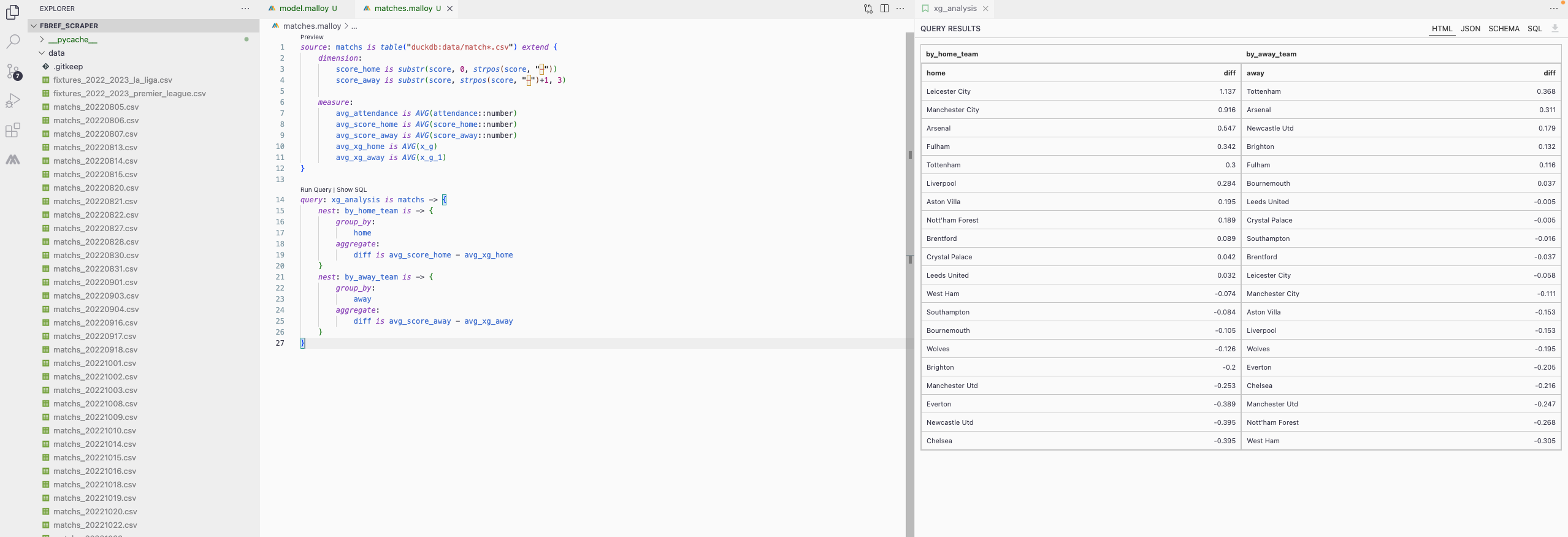
This first example is very straightforward and doesn’t bring new things compared to SQL. Things get very interesting