 Configuration
Configuration
Configuration Reference for Kestra.
Almost everything is configurable in Kestra. This section describes the different configuration options available to Administrators.
Kestra configuration is a YAML file that can be passed as an environment variable, a file, or added directly in the Docker Compose file depending on your chosen installation option. The configuration is intended to hold deployment-specific options and it's divided into different sections, each corresponding to a different part of the system:
datasources:
postgres:
url: jdbc:postgresql://postgres:5432/kestra
driverClassName: org.postgresql.Driver
username: kestra
password: k3str4
kestra:
server:
basicAuth:
enabled: false
username: "[email protected]" # it must be a valid email address
password: kestra
repository:
type: postgres
storage:
type: local
local:
basePath: "/app/storage"
queue:
type: postgres
tasks:
tmpDir:
path: "/tmp/kestra-wd/tmp"
url: "http://localhost:8080/"
Injecting OS environment variables is also a possible way to configure Kestra. These environment variables take precedence over configuration files that have been loaded.
To populate an environment variable with the right property, replace any special characters with _ (underscore). Below is a comprehensive table on how properties can be translated in variables.
| Configuration Value | Resulting Properties |
|---|---|
| MYAPP_MYSTUFF | myapp.mystuff, myapp-mystuff |
| MY_APP_MY_STUFF | my.app.my.stuff, my.app.my-stuff, my.app-my.stuff, my.app-my-stuff, my-app.my.stuff, my-app.my-stuff, my-app-my.stuff, my-app-my-stuff |
The following example shows how to replace the postgres username property from defining it in config file:
datasources:
postgres:
username: kestra
to environment variable: DATASOURCES_POSTGRES_USERNAME=kestra
Setup
Kestra offers many configuration options and customization.
There are three main components that need to be configured during the initial setup:
- Internal Storage
- Queue
- Repository
Internal storage configuration
Kestra supports multiple internal storage types, the default being the local storage that will store data in a local folder on the host filesystem. It's recommended only for local testing as it doesn't provide resiliency or redundancy.
To choose another storage type, you will need to configure the kestra.storage.type option. Make sure to download the corresponding storage plugins first. The following example configures Google Cloud Storage as internal storage.
kestra:
storage:
type: gcs
Queue configuration
Kestra supports multiple queue types, which must be compatible with the repository type. The default queue depends on your chosen architecture and installation option.
The following queue types are available:
- In-memory queue used with the in-memory repository — intended for local testing.
- Database queue used with the database repository. It currently supports H2, MySQL, and PostgreSQL as a database.
- Kafka queue used with the Elasticsearch repository. Those are only available in the Enterprise Edition.
To enable the PostgreSQL database queue, you need to add the kestra.queue configuration:
kestra:
queue:
type: postgres
Repository configuration
Kestra supports multiple repository types, which must be compatible with the queue type. Also here, the default depends on your installation option.
The following repository types are available:
- In-memory that must be used with the in-memory queue. It is only suitable for local testing as it doesn't provide any resiliency or scalability and didn't implement all functionalities.
- Database that must be used with the database queue. It currently supports H2, MySQL or PostgreSQL as a database.
- Elasticsearch that must be used with the Kafka queue. Those are only available inside the Enterprise Edition.
To enable the PostgreSQL database repository, you need to add the kestra.repository configuration:
kestra:
repository:
type: postgres
For more details, check the database configuration and the Elasticsearch configuration.
Database
Queue and Repository
In order to configure a database backend, you need to set the kestra.queue.type and kestra.repository.type to your chosen database type. Here is an example for PostgreSQL:
kestra:
queue:
type: postgres
repository:
type: postgres
Currently, Kestra supports Postgres, H2, MySQL, and SQL Server (available in a preview in the Enterprise Edition since Kestra 0.18.0).
- H2 can be convenient for local development.
- For production, we recommend PostgreSQL. If PostgreSQL is not an option for you, MySQL and SQL Server can be used as well.
Check the Software Requirements section for the minimum version of each database.
If you experience performance issues when using PostgreSQL, you can tune the cost optimizer parameter random_page_cost=1.1, which should make PostgreSQL use the right index for the queues table. You can also configure kestra.queue.postgres.disableSeqScan=true so that Kestra turns off sequential scans on the queue polling query forcing PostgreSQL to use the index.
Datasources
Once you added the kestra.queue.type and kestra.repository.type, you need to configure the datasources section.
Kestra uses The HikariCP connection pool under the hood, and if needed, you can configure multiple options from the HikariCP documentation directly in your datasources configuration.
Connection pool size
The total number of connections opened to the database will depend on your chosen architecture. Each Kestra instance will open a pool of up to the maximumPoolSize (10 by default), with a minimum size of the minimumIdle (also set to 10 by default).
