Authors
Benoit Pimpaud

Benoit Pimpaud
Conversations around the Analytics Stack often revolve around the assumption that everyone is using the Extract, Load, Transform (ELT) approach, with the transformation (T) happening within a data warehouse using SQL. These discussions quickly shift towards the use of dbt as the go-to tool for this process.
Tools such as dbt and SQLMesh allow for such transformations to happen directly within a cloud data warehouse.
Before dbt, most data engineers maintained hand-made SQL templating engines to operate queries on their data warehouse. dbt has emerged as a standard to help avoid reinventing the wheel and has built a wonderful community around it.
With usage growing, some users started to complain about dbt shortcomings. New tools like SQLMesh started to emerge to address these challenges.
In this blog post, we’ll delve into dbt and SQLMesh frameworks and how they need an orchestration engine to really shine.
dbt is the go-to solution for anything regarding transformation and data modeling with SQL nowadays. Some of the largest companies rely on dbt, and dbt can scale quite well, and has a great community.
Still, here are some common complaints raised by the dbt community:
Users are wondering why they need to explicitly use refs to declare dependencies between models. Other solutions often parse the SQL queries to infer the DAG of dependencies directly.
Some users are not fond of using YAML to define the model’s schema as it leads to an additional user burden without tackling the root cause of data quality issues. Columns or types often change on purpose, and a failed build due to an outdated YAML schema can lead to frustration.
While incremental models in dbt efficiently process new or updated data, backfilling only specific time range intervals can become challenging when using the “most recent records” approach.
Thousands of lines of SQL paired with Jinja macros can easily become difficult to maintain especially with complex business logic.
Scaling across multiple projects is difficult: having too many dbt projects in a single repository is often hard to manage. You often need to split your hundreds (if not thousands) of models built by different teams and projects. However, cross-project references are not possible in dbt Core. It has been discussed in previous roadmap discussions, but the final decisions have been to move it into dbt Mesh, which is part of the commercial dbt Cloud offering.
The main interface to interact with dbt is the CLI, optionally generating a static documentation website. Web UI is only available through the dbt Cloud offering.
Adding to these main shortcomings, it’s worth mentioning the analogy often made: “dbt is the Terraform for data transformation”. In my opinion, dbt is more similar to jQuery than Terraform. The biggest reason jQuery isn’t the de facto web framework today is that it was hard to scale to large teams.
The same flexibility that allowed small teams to deliver value quickly left behind messes of spaghetti code for large teams to maintain.
The introduction of React in 2013 by Facebook teams promised to address these pain points by rethinking best practices, and it has been the de facto web framework ever since.
The rapid adoption of dbt has led to the swift addition of features, which, at times, has introduced increased complexity. This raises the question of whether dbt can maintain its position as the de facto SQL framework in the long term.
At the end of 2022, ex-engineers from Airbnb, Apple, Google, and Netflix started a project called SQLMesh. Built on top of the SQLGlot library, allowing parsing and transpiling SQL SQLMesh is, like dbt, a framework to run data pipelines written in SQL. The major shift from dbt is that SQLMesh emphasizes GitOps.
SQLMesh introduces key improvements for managing SQL queries:
SQLMesh can infer query dependencies
SQLMesh facilitates the identification of all downstream consumers of a specific model, along with the impact of changes (breaking or non-breaking) on each consumer, enabling a smooth migration process.
SQLMesh leverages an “intervals approach” for incremental by-time models. This approach meticulously tracks which time intervals have been successfully processed identifies those pending execution and differentiates between completed and incomplete intervals.
While SQLMesh supports Jinja templating, it also lets the user extend the SQL language itself with native support for metaprogramming constructs that enable direct invocation of functions implemented in Python (or other programming language). This approach encourages reasoning about the code without requiring deep dives into individual macro implementations. The clear separation of Python and SQL source files contributes to a clean codebase, while Python’s inherent modularity further promotes well-organized implementation.
SQLMesh allows the creation of new environments without duplicating data. Allowing the creation of dynamic representations of the data while ensuring tables are never built more than once. Unit tests, Audits, and Data Diff provide validation throughout the development workflow.
SQLMesh provides native support for multiple repos and makes it easy to maintain data consistency and correctness even with multiple repos.
SQLMesh has different user interfaces: a web UI and a CLI. Both are included in the open-source version.
Comparing SQLMesh’s exposed commands, like sqlmesh plan, and the way it interacts with the data warehouse, it evokes a strong resemblance to Terraform’s approach. Adding UI on top is the realization that different user interfaces (Terraform being one) are important to support any user experiences.
