Authors
Benoit Pimpaud
Benoit Pimpaud
In a nutshell, business logic is the part of your code that dictates how data is created, stored, changed, and managed according to specific business rules. It involves various operations, like downloading data from different sources, storing it correctly, and processing it to fit the needs of your application.
Business logic isn’t straightforward. It’s shaped by factors like company practices, team preferences, or the available tools, and it’s subject to change due to new projects, leadership shifts, or when combining data from different sources.
We often strive to write clean, logical code. But in reality, customer requirements can sometimes involve incomplete or conflicting information. These real-world complexities, often referred to as “business logic”, require collaboration between programmers and business stakeholders to ensure the final code aligns with the desired outcome.
This below example shows how we can map some fields between some source files and expected format in Python. Here it’s a dummy example, but this kind of code often contain crucial logic that encode business understanding and need.
def map_json_fields(source_data, mapping): mapped_data = {} for target_field, source_field in mapping.items(): if source_field in source_data: mapped_data[target_field] = source_data[source_field] else: # Handle missing source fields (optional) mapped_data[target_field] = None # Example: Set to None if missing
# Enrich the name with a fake middle name (optional) if "name" in mapped_data and mapped_data["name"] is not None: first_name, last_name = mapped_data["name"].split() if " " in mapped_data["name"] else (mapped_data["name"], "") middle_name = get_middle_name_from_gov_api() # function that gather middle names provided by a governament service API mapped_data["name"] = f"{first_name} {middle_name} {last_name}"
return mapped_data
# Example usagesource_json = { "customer_id": 123, "first_name": "John", "last_name": "Doe", "full_name": None # Not present in source JSON}
# Mapping dictionary defines the desired field namesmapping = { "user_uuid": "customer_id", "name": "full_name", # Map to "full_name" even if missing in source "surname": "last_name"}
mapped_data = map_json_fields(source_json.copy(), mapping)print(mapped_data) # Possible output: {'user_uuid': 123, 'name': 'John David Doe', 'surname': 'Doe'}The code we write isn’t for the computer. It’s for us. It’s for humans.
If the coding language was meant for the computer, we would all be writing in pure binary instead of these abstract and symbolic languages. The code is the interface that we designed to be able to program the computer.
One of the key reasons Python is so widely used is its readability. It’s at the same time so close to English while being objective, explicit, unambiguous, (relatively) static, internally consistent, and robust.
Trying to specify a piece of software in English would be a proper nightmare. This is often the first part of every software project: we do our best to describe it in natural language first so that developers, product managers, and business stakeholders are on the same page. Ultimately, our human specification falls short. There are all these considerations, technical details, compatibilities, versions, integrations, real-world data, and so many other things we have to worry about.
The hardest part of programming isn’t writing the basic code. It’s understanding the problem we’re trying to solve, reading instructions (documentation), and figuring out the data we are working with. The real skill is knowing how to tackle the unique twists and turns of each specific problem, not memorizing how to set things up.
That’s why Python is so popular - it’s easy to learn and understand, almost like reading plain English. Its smooth learning curve lets us bridge the gap between our natural language needs and the actual code the computer understands. It’s like a shortcut from idea to reality!
In computer science, there’s a trade-off between programmer friendliness and performance. Languages closer to the machine code - the ones and zeros - run faster, but they’re also much harder for humans to understand and write. This is because high-level languages, which are closer to natural language, offer features and abstractions that make them easier to use, but these features can sometimes come at the cost of some speed.

The tension in this duality is often a matter of context. Building robust software that will handle high levels of concurrency and need high availability will often be written in lower-level languages such as C++ or Java. On the contrary, when we want to make the code easy to understand and easy to replace, we might choose a language closer to our natural language. It will be accessible to a broader range of profiles and match a broader scope of needs.
It’s also important to remember that higher-level programming languages act like a user-friendly interface on top of the complex software built with lower-level languages. Even though we write code in these higher-level languages, the actual work of manipulating ones and zeros happens behind the scenes on the server or database, using lower-level technologies.
This is often the case with the great set of libraries developed in Python, using C or C++ bindings for performances.
A broad set of Python frameworks has been developed to cover almost every aspect of computer sciences: from bioinformatics, array manipulation, and machine learning, to web server handling, queues management, etc. It makes Python probably the best language to write any logic that we want easy to understand and maintain.
With Kestra we’re definitely in the same mindset: we’ve built our DSL with YAML - an even simpler markup language to describe workflows. We have made the realization that orchestration logic is tied to basic concepts:
Using YAML enables language-agnostic declarative orchestration. As mentioned above, we can’t rely on a single programming language to handle all our computing tasks. Enabling a company-wide orchestration platform requires a language that is easy to learn and that can be simultaneously used by engineers across different tech stacks and domain experts with no programming experience.
