
Authors
Benoit Pimpaud
Benoit Pimpaud
Combining Kestra and DuckDB to create a lakehouse architecture offers a modern approach to managing data by merging the strengths of data lakes and warehouses. This significantly reduces costs and complexities.
This blog summarizes a talk I gave at the first DuckDB Meetup in Paris where I explored how DuckDB’s in-memory columnar database integrates well with the orchestration capabilities of Kestra. It also covers the transition from traditional data storage methods to the more efficient and flexible lakehouse model, and discusses the use of DuckDB within Kestra environments through best practices for building scalable, cost-effective data ecosystems.
A data lake is a storage repository that holds a vast amount of raw data in its native format until it is needed. Meanwhile, a data warehouse is a system used for structuring data and support use cases such as reporting and data analysis. It is considered a core component of business intelligence. Data warehouses are central repositories of integrated data from one or more disparate sources. They store current and historical data in one single place that are used for creating analytical reports for workers throughout the enterprise.
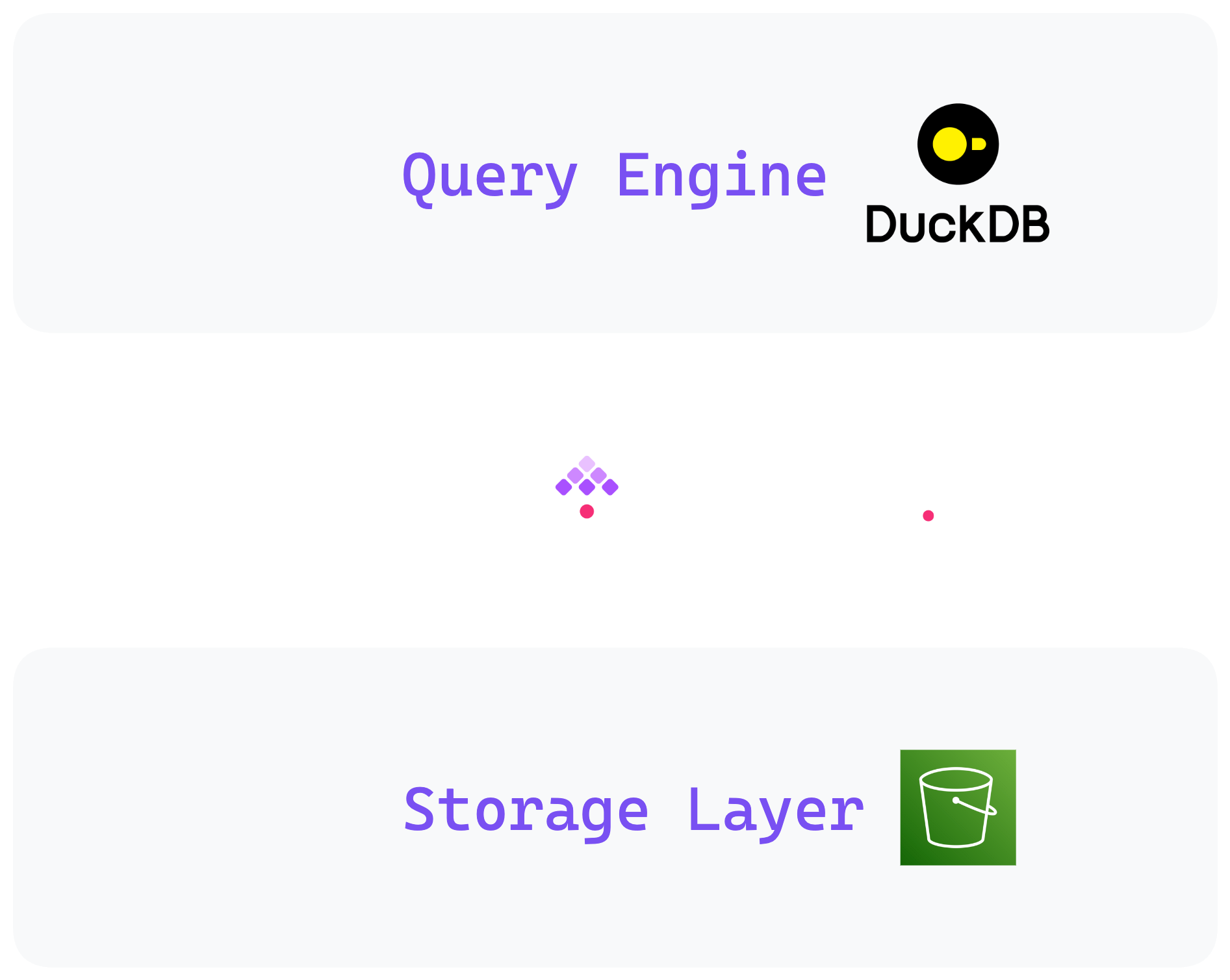
The lakehouse architecture merges the flexibility of data lakes with the structured query capabilities of data warehouses. It consists of three layers: a query engine, a transaction layer, and a storage layer.
