Authors
Anna Geller
Product Lead

Anna Geller
Product Lead
Many trends that began shaping data engineering in 2024 continue to affect data teams in 2025. AI keeps accelerating, and data lakes—along with open table formats—are more popular than ever. Below is our take on the trends influencing data engineering and AI today, and how they impact data professionals.
Last year’s prediction that AI would turn data teams from cost into profit centers hasn’t played out as expected. While generative AI is delivering measurable productivity gains, its impact on revenue generation remains limited outside hyperscalers and niche applications.
Coding assistants (e.g., Cursor, GitHub Copilot) accelerate development, while AI chatbots and search tools streamline workflows—enabling teams to achieve more with fewer hires.
Tech giants (Nvidia, AWS, Azure, Google) and LLM vendors profit from selling shovels in this gold rush, but most industries use GenAI to trim operational costs rather than create new income streams. For example, many deploy chatbots to cut support expenses, not to monetize the bots themselves.
Many data teams in 2025 are experimenting with agentic AI – systems that plan tasks and make decisions autonomously. These AI agents can break tasks into smaller steps, execute them, and interact with other tools.
That said, current agents still struggle with complex tasks. When faced with ambiguity or multi-layered problems, they might misinterpret context, hallucinate or continue running endlessly without knowing when to stop.
The next wave of improvements will likely focus on two areas: more robust frameworks to balance agent’s autonomy with control, and new models with built-in inference time computation, letting AI dynamically adjust its processing depth based on problem complexity. Techniques like chain-of-thought reasoning (where models explicitly outline their logic) show particular promise. We already see exciting developments in this field in early 2025 with open-source models such as DeepSeek-R1.
The scale of model sizes continues to diverge. On one end, the big LLM providers, such as OpenAI, build their own data centers to power enormously large models which soon might reach trillions of parameters. Those LLMs can solve broad, complex problems. On the other end, small models (many of which are open-source) can run on laptops or phones and are perfect for specialized tasks. Both approaches broaden how (and where) data teams can deploy generative AI.
Modern models can now also retain entire conversations or documents in memory. The latest Gemini models, for example, handle up to 1 million tokens. While this reduces reliance on retrieval-augmented generation (RAG) for basic tasks, most teams will still use RAG for two reasons:
These LLM advancements, paired with autonomous agents, enable new use cases like:
But the risks scale too. Larger context windows could inadvertently memorize sensitive user data, while smaller models’ accessibility lowers the barrier for spam campaigns or targeted disinformation.
The EU AI Act entered force in August 2024, with strict rules for high-risk AI systems (e.g., hiring tools, credit scoring) taking full effect by August 2026. This forces teams to rethink data practices in 2025 in two key areas:
1. Fighting Bias at the Source — AI systems must now document training data origins and implement bias safeguards. Teams need audit trails showing exactly how data moves from raw sources to model inputs.
2. Granular Control — Article 10 requires tracking who accesses sensitive data and why. Apache Iceberg’s merge/delete capabilities can help satisfy GDPR’s right to be forgotten, while integrations with AWS Lake Formation enable column-level permissions. With orchestration tools like Kestra, you can add compliance to your data workflows through built-in custom RBAC, SSO, SCIM, audit logs, outputs and metrics tracking, and manual approval features.
As more AI and data workloads enter production, cloud costs rise. Data leaders keep a closer eye on how often they run jobs and how much storage they consume. Hidden costs like data egress, idle services, or frequent transformations can add up fast if not closely monitored. Open table formats and smarter data orchestration with on-demand compute (like Kestra’s task runners) can help cut costs.
Cost optimization continues to drive renewed interest in data lakes, with teams combining open table formats like Apache Iceberg with object storage to balance governance and flexibility. The architecture often leverages Parquet files for columnar storage, while Iceberg’s metadata layer adds critical features:
This setup allows teams to query data directly in object storage using engines like DuckDB (ad-hoc analysis), chDB (lightweight aggregations), or Polars (complex transformations/index.md). While data warehouses remain common for managing mission-critical curated data marts, the trend favors open hybrid lakehouse architectures with Iceberg at the core. Notably, major platforms like Databricks and Snowflake now also support Iceberg, reducing vendor lock-in risks as teams prioritize interoperability alongside cost control.