- If you deploy Kestra as a standalone server, it will open 10 connections to the database.
- If you deploy each Kestra component separately, it will open 40 connections to the database (10 per component).
- If you deploy each Kestra component separately with 3 replicas, it will open 120 connections to the database.
Usually, the default connection pool sizing is enough, as HikariCP is optimized to use a low number of connections.
Datasources
The table below shows the datasource configuration properties. For more details, check the HikariCP configuration documentation.
| Properties | Type | Description |
|---|---|---|
url | String | The JDBC connection string. |
catalog | String | The default catalog name to be set on connections. |
schema | String | The default schema name to be set on connections. |
username | String | The default username used. |
password | String | The default password to use. |
transactionIsolation | String | The default transaction isolation level. |
poolName | String | The name of the connection pool. |
connectionInitSql | String | The SQL string that will be executed on all new connections when they are created, before they are added to the pool. |
connectionTestQuery | String | The SQL query to be executed to test the validity of connections. |
connectionTimeout | Long | The maximum number of milliseconds that a client will wait for a connection from the pool. |
idleTimeout | Long | The maximum amount of time (in milliseconds) that a connection is allowed to sit idle in the pool. |
minimumIdle | Long | The minimum number of idle connections that HikariCP tries to maintain in the pool, including both idle and in-use connections. Defaults to the value of maximumPoolSize |
initializationFailTimeout | Long | The pool initialization failure timeout. |
leakDetectionThreshold | Long | The amount of time that a connection can be out of the pool before a message is logged indicating a possible connection leak. |
maximumPoolSize | Int | The maximum size that the pool is allowed to reach, including both idle and in-use connections. Defaults to 10. |
maxLifetime | Long | The maximum lifetime of a connection in the pool. |
validationTimeout | Long | The maximum number of milliseconds that the pool will wait for a connection to be validated as alive. |
Here's the default HikariCP configuration:
transactionIsolation: default # driver default
poolName: HikariPool-<Generated>
connectionInitSql: null
connectionTestQuery: null
connectionTimeout: 30000 # 30 seconds
idleTimeout: 600000 # 10 minutes
minimumIdle: 10 # same as maximum-pool-size
initializationFailTimeout: 1
leakDetectionThreshold: 0
maximumPoolSize: 10
maxLifetime: 1800000 # 30 minutes
validationTimeout: 5000
JDBC Queues
Kestra database queues simulate queuing doing long polling. They query a queues table to detect new messages.
You can change these parameters to reduce the polling latency, but be aware it will increase the load on the database:
kestra.jdbc.queues.pollSize: the maximum number of queues items fetched by each poll.kestra.jdbc.queues.minPollInterval: the minimum duration between 2 polls.kestra.jdbc.queues.maxPollInterval: the maximum duration between 2 polls.kestra.jdbc.queues.pollSwitchInterval: the delay for switching from min-poll-interval to max-poll-interval when no message is received. (ex: when one message is received, theminPollIntervalis used, if no new message arrived withinpollSwitchInterval, we switch tomaxPollInterval).
Here is the default configuration:
kestra:
jdbc:
queues:
pollSize: 100
minPollInterval: 25ms
maxPollInterval: 1000ms
pollSwitchInterval: 5s
JDBC Cleaner
Kestra cleans the queues table periodically to optimize storage and performance. You can control how often you want this cleaning to happen, and how long messages should be kept in the queues table using the kestra.jdbc.cleaner configuration.
Here is the default configuration:
kestra:
jdbc:
cleaner:
initialDelay: 1h
fixedDelay: 1h
retention: 7d
Protecting against too big messages
Note: this is an experimental feature available starting with Kestra 0.19.
The database backend has no limit on the size of messages it can handle. However, as messages are loaded into memory, this can endanger Kestra itself and push pressure on memory usage.
To prevent that, you can configure a functionality that will refuse to store too big messages in the execution context (for example data stored in outputs property) and fail the execution instead.
The following configuration will refuse messages that exceed 1MiB by failing the execution.
kestra:
jdbc:
queues:
messageProtection:
enabled: true
limit: 1048576
Telemetry
By default, the kestra.anonymousUsageReport is enabled to send anonymous usage data to Kestra to help us improve the product. If you want to disable it, you can set it to false:
kestra:
anonymousUsageReport:
enabled: false
You can change the initial delay (default 5m):
kestra:
anonymousUsageReport:
initialDelay: 5m
You can change the fixed delay (default 1h):
kestra:
anonymousUsageReport:
fixedDelay: 1h
Elasticsearch
Elasticsearch is an Enterprise Edition functionality.