Here is a general feature comparison between dbt and SQLMesh:
Feature Comparison: dbt vs. SQLMesh
| Feature | dbt | SQLMesh |
|---|---|---|
| Modeling | ||
| SQL models | Yes | Yes |
| Python models | Yes | Yes |
| Jinja support | Yes | Yes |
| Jinja macros | Yes | Yes |
| Python macros | No | Yes |
| Validation | ||
| SQL semantic validation | No | Yes |
| Unit tests | No | Yes |
| Table diff | No | Yes |
| Data audits | Yes | Yes |
| Schema contracts | Yes | Yes |
| Data contracts | No | Yes |
| Deployment | ||
| Virtual Data Environments | No | Yes |
| Open-source CI/CD bot | No | Yes |
| Data consistency enforcement | No | Yes |
| Native Airflow integration | No | Yes |
| Interfaces | ||
| CLI | Yes | Yes |
| UI | Yes (Cloud) | Yes (OSS) |
| Native Notebook Support | No | Yes |
| Visualization | No | Yes |
| Documentation generation | Yes | Yes |
| Column-level lineage | Yes (Cloud) | Yes (OSS) |
| Miscellaneous | ||
| Package manager | Yes | No |
| Multi-repository support | No | Yes |
| SQL transpilation | No | Yes |
Note: This table is for informational purposes only and may not reflect the latest features or capabilities of each tool. Please consult the official documentation for the most up-to-date information.
dbt Core remains the foundation of the dbt open-source project. However, recent development efforts have primarily focused on the Cloud offering. This has coincided with both pricing adjustments and a perceived slowdown in core feature development. It’s worth mentioning that dbt Cloud recently introduced column-level lineage (so only in their commercial product) built on top of SQLMesh’s open-source technology SQLGlot.
At Kestra, we have seen many users moving away from dbt Cloud because of those pricing changes and using Kestra with dbt Core to model their data and manage dependencies.
On the other side, the commercial product associated with SQLMesh is still under development and is expected to include features such as:
Even though both frameworks are extraordinary for building data transformations in ELT style, they don’t cover the full orchestration spectrum required by companies nowadays.
Data engineers often have more complex pipelines than what we see in Modern Data Stack schemas where it’s often about connecting an ingesting tool (Airbyte, Fivetran, dlt), transforming tool (dbt), and a reverse ETL tool (Hightouch, Census) or a dashboarding tool (Tableau, PowerBI, Metabase, Superset). Data teams also need notification services, custom API calls, monitoring, very specific transformations, etc.
Connecting all those tools needs a central orchestrator such as Kestra.
The following sections will demonstrate how you can easily orchestrate dbt and SQL Mesh transformations in just a few lines of YAML code in Kestra.