when we look at complex queries:
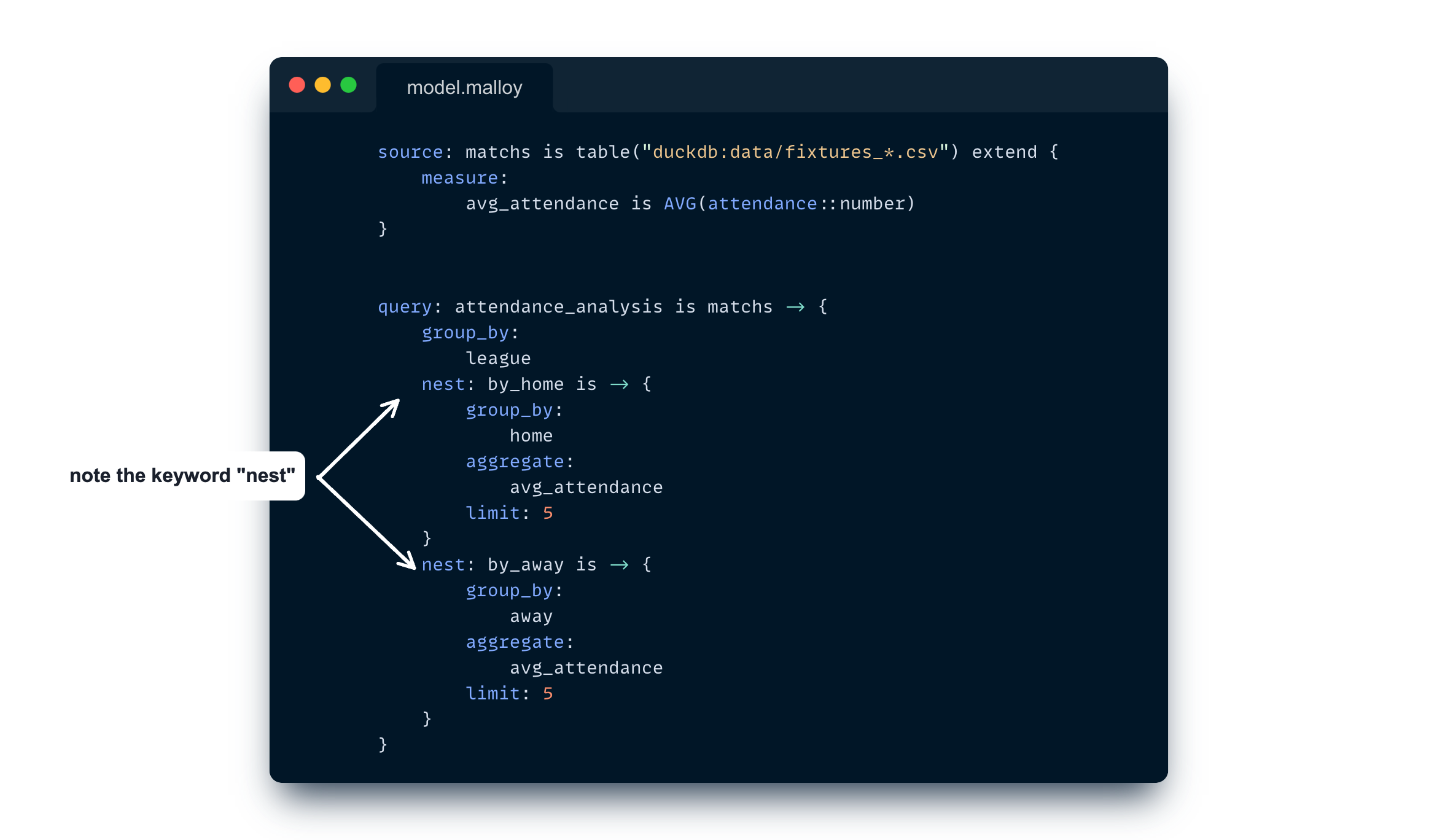
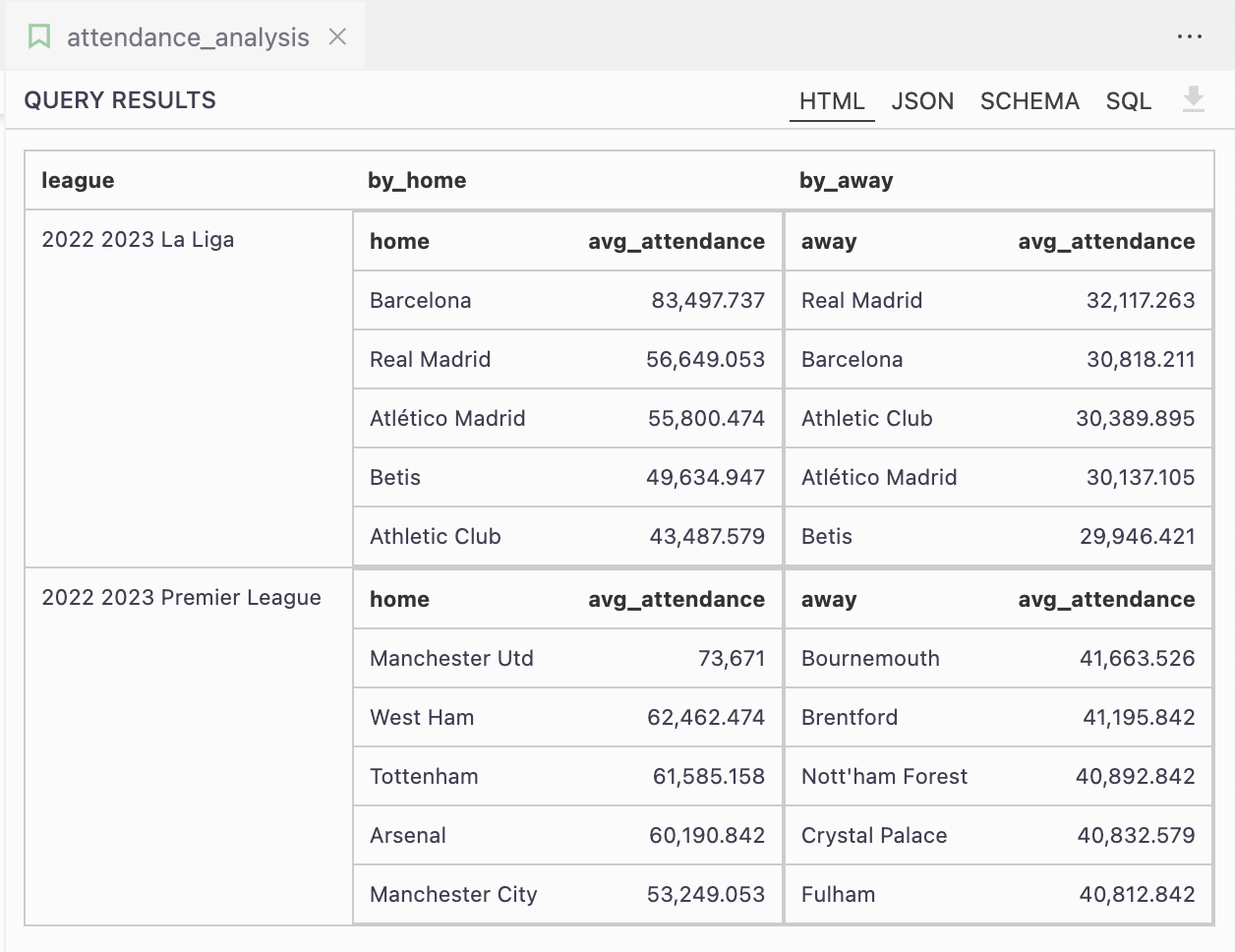
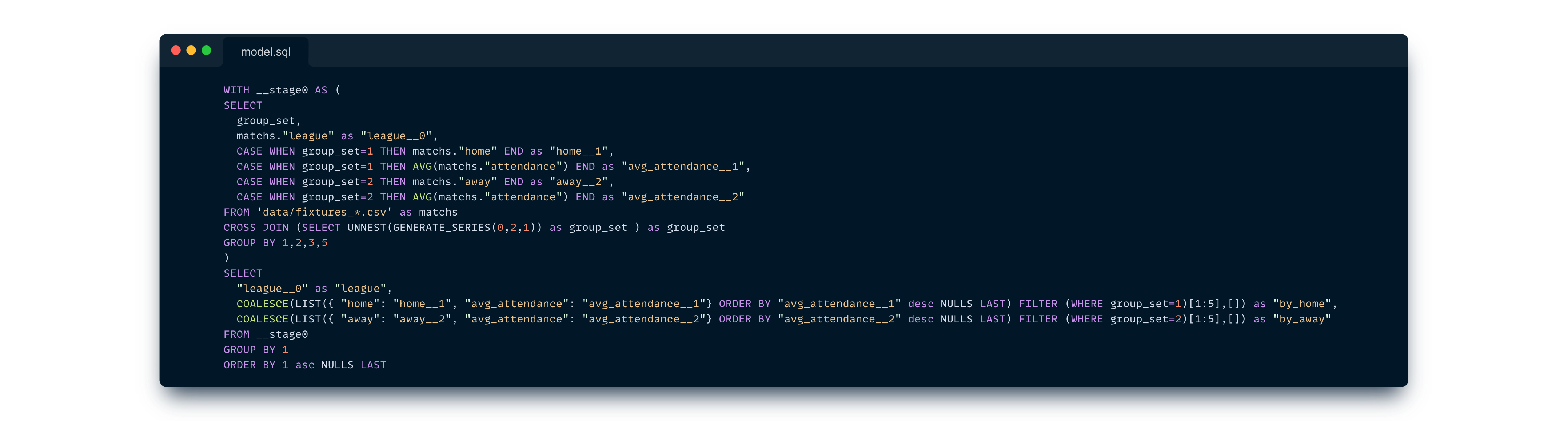
See how we neatly nest results here? Doing this in SQL would be much trickier. Looking at Malloy’s compiled SQL gives us a hint about the complexity in regular SQL.