The database world’s “Swiss Army knife” keeps getting sharper. In 2025, PostgreSQL isn’t just competing with specialized databases – it’s absorbing their capabilities through a thriving ecosystem of extensions and integrations. Three trends define this evolution:
pgvector) and direct querying of data lakes (ParadeDB’s pg_analytics) let teams build RAG and analyze Iceberg tables and S3 data without leaving PostgreSQL.The 2024 Stack Overflow survey found 49% of developers now use PostgreSQL – surpassing MySQL for the first time. This growth stems from its ecosystem-first strategy: instead of forcing users to adopt new tools, PostgreSQL integrates them, becoming what many call the Linux of databases – boringly reliable, and infinitely adaptable.
Source: Postgres is eating the database world
Even though many developers love PostgreSQL, migrating databases or moving workloads between on-prem and cloud still takes a lot of work due to existing dependencies on proprietary systems. Data gravity is a powerful force, and legacy applications often can’t just be swapped out the same way as modular components of a Modern Data Stack. As a result, many data engineering teams stay on older platforms for years, despite the appeal of modern technology.
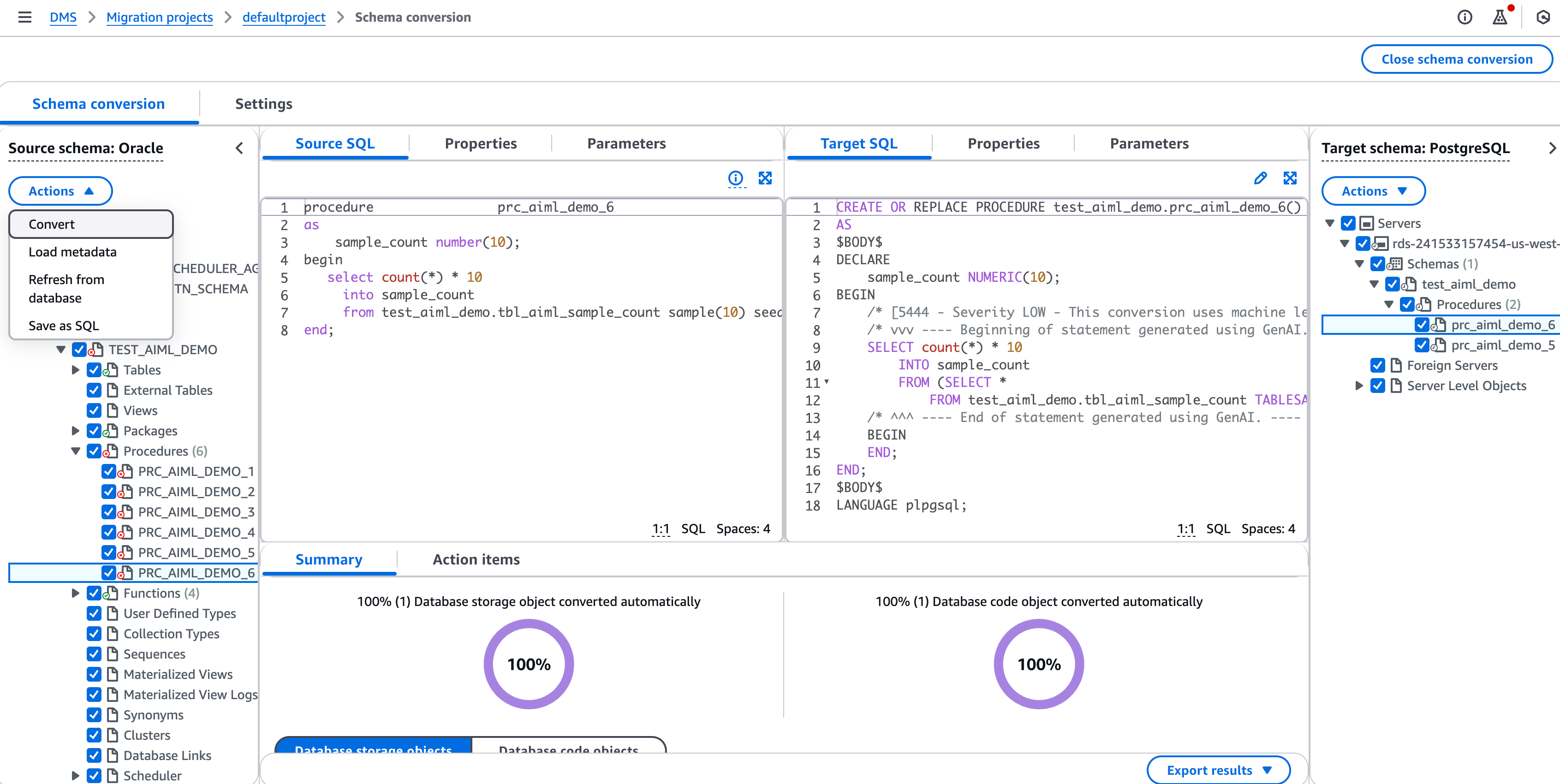
There’s a bright spot, though. AI is starting to make certain migrations much easier. AWS Database Migration Service (DMS) now uses generative AI to automate many of the time-consuming schema conversion tasks needed to move from commercial databases like Oracle to PostgreSQL. It won’t handle every edge case—proprietary functions and special data types can still be tricky—but it can significantly reduce the pain of database migration. This is a welcome trend for data engineers who typically face long, painstaking processes to convert and migrate data manually.
Some large tech companies like Salesforce have declared they will hire no new software engineers in 2025. Meta’s CEO has even suggested that AI might replace entire layers of mid-level software engineers soon. AI-based tools for writing code, building prototypes, generating tests, and automating documentation make it possible to move faster with smaller teams.
Yet this doesn’t signal engineering’s decline—it’s a recalibration. Jevons’ Paradox plays out here: as AI lowers the cost of basic coding, demand for experienced senior engineers grows.