Using SQLMesh in Kestra is straightforward. The following example shows how you can clone a SQLMesh project from a Git repository, run it with the dedicated SQLMeshCLI task and query the results with DuckDB.
id: sqlmeshnamespace: company.teamdescription: Clone SQLMesh project and run the project, and query with DuckDB
tasks: - id: working_dir type: io.kestra.plugin.core.flow.WorkingDirectory tasks:
- id: git_clone type: io.kestra.plugin.git.Clone url: https://github.com/TobikoData/sqlmesh-examples.git branch: main
- id: sqlmesh type: io.kestra.plugin.sqlmesh.cli.SQLMeshCLI beforeCommands: - cd 001_sushi/1_simple commands: - sqlmesh plan --auto-apply outputFiles: - '001_sushi/1_simple/db/sushi-example.db'
- id: query type: io.kestra.plugin.jdbc.duckdb.Query inputFiles: data.db: "{{ outputs.sqlmesh.outputFiles['001_sushi/1_simple/db/sushi-example.db'] }}" sql: | ATTACH '{{workingDir }}/data.db'; SELECT * FROM sushisimple.top_waiters; store: true
triggers: - id: schedule type: io.kestra.plugin.core.trigger.Schedule cron: "30 6 * * *"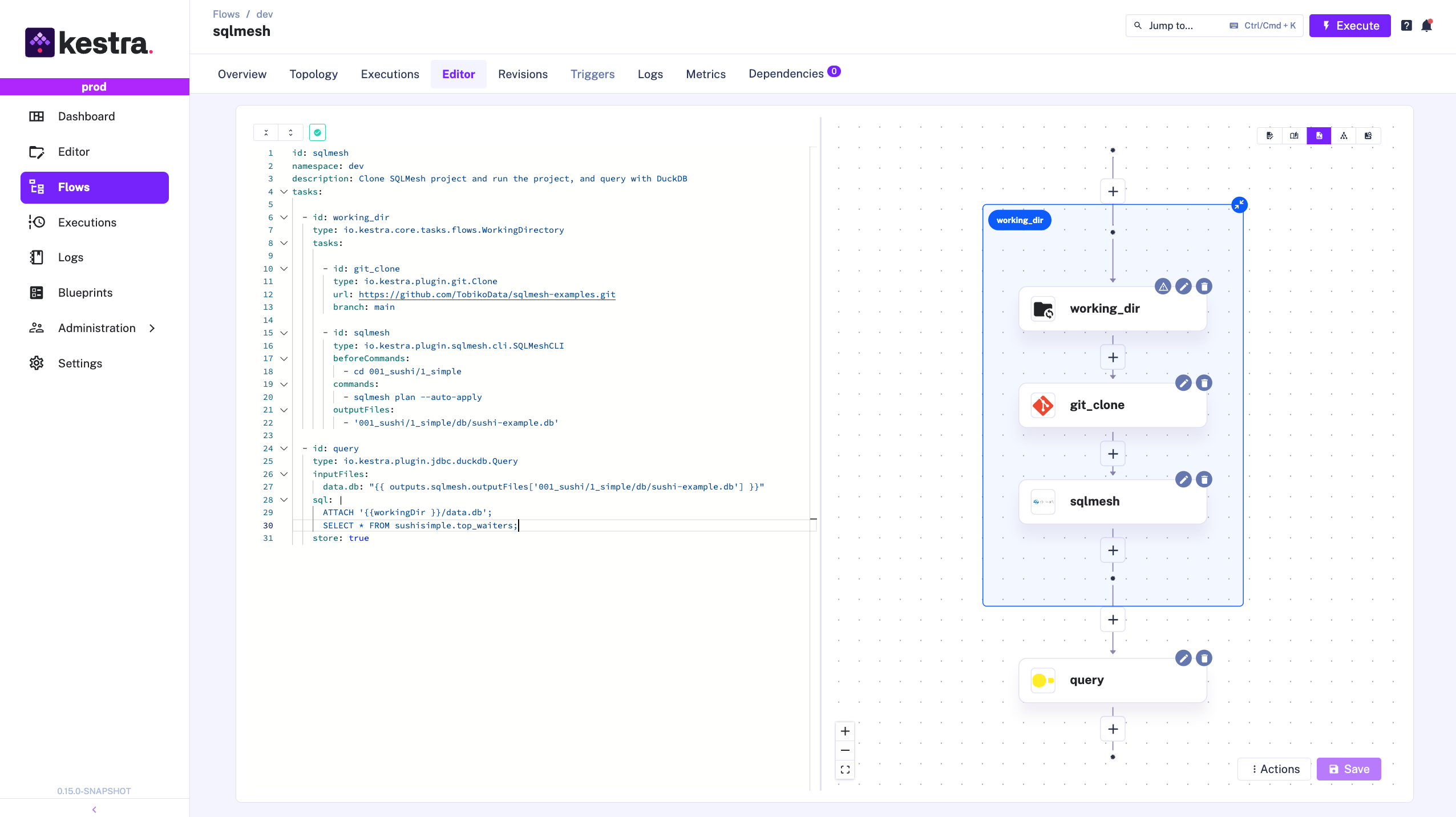
In a similar fashion, orchestrating a dbt project with Kestra can be done in few lines of YAML:
id: dbt_duckdbnamespace: company.team
tasks: - id: dbt type: io.kestra.plugin.core.flow.WorkingDirectory tasks: - id: cloneRepository type: io.kestra.plugin.git.Clone url: https://github.com/kestra-io/dbt-example branch: main
- id: dbt-build type: io.kestra.plugin.dbt.cli.DbtCLI runner: DOCKER docker: image: ghcr.io/kestra-io/dbt-duckdb:latest commands: - dbt deps - dbt build profiles: | my_dbt_project: outputs: dev: type: duckdb path: ":memory:" fixed_retries: 1 threads: 16 timeout_seconds: 300 target: devtriggers: - id: schedule type: io.kestra.plugin.core.trigger.Schedule cron: "30 6 * * *"You can find several examples of flows involving dbt and other technologies in our Blueprints library.
Highlighted by the growing number of actors in the field, there is a growing popularity in applying software practices to analytics.
When is the right time to consider switching from dbt to SQLMesh? The answer ultimately depends on the specific needs of your team and organization.
dbt has a large and active community, along with extensive documentation and readily available tutorials. This makes it an excellent choice, especially for those seeking a well-established and user-tested solution. On the other hand, if your primary concern lies in robust operational capabilities and comprehensive environment management, then SQLMesh might be a more suitable option to explore.
Are you already using dbt? Do you plan to use SQLMesh? At Kestra, we would love to hear from you. You can join the Slack community, where we’ll be happy to help you develop your data pipelines.
Checkout dbt and SQLMesh tasks on the plugin page and check the code in our GitHub repository and make sure to give us a star if you like the project.

Stay up to date with the latest features and changes to Kestra