All things Kestra.
The latest updates, guides and stories
Subscribe to updates.










































































































































Latest Community News



Video Tutorials

Feature Highlight • March 31 2026 • Kestra
Meet Kestra: The Unified Orchestration Platform for All Engineers

Deep Dive Tutorials • March 27 2026 • Kestra
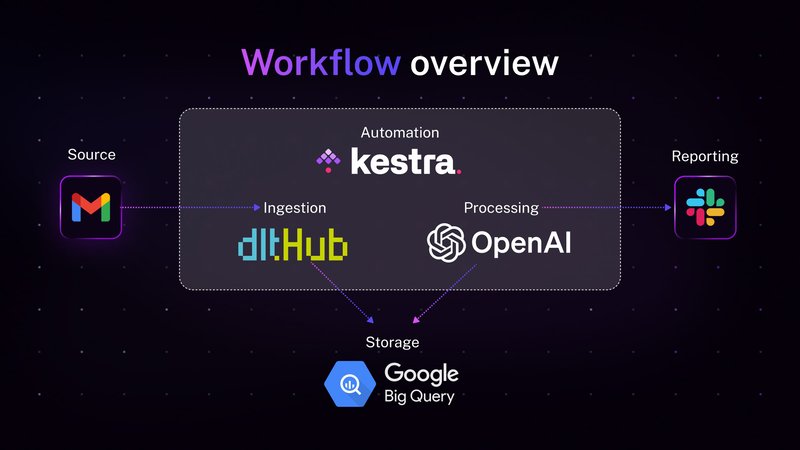
Migrate or Upgrade? Airflow 2 EOL

Feature Highlight • March 24 2026 • Kestra
What Are Agent Skills? (And Why You Should Build Your Own!)

Get Kestra updates to your inbox
Stay up to date with the latest features and changes to Kestra