Being language-agnostic has the advantage of letting the business logic be described in any language. In this advent, mixing the declarative semantics of YAML with the freedom of Python is probably the best mix to create smart and scalable workflows.
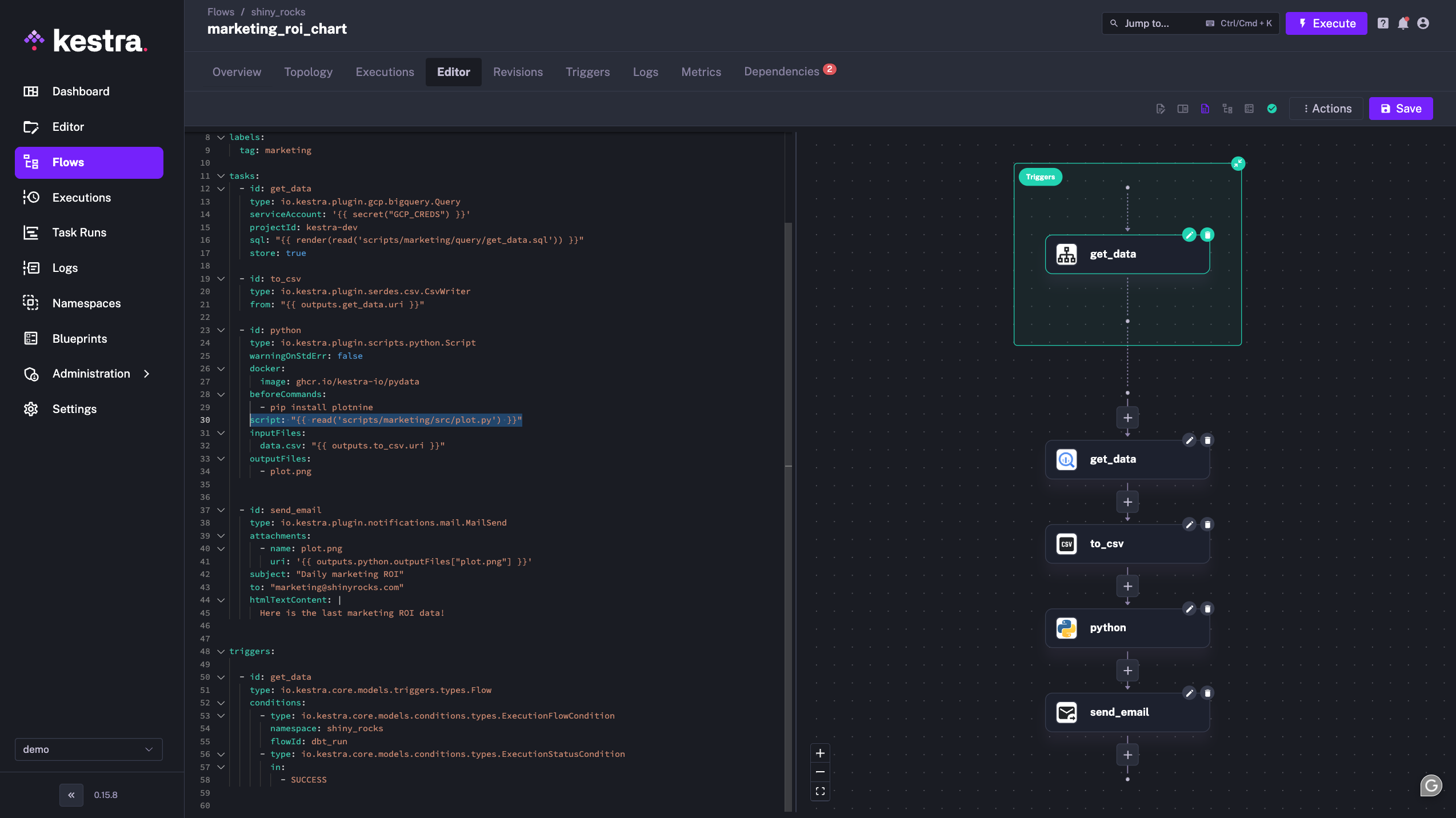
With Kestra, we’ve built several features to allow developers to handle their Python codes while making the orchestration of it seamless.
For example, Kestra allows to pull of Git repositories containing a whole Python project. Then it’s easy to run Python main commands and describe the orchestration of scripts easily.