The transaction layer introduces an abstraction over raw storage, enabling direct table-like access to raw data, facilitated by Open Table Formats such as Apache Iceberg or Apache Hudi. This design enhances analytical and operational workflows, providing ACID transactions and efficient data management within a unified platform.
To manage various data sources, applications, and infrastructure, a robust control plane is essential. Kestra aligns with the concept of a control plane by providing a centralized, comprehensive orchestration layer for managing data workflows, infrastructure, and applications. It simplifies complex operations, enabling users to define, automate, and monitor processes across different environments. This orchestration layer acts as a control plane by offering visibility and control over various components, streamlining execution, and enhancing efficiency in data-driven ecosystems.
DuckDB is considered SQLite for Analytics. It’s an open-source embedded OLAP database that can run in-process rather than relying on the traditional client-server architecture. As with SQLite, there’s no need to install a database server to get started. Installing DuckDB instantly turns your laptop into an OLAP engine capable of aggregating large volumes of data at an impressive speed using just CLI and SQL. It’s especially useful for reading data from local files or objects stored in cloud storage buckets (e.g., parquet files on S3).
This lightweight embedded database allows fast queries in virtually any environment with almost no setup. However, it doesn’t offer high concurrency or user management, and it doesn’t scale horizontally. That’s where MotherDuck can help. MotherDuck
In our exploration of DuckDB’s integration within Kestra environments, we’ve identified several layers of complexity that showcase the applications of DuckDB as the query engine for lakehouse architectures. From automating basic queries to implementing advanced data management and analytics, these levels reflect the practical scenarios and solutions our user community is actively deploying:
id: dbt_duckdbnamespace: company.team
tasks: - id: dbt type: io.kestra.plugin.core.flow.WorkingDirectory tasks: - id: cloneRepository type: io.kestra.plugin.git.Clone url: https://github.com/kestra-io/dbt-example branch: main
- id: dbt-run type: io.kestra.plugin.dbt.cli.DbtCLI runner: DOCKER docker: image: ghcr.io/kestra-io/dbt-duckdb:latest commands: - dbt run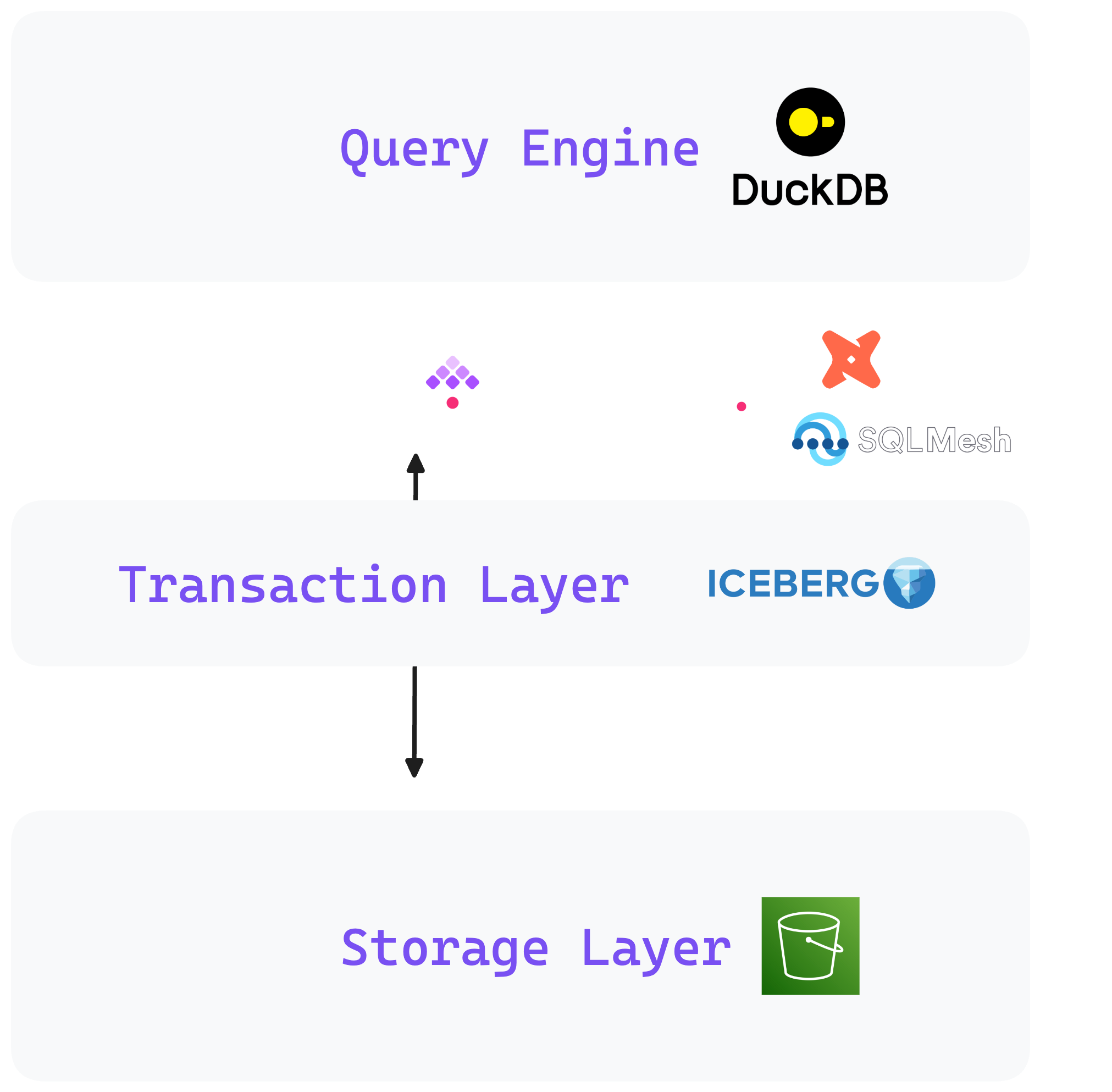