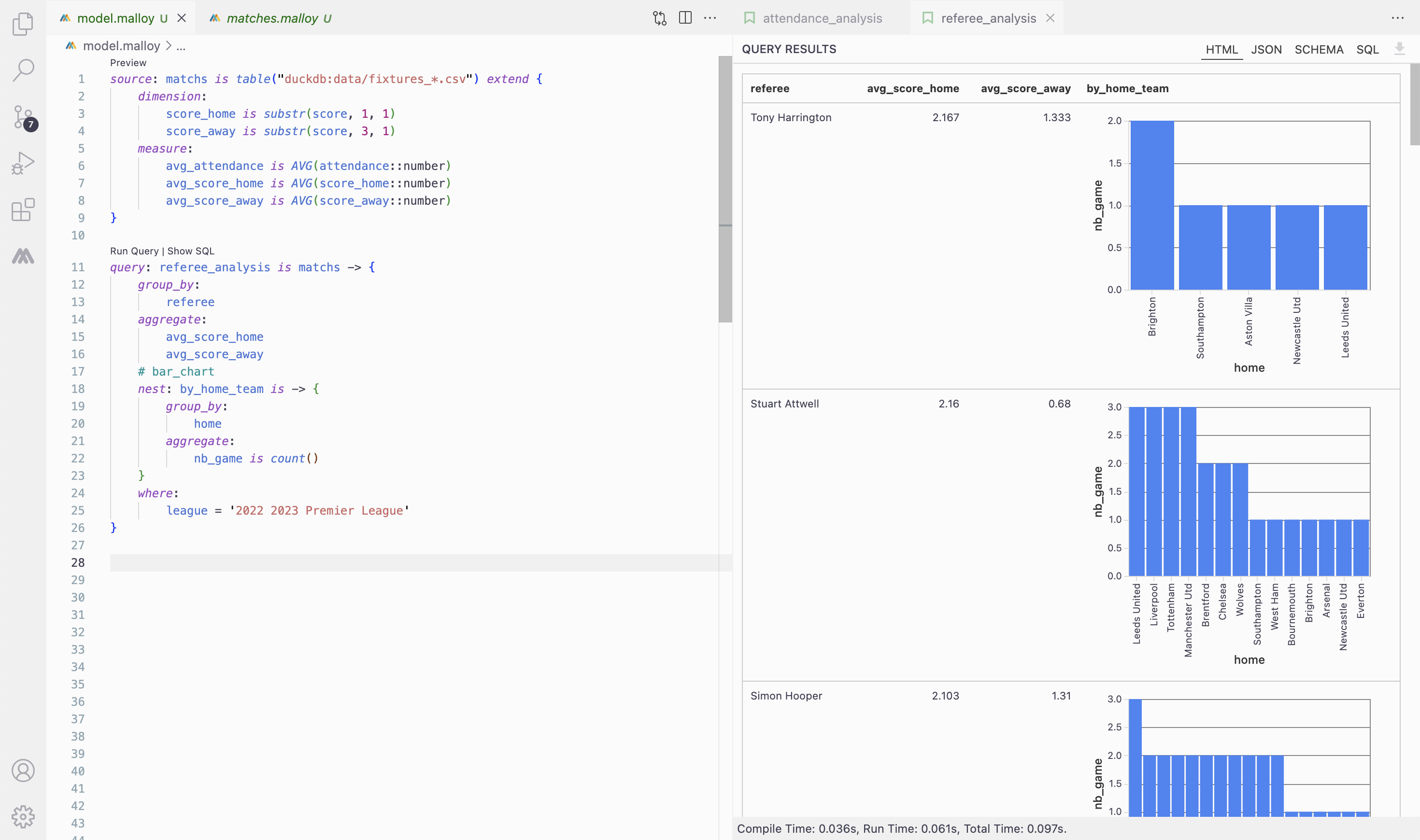
Furthermore Malloy supports some plotting features with simple tags such as below example. Just add # bar_chart will draw a bar chart for each nested result.
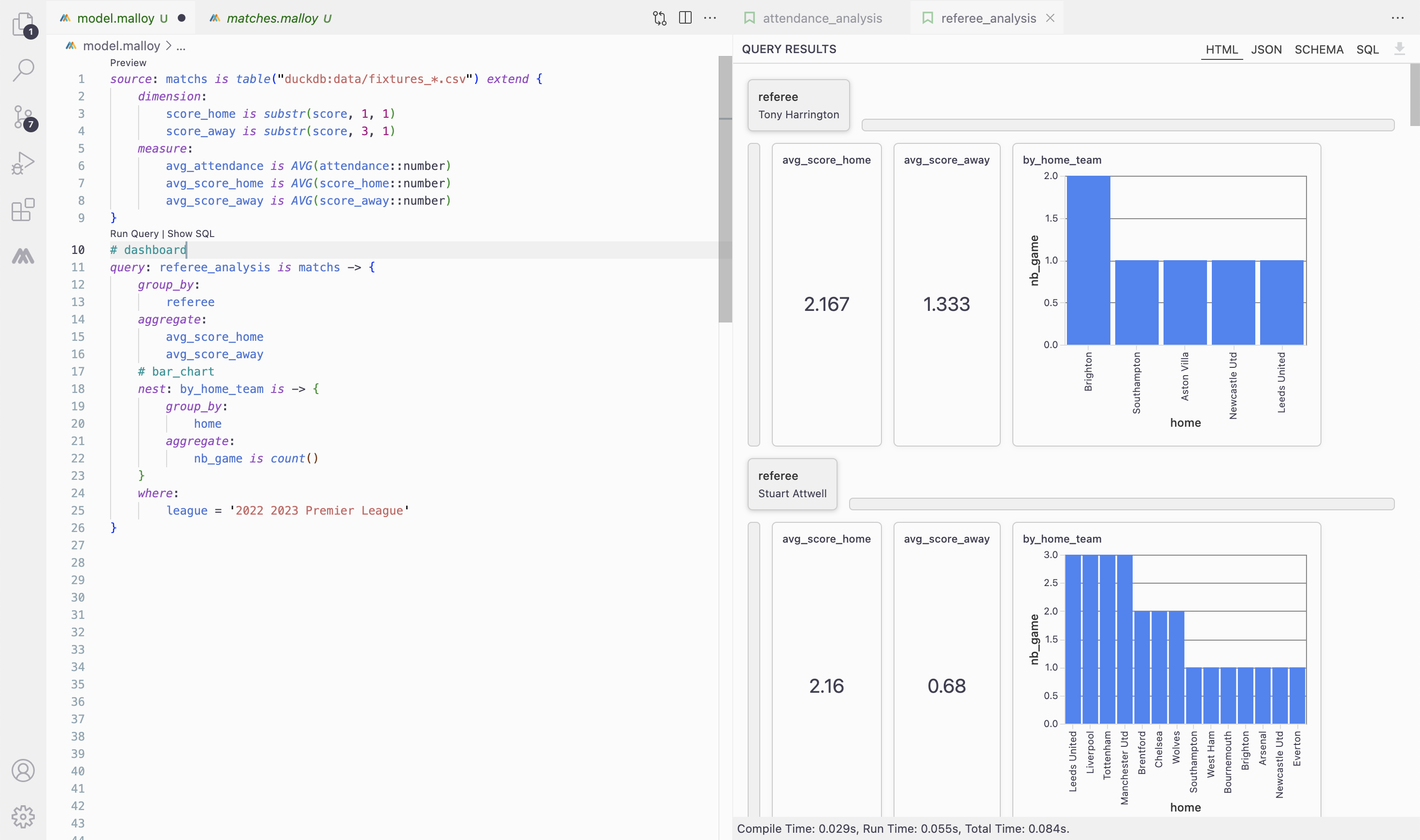
Same, with # dashboard tag a query is rendered as a dashboard, dimensions aligned at the top, and aggregates and nested queries float within the dashboard.