Companies face a proliferation of specialized data tools. To combat this complexity, teams are consolidating workflows into unified platforms—a trend often called platformization. Modern data orchestration now spans real-time streams, dynamic ML pipelines, and enterprise automation, going far beyond traditional batch ETL.
Open-source platforms like Kestra exemplify this shift by unifying:
You can orchestrate workflows as code or configure them in the UI, using any language or deployment pattern. This consolidation reduces the overhead of maintaining disparate tools while accelerating development. Teams can collaborate on a single system instead of juggling siloed point solutions for scheduling, transforming, and automating data workflows.
Generative AI now powers many BI dashboards. Instead of manually creating every report or writing SQL queries from scratch, analysts can describe what they need in plain language. Tools like Databricks Assistants, Snowflake Cortex, Microsoft Fabric, or Amazon Q in AWS QuickSight help generate polished visuals automatically thanks to integrated AI copilots.
Still, human oversight is critical. AI can jumpstart a chart or query, but domain expertise is needed to confirm correctness or adjust misinterpreted metrics.
Generative AI continues to help data teams work more efficiently. Many routine tasks—like writing transformation code, unit tests, or basic ETL pipelines—can be sped up by AI-driven coding assistants. This frees data professionals to focus on more strategic projects, such as designing cost-effective data architectures and building data platforms to enable less technical stakeholders to build data pipelines in a self-served manner.
These changing roles also call for more unified tooling. Open-source solutions like Kestra bring orchestration across data pipelines, microservices, infrastructure, and analytics workflows under one roof, helping teams move faster with less complexity.
As the data field continues to evolve, staying adaptable, embracing automation, and relying on proven patterns can help teams thrive. Data professionals who focus on domain expertise and stakeholder collaboration will do well in 2025 and beyond.
We’d love to hear your thoughts. Are these trends shaping your data stack? Join the Kestra community and share your perspective—or suggest a trend we might have missed.
If you want to learn more about Kestra, check out our documentation or request a demo, and if you like the project, become our next star on GitHub.

Stay up to date with the latest features and changes to Kestra