Each level progressively builds upon the last, offering more sophisticated features and capabilities, illustrating Kestra’s flexibility and power in orchestrating complex data ecosystems with DuckDB as the query engine.
This article from MotherDuck highlights a shift towards more manageable data sizes in many organizations, suggesting that large-scale distributed computing might not be necessary for all. Instead, leveraging single-node databases like DuckDB for most data scenarios—where volumes are under 10GB—offers a cost-effective, simplified approach. For tasks that demand distributed computing, tools like Databricks or BigQuery provide the necessary scale. This perspective encourages a balanced approach to data analytics, prioritizing efficiency and practicality over the pursuit of handling ever-increasing data sizes.
Having a control-plane like Kestra is key here: it allows one to manage different projects with the corresponding tools. For example having some pipelines using DuckDB as the backbone for fast and efficient small data processing while running in parallel workflows using Spark to distribute heavy data processing on several nodes. It bridges the gap between different solutions by adding dependencies management and branching opportunities, making pipelines connection a seamless task for every engineer.
While the lakehouse architecture reduces computing costs by a great factor, an equally crucial aspect is the human element of development.
Kestra’s intuitive, declarative syntax enhances productivity, enabling teams to focus more on innovation and less on the intricacies of orchestration. It facilitates the separation of business and orchestration logic through a fully managed control plane - either using a full web user interface or using code assets like Terraform resources or following GitOps patterns.
To go further between the integration of DuckDB and Kestra you can check our article on how to automate your data analyse using kestra and DuckDB or check out our article about when you need to move from DuckDB to MotherDuck
Join the Slack community if you have any questions or need assistance. Follow us on Twitter for the latest news. Check the code in our GitHub repository and give us a star if you like the project.

Stay up to date with the latest features and changes to Kestra