
Authors
Julien Legrand
Data & AI Product Owner
Julien Legrand
Data & AI Product Owner
CAGIP is the IT production entity of Crédit Agricole Group, a leading French banking and financial services company, acting as the central provider of IT services for the entire group. In the data team, we own several products that are used by different entities to host transactional, streaming or analytical data. We provide most of our solutions as a SaaS hosted on a private cloud. Expectations regarding security, regulations and high availability imply specific needs regarding infrastructure operations.
For a long time, we used Ansible & Jenkins to manage all the tasks that must be done on every of our deployments. Lately, we faced a significant scale up in the number of clusters and services that we manage. To keep up with the requirements related to hosting critical services in a banking environment, we had to: ⁃ run more infrastructure services in parallel (operating on over 50 MongoDB clusters) ⁃ optimize the consumed resources (using containers instead of virtual machines) ⁃ enhance the security (activating key rotation at scale).
We probably could have challenged our current tools, but some of us were quickly convinced by Kestra and we wanted to go much further! So, we started with a quick installation in order to check the usability of the interface and the flow syntax defined in YAML. It went well and we decided to continue with setting up the right architecture:
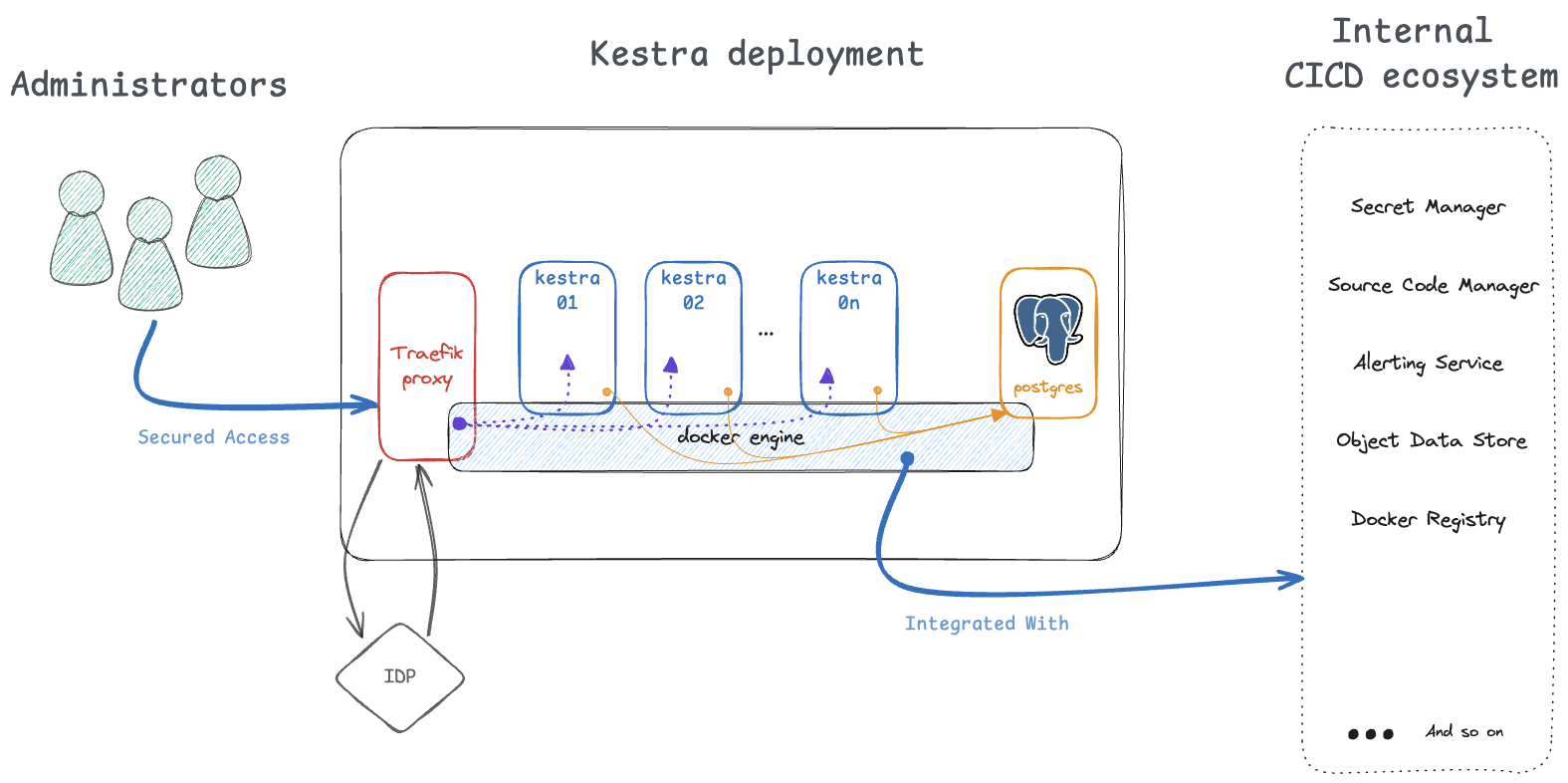
Before releasing the new tool to the teams, we wanted to define guidelines regarding CI/CD patterns and security. To do so, we prepared a few subflows simplifying the use of the solution such as Vault to store and retrieve secrets. We also tried multiple delivery patterns to agree on: development on the Kestra interface, test it in a specific namespace, then commit the flow to Git and finally use a Git Sync to make sure that each of our production flow is managed in a Git repository. Recently, we even connected it to our alerting service to get notified instantly when something goes wrong.
It tooks us time, but we are now confident to open access to the platform built on top of Kestra across our 7 data teams this fall!
We see many use cases in the future:
I’m sure that this will be just a start and we’ll soon cover more complex processes including certificates management and event-driven use cases.
As we continue to expand Kestra adoption across our operations, we’re excited to explore even more use cases in the future. If this resonates with your challenges, consider giving Kestra a GitHub star and join the community.

Stay up to date with the latest features and changes to Kestra