
Authors
Elliot Gunn
Product Marketing Manager
Elliot Gunn
Product Marketing Manager
Every workflow orchestrator has the same thing to figure out: how do you keep the layer that defines what should run separate from the layer that actually runs it? When those layers bleed together, the framework ends up inside your code. Decorators on your functions, imports that only exist for the scheduler, conventions you have to memorize before you can read someone else’s pipeline.
Python-based orchestrators answered this by putting orchestration logic and execution code in the same language, often the same files. Asset-centric models have tried to undo it from the inside, expressing orchestration intent in Python without actually running as Python. The result is Python code that’s trying very hard not to be Python code.
This asset-centric correction points to the same conclusion infrastructure and analytics tooling already reached: the coordination layer needs to be separate from the execution layer. YAML enforces that separation. Python, by design, doesn’t.
The first generation of modern data orchestrators made a reasonable bet on Python. Data engineers write Python, so orchestration should be in Python: define a DAG as a module, wire tasks with operators, let the framework handle scheduling.
That bet paid off for adoption, but it didn’t pay off for the orchestration layer itself, because orchestration is a configuration problem, not a programming one: run this task, then that one, retry on failure, alert on error, respect a schedule. That’s a data structure, not a program. Expressing it in a general-purpose language means every workflow carries the overhead of imports, decorator patterns, operator overloading, and framework-specific conventions that don’t serve the workflow.
The difference is easier to see than to explain. The same ETL pipeline, in YAML and Python:
id: etl_pipelinenamespace: company.data
tasks: - id: extract type: io.kestra.plugin.scripts.python.Commands containerImage: python:3.11 commands: - python extract.py
- id: load type: io.kestra.plugin.scripts.python.Commands containerImage: python:3.11 commands: - python load.py
triggers: - id: schedule type: io.kestra.plugin.core.trigger.Schedule cron: "0 6 * * *"The YAML has none of that overhead. The Python version requires decorator patterns, operator overloading (>>), framework-specific imports, and the implicit convention that calling etl_pipeline() at module scope registers it with the scheduler.
from some_orchestrator import dag, task, schedule
@dag(schedule="0 6 * * *")def etl_pipeline():
@task(image="python:3.11") def extract(): import subprocess subprocess.run(["python", "extract.py"])
@task(image="python:3.11") def load(): import subprocess subprocess.run(["python", "load.py"])
extract() >> load()
etl_pipeline()None of that serves the goal of running extract, then load, on a schedule. It serves the framework.
When Python is your orchestration language, your task code runs inside the framework’s execution environment. The framework owns imports and controls execution context. If you want to run a Bash script or a Node.js function, you go through the framework’s abstractions for it. The orchestration layer and the execution layer share a runtime, which means changing one touches the other.
YAML severs that connection: the workflow definition is pure configuration, and tasks are external processes the orchestrator invokes and monitors without owning. Your Python script, R model, or Java service runs in its own container, exactly as it was written. The orchestrator coordinates execution without participating in it.