You can check all rendering tags in the documentation.
I encourage you to look at the whole documentation, especially the common pattern section showcasing the power of Malloy.
Now that we have a scraper to get data and a tool to analyze them, we need to link the two on a schedule.
That’s where Kestra makes the glue !
Kestra is an open-source declarative orchestrator. You can write data workflows using YAML files and trigger executions seamlessly.
Let’s create a first flow to scrape matches results every day.
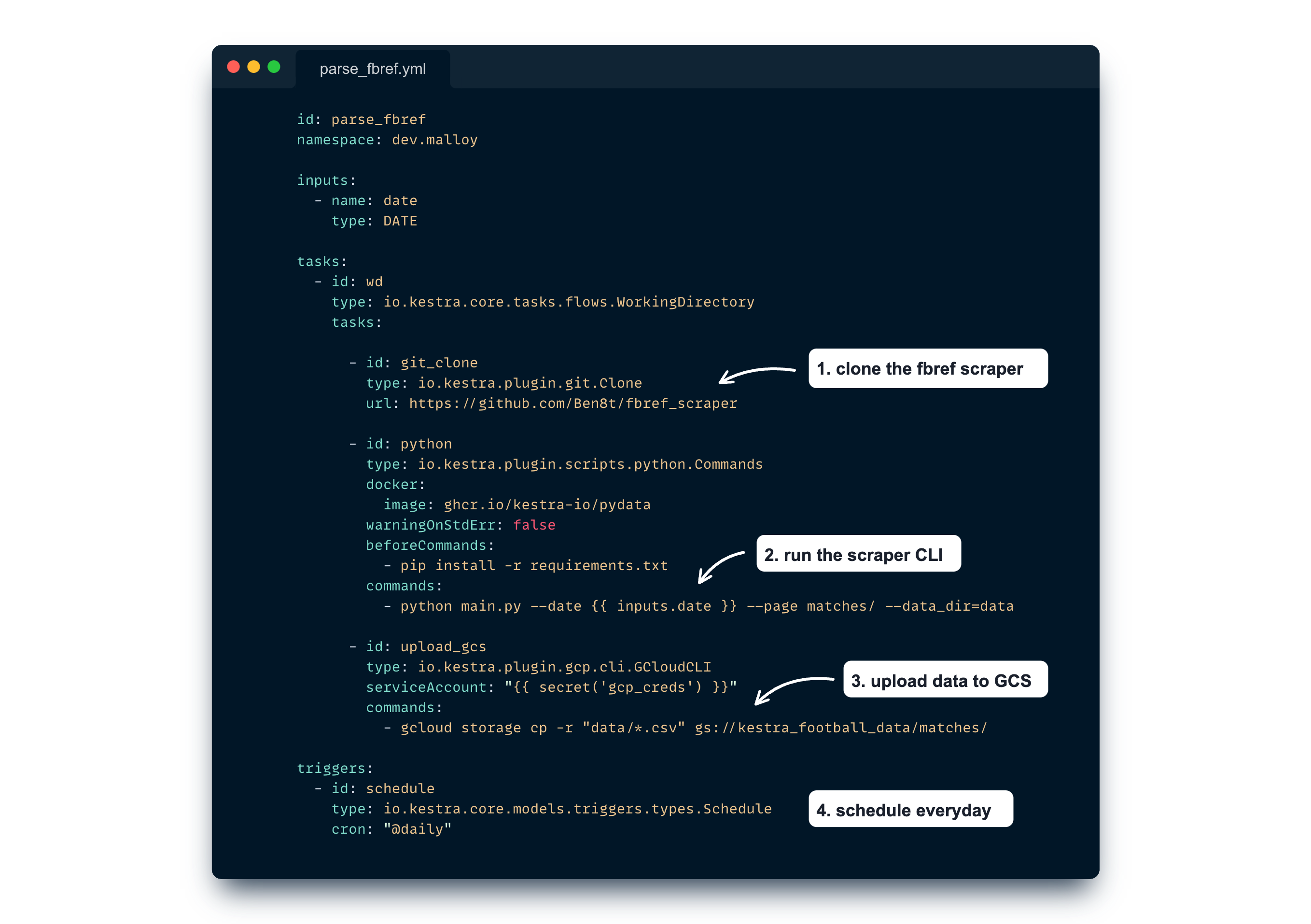
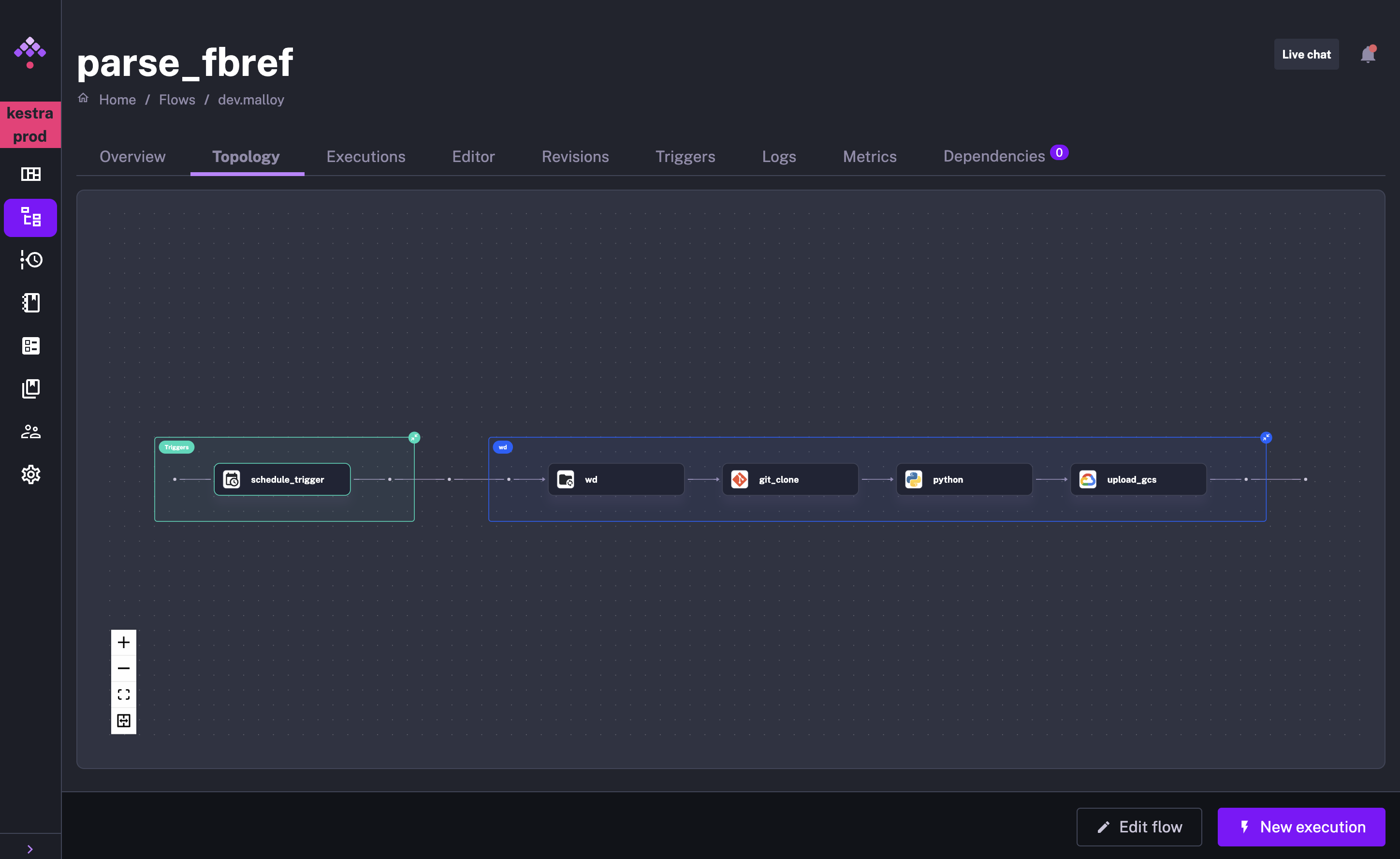
This Kestra Flow does several things:
Now that we have a process to get data everyday, we can move on to analysis automation with Malloy.