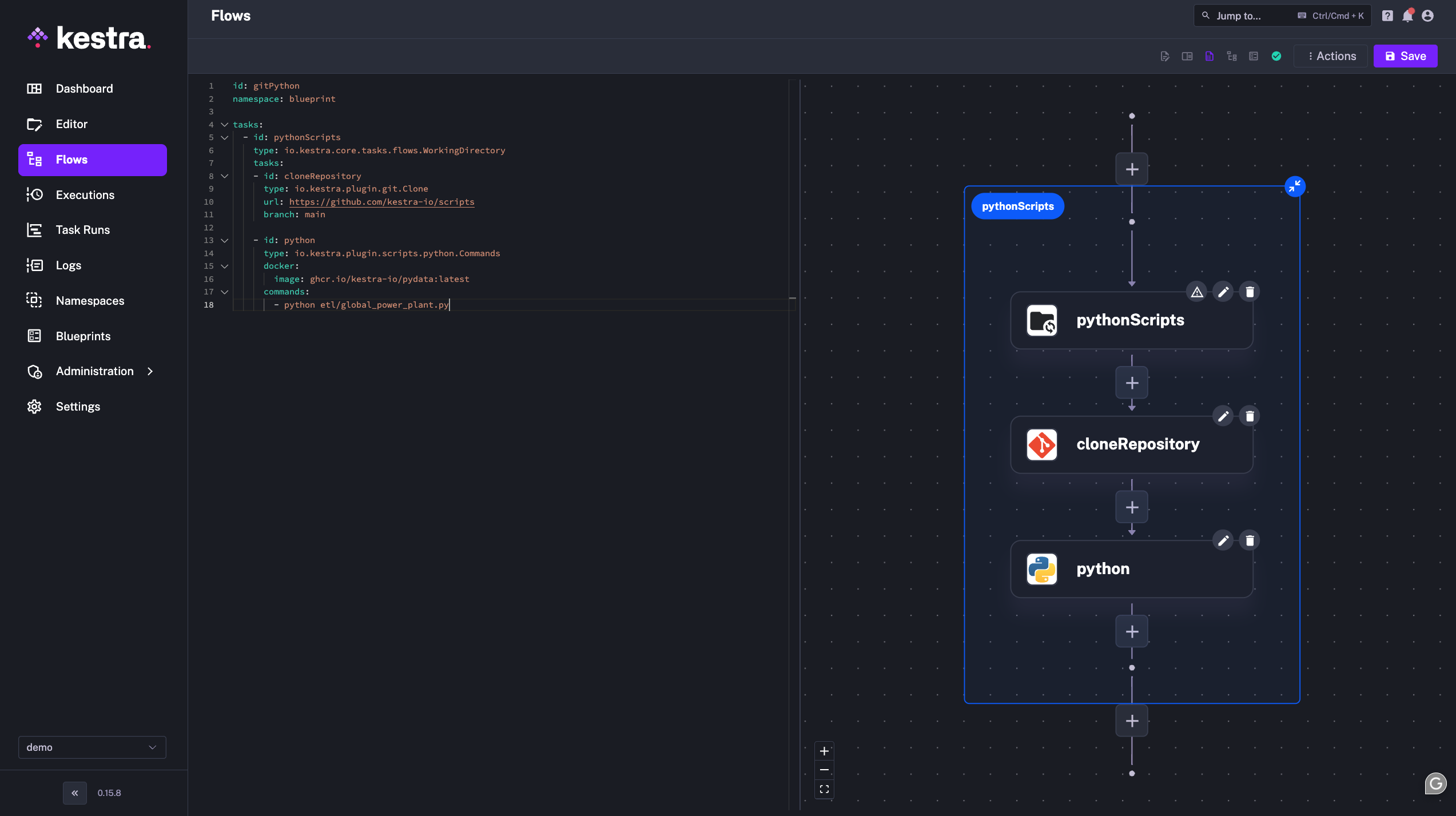
We even went further by allowing to write Python scripts directly in an embedded Code editor, while connecting these scripts easily in the orchestration logic.