That separation is visible in Kestra’s editor itself: YAML on the left, the live DAG topology on the right:
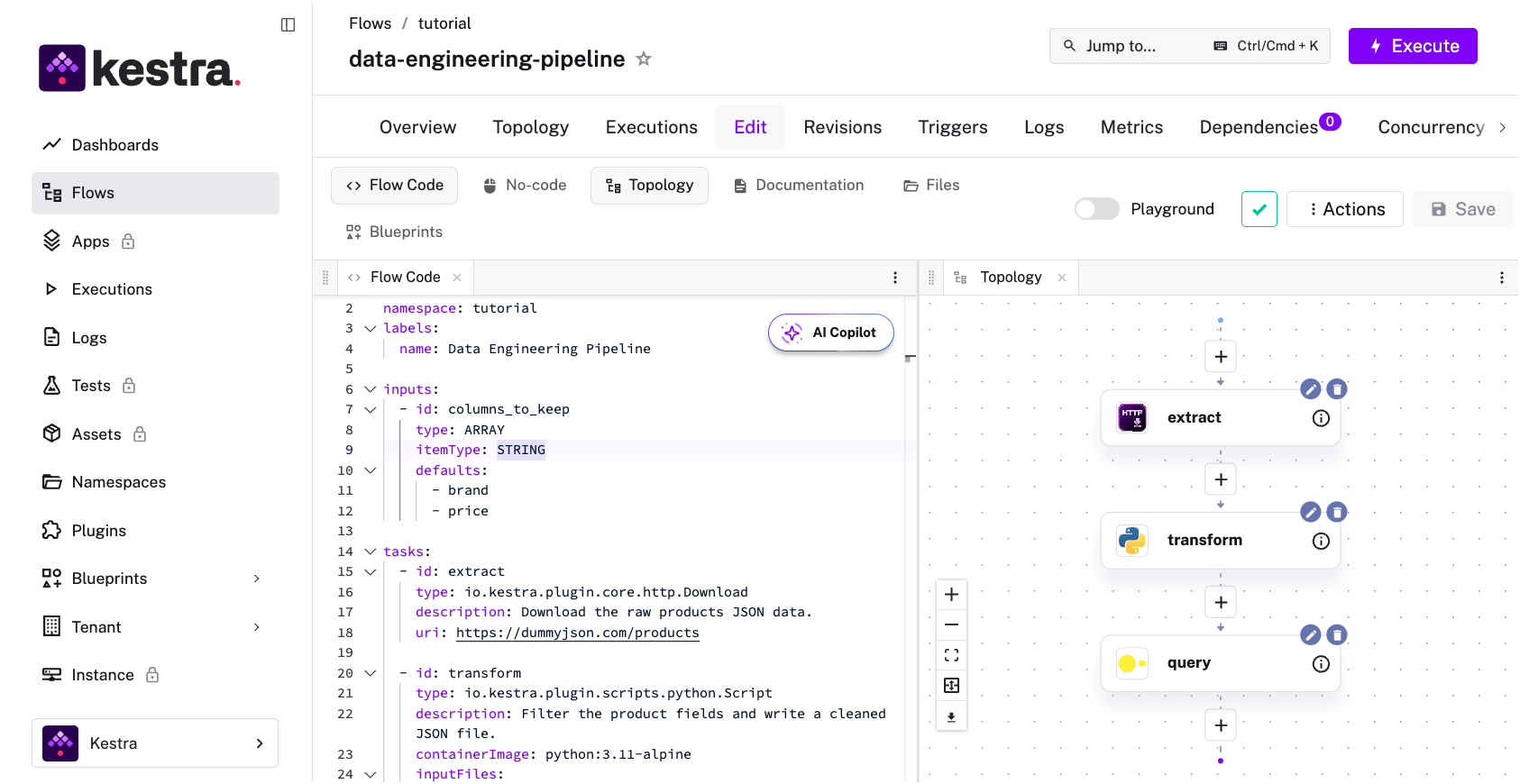
Asset-centric models tried to fix this from the inside. Instead of “run task A, then task B,” you define the data assets (tables, models, datasets) that should exist and let the framework figure out what needs to run to produce them. The dependency graph comes from the assets rather than being manually declared.
A task graph says “do this, then do that;” an asset graph says “this thing should exist and be fresh.” The latter is more aligned with what the business actually cares about, which is not whether extract.py ran at 6am but whether the revenue table is current.
This has now become common across the category, from newer frameworks to incumbents like Airflow, which added Assets in version 3.0. But every implementation made the same tradeoff: assets are still defined in Python. An asset definition is a Python function decorated to be both a compute function and a data contract. The orchestration metadata (what this asset is, what it depends on, how to materialize it) lives in the same object as the execution logic. They can’t be separated because they’re expressed in the same language.
Every implementation reached for declarative thinking but stayed in Python. The result is Python code that’s trying not to be Python code: decorators that suppress function behavior, return types that are really metadata annotations, and import structures that exist for the framework’s dependency resolution rather than for the code’s execution.
The asset model also runs into a scope problem. It works well when the thing being orchestrated is a table that should exist and be fresh. It’s less natural for infrastructure provisioning, API coordination, file processing, or business process automation, where “materializable asset” doesn’t map cleanly. As orchestration scope expands beyond data pipelines (and it is rapidly expanding, thanks to AI), the asset abstraction starts to strain.
YAML-first orchestration already handles asset-like semantics without these constraints. Kestra’s assets let you declare inputs and outputs directly on each task:
tasks: - id: transform type: io.kestra.plugin.jdbc.duckdb.Query assets: inputs: - id: raw_events type: io.kestra.plugin.ee.assets.Table outputs: - id: staging_events type: io.kestra.plugin.ee.assets.Table metadata: model_layer: staging owner: data_teamThe lineage graph builds automatically as workflows execute, tracking which resources each task consumes and produces. The same mechanism works for database tables, files, datasets, and infrastructure resources like S3 buckets or VMs. Thinking in terms of desired state rather than execution steps is the right model. Requiring Python to express that model is the part that doesn’t hold up.
Infrastructure went through the same shift a decade ago. Terraform and Kubernetes proved that declarative configuration handles heterogeneous systems better than imperative code. You don’t write a program that provisions a VM, attaches a disk, and configures networking in sequence. You declare the desired state and let the system reconcile. The infrastructure-as-code (IaC) movement converged on declarative formats (e.g., HCL, YAML) for the same reason orchestration is converging now: the coordination layer benefits from being separate from the execution layer.