The kestra.elasticsearch setting allows you to configure the way Kestra connects to the Elasticsearch cluster.
Here is a minimal configuration example:
kestra:
elasticsearch:
client:
httpHosts: "http://localhost:9200"
repository:
type: elasticsearch
Here is another example with a secured Elasticsearch cluster with basic authentication:
kestra:
elasticsearch:
client:
httpHosts:
- "http://node-1:9200"
- "http://node-2:9200"
- "http://node-3:9200"
basicAuth:
username: "<your-user>"
password: "<your-password>"
repository:
type: elasticsearch
Trust all SSL certificates
Using the kestra.elasticsearch.client.trustAllSsl configuration, you can trust all SSL certificates during the connection. This is useful for development servers with self-signed certificates.
kestra:
elasticsearch:
client:
httpHosts: "https://localhost:9200"
trustAllSsl: true
Indices Prefix
The kestra.elasticsearch.defaults.indicePrefix configuration allows to change the prefix of the indices. By default, the prefix will be kestra_.
For example, if you want to share a common Elasticsearch cluster for multiple instances of Kestra, add a different prefix for each instance as follows:
kestra:
elasticsearch:
defaults:
indicePrefix: "uat_kestra"
Indices Split
By default, a unique indices are used for all different data.
Using the kestra.elasticsearch.indices configuration, you can split the indices by type. This is useful for large instances where
you may want to split the index by day, week or month to avoid having large indices in ElasticSearch.
Currently, the executions, logs and metrics can be split, and we support all these split types:
DAILYWEEKLYMONTHLYYEARLY
kestra:
elasticsearch:
indices:
executions:
alias: daily
logs:
alias: daily
metrics:
alias: daily
Index Rotation
When you enable index rotation, it creates an alias and one index per periodicity (day, week, etc.).
It's safe to enable it on an existing instance however the alias will clash with the existing index so you should move the existing index, for example change kestra_logs to kestra_logs-1 before switching to the alias.
As indexes will be created with name-periodicity using the -1 suffix, make sure you will still include the old data (until you make the decision to purge it).
Be careful that not all indexes can be safely purged. You should only enable alias for historical data that keeps growing (like logs, metrics and executions).
It's safe to disable aliases but in the case existing data would not be recovered anymore.
It is totally safe to switch from one periodicity to another as the alias is for name-* so the periodicity is not important.
EE Java Security
You can use the kestra.ee.javaSecurity configuration to opt-in to isolation of file systems using advanced Kestra EE Java security:
kestra:
ee:
javaSecurity:
enabled: true
forbiddenPaths:
- /etc/
authorizedClassPrefix:
- io.kestra.plugin.core
- io.kestra.plugin.gcp
Forbidden Paths
The kestra.ee.javaSecurity.forbiddenPaths configuration is a list of paths on the file system that the Kestra Worker will be forbidden to read or write to. This can be useful to protect Kestra configuration files.
Authorized Class Prefix
The kestra.ee.javaSecurity.authorizedClassPrefix configuration is a list of classes that can create threads. Here you can set a list of prefixes (namespace) classes that will be allowed. All others will be refused.
Forbidden Class Prefix
The kestra.ee.javaSecurity.forbiddenClassPrefix configuration is a list of classes that can't create any threads. Others plugins will be authorized.
kestra:
ee:
javaSecurity:
enabled: true
forbiddenClassPrefix:
- io.kestra.plugin.scripts
EE License
To use Kestra Enterprise Edition, you will need a valid license configured under the kestra.ee.license configuration. The license is unique to your organization. If you need a license, please reach out to our Sales team at [email protected].
The license is set up using two configuration properties: id and key.
kestra.ee.license.id: license identifier.kestra.ee.license.key: license key.
When you launch Kestra Enterprise Edition, it will check the license and display the validation step in the log.
Multi-tenancy
By default, multi-tenancy is disabled. To enable it, add the kestra.ee.tenants configuration:
kestra:
ee:
tenants:
enabled: true
Default Tenant
By default, multi-tenancy is disabled, and the default tenant is set to true. Once you enable multi-tenancy, you can set the default tenant to false using the kestra.ee.tenants.defaultTenant configuration:
kestra:
ee:
tenants:
enabled: true
defaultTenant: false
This will enable multi-tenancy and disable the default tenant (best practice). It is recommended to disable it so that your Kestra instance includes only the tenants you explicitly create.
Encryption
Kestra 0.15.0 and later supports encryption of sensitive data. This allows inputs and outputs to be automatically encrypted and decrypted when they are stored in the database.
To enable encryption, you need to provide a base64-encoded secret key in the kestra.encryption configuration:
kestra:
encryption:
secretKey: BASE64_