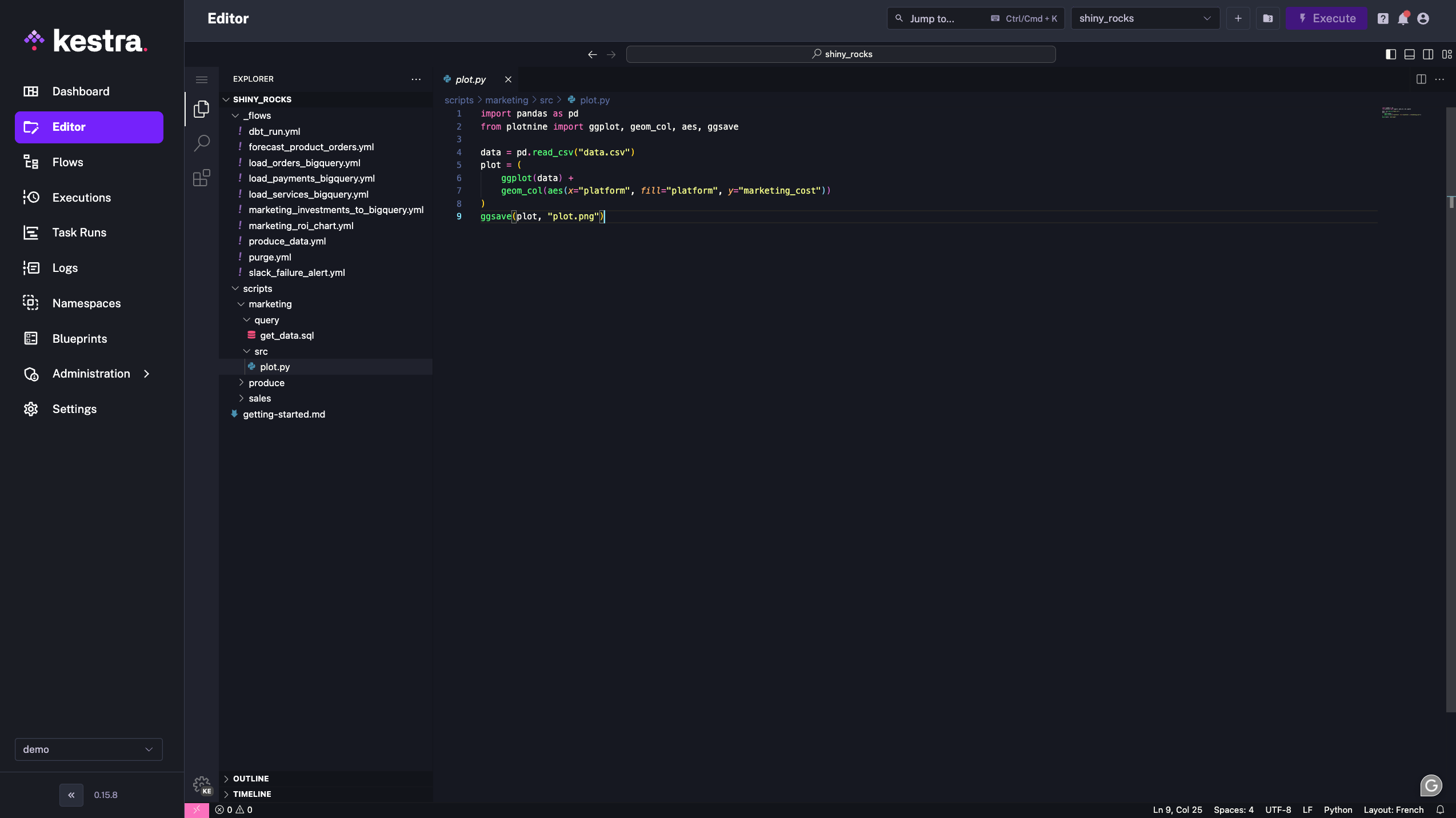
The time to value is one of the most important indicators of engineer productivity. As engineers our goal is to automate the mundane. This allows us to focus our expertise on solving intricate system problems and developing innovative projects with high business value.
If our system doesn’t allow us to sit and wait for completion to focus on something more important, we are missing something. Data engineers are not used to their full potential when writing the same code over and over, dealing with the same data issues, and creating new templates again and again. Stacking decorators on top of decorators. This is not really an engineering job, is it?
The outcomes we should look for are automation at its full potential and optimized engineering costs.
Most of the time we just want to trigger those docker container runs. To launch this python main.py command. To trigger them and manage the dependencies that come before and after the execution. That’s it.
Managing the underlying business logic is not out of the scope here. It’s about uncoupling stuff from each other. Making simple inputs and outputs definitions here is the key to making things flow seamlessly.
That’s why Kestra comes with simple declarative statements to deal with inputs, outputs, and globally speaking metadata arising from orchestrating dependencies between one job and another.
As engineers, we’re like Lego builders who’ve already molded the plastic bricks. Once we pass that stage, we just want to grab the polished blocks and start assembling the system that unlocks the real value of the data for the business.
Are you using Python in your worfklows? We would love to hear from you: join the Slack community if you have any questions or need assistance.
Follow us on Twitter for the latest news. Check the code in our GitHub repository and give us a star if you like the project.

Stay up to date with the latest features and changes to Kestra