At the transformation layer, dbt made the same bet. Analytics engineers write SQL, YAML handles the metadata: dependencies, tests, documentation, scheduling. The execution layer (SQL) and the orchestration layer (YAML) are explicitly separate, and that separation is why dbt could be adopted by analytics engineers who had no interest in learning a new programming framework.
When a domain matures past the point where one team writes all the code, separating the coordination layer from the execution layer is what makes the ecosystem scale. Declarative configuration wins because it’s the natural format for that coordination layer: readable by people who didn’t write it, parseable without a runtime, and decoupled from whatever executes underneath.
Python orchestration restricts workflow ownership to people who know Python and the framework’s specific abstractions. Those are two separate bars. Knowing Python fluently doesn’t mean you can read a pipeline built in an unfamiliar framework’s DSL. A YAML workflow definition sidesteps both: the analytics engineer who writes SQL, the platform engineer who manages infrastructure, the data scientist who needs to understand why their model retraining job failed on Tuesday without standing up a Python environment to trace it.
That exclusion compounds as orchestration scope grows. When workflows handled just data pipelines, the audience was data engineers who already knew Python. Now that orchestration covers infrastructure automation, API coordination, and business processes, the people who need to read and own workflows are no longer a single-language community. A format that requires Python literacy to participate in orchestration is a format that excludes most of the people who depend on it.
The Python orchestration ecosystem is already signalling the shift. Two recent examples: one open source project lets platform teams define reusable task group logic in Python while analysts and data scientists compose workflows entirely in YAML; a separate framework shipped YAML-first pipeline configuration, making defs.yaml the primary mechanism for defining reusable pipeline components. In both cases, the separation that YAML enforces by design is being retrofitted into Python orchestration as a workaround.
If the ecosystem is building the separation anyway, the question then becomes: why not start there?
YAML is also far easier for AI to generate correctly than Python-based DAG definitions.
In a YAML workflow, every task’s type, properties, and relationships are visible in the structure itself. An LLM can validate the output against a schema without executing anything. But a Python orchestration DAG, with its decorators, operator overloading, and implicit registration conventions, is much harder for an LLM to generate correctly because the semantics aren’t visible in the syntax. The framework conventions that make Python DAGs work for human developers are exactly what makes them brittle for AI generation.
In practice, this means you can describe a workflow in plain language and get paste-ready YAML. Kestra’s agent-skills validates every task type and property against a live schema before generating output:
“Write a flow that polls a REST API every 30 minutes, stores the result in KV store, and sends a Slack message if the response code isn’t 200.”
id: api_health_checknamespace: company.monitoring
tasks: - id: poll_api type: io.kestra.plugin.core.http.Request uri: https://api.example.com/health method: GET
- id: store_result type: io.kestra.plugin.core.kv.Set key: api_health_status value: "{{ outputs.poll_api.body }}"
- id: check_status type: io.kestra.plugin.core.flow.If condition: "{{ outputs.poll_api.code != 200 }}" then: - id: alert type: io.kestra.plugin.slack.SlackIncomingWebhook url: "{{ secret('SLACK_WEBHOOK') }}" messageText: | API health check failed Status code: {{ outputs.poll_api.code }} Response: {{ outputs.poll_api.body }}
triggers: - id: every_30_min type: io.kestra.plugin.core.trigger.Schedule cron: "*/30 * * * *"The formats that are easiest to generate and validate are the ones AI will default to. YAML clears both bars: structure encodes semantics, and every task validates against a schema without executing anything.
If you’re following the argument but rusty on YAML syntax, here’s the minimum you need. YAML has five concepts:
Key-value pairs: key: value. The space after the colon is mandatory.
Nesting: Indentation creates hierarchy. Use spaces, never tabs. Two spaces per level is the convention.
Lists: A dash followed by a space marks each item. List items can be simple strings or complex objects.
Multi-line strings: | preserves line breaks (useful for shell scripts and SQL). > folds lines into a paragraph.
Comments: # comments out the rest of the line.
The most common parse errors: tabs instead of spaces, missing space after colon, and unquoted special characters (:, #, {, }). YAML 1.1 also parses NO, yes, on, and off as booleans, so country codes and feature flags need quotes.
For a complete reference, including boolean edge cases and Kestra-specific patterns, see the YAML basics guide.
If you want to see the argument in action — including how AI generates production-ready YAML workflows and what hands-on orchestration looks like end to end — Benoit, Kestra’s product manager, and Will, developer advocate, covered exactly this in a recent webinar:
The orchestration layer and the execution layer were always meant to be separate. YAML is what happens when you build that separation in from the start, rather than retrofitting it later.
The best way to pressure-test this argument is to read a few real workflows. If the separation of orchestration and execution is real, it should be obvious in the YAML.
type field, an id, and configuration properties. Once you know the syntax, every plugin works the same way.
Stay up to date with the latest features and changes to Kestra