In a separate flow we use the Malloy CLI Kestra plugin to run Malloy commands on our data:
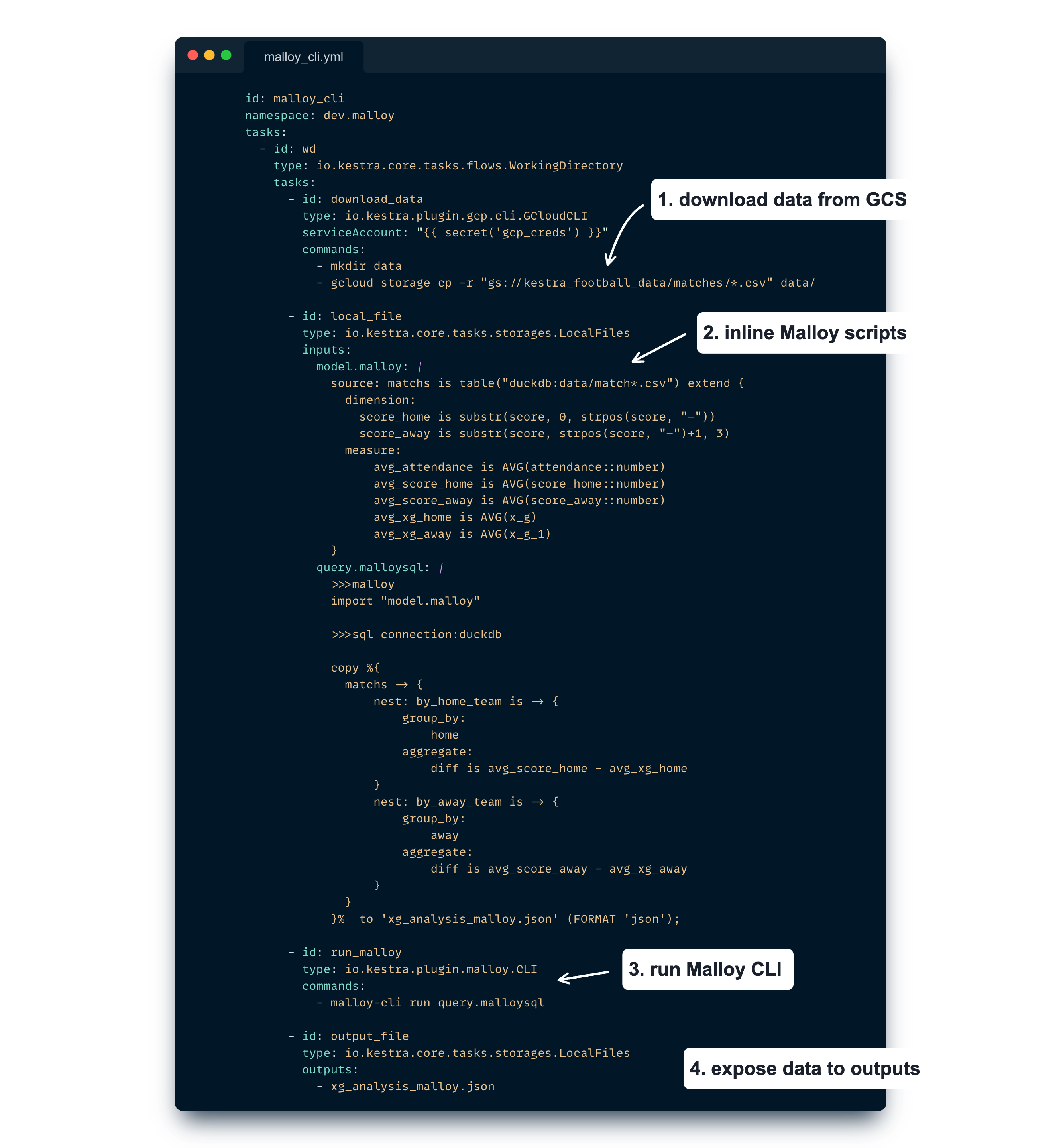
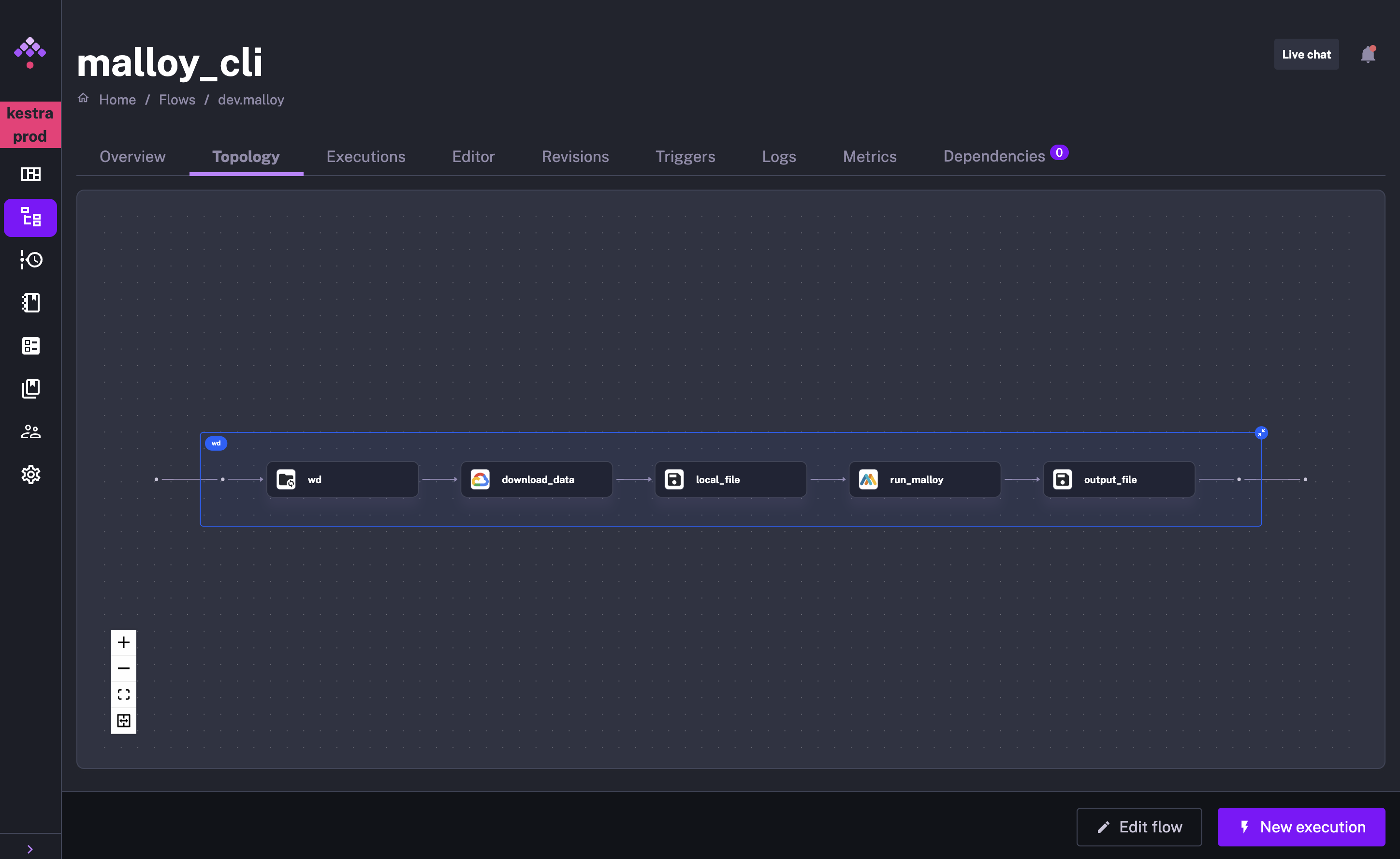
In this flow we have the following tasks:
Here we export Malloy results to a JSON file, but we could have saved those to BigQuery tables for example, enabling us to connect dashboard tools such as Looker, Metabase or Superset.
If you want to know more about Kestra and its wide range of possibilities, I encourage you to look at the documentation and join the community on Slack.
Nowadays we often see whole dbt projects trying to denormalize data to allow a broader usages in any analytics project.
Malloy, and the semantic layer in a more general view, offers a way to denormalize on the fly. It opens the box for normalization in dbt or upstream projects, keeping all data models clean and well arranged, making high dimension and complex analytics rendering a downstream and easier task.
This whole exercise showcases how having a proper domain system language (DSL) for dealing with complex concepts is a keystone.
With Malloy for high dimension modelling and Kestra for declarative orchestration, we perceive what could be the dreamed data stack: a stack with fewer tools, each of them allowing end users to express their need in a fluid way, with proper semantics.
Indeed, a data stack with a proper user experience.
Feel free to share your vision of the perfect data experience! Reach out via Kestra Community Slack or open a GitHub issue.
If you like the project, give us a GitHub star and join the open-source community.

Stay up to date with the latest features and changes to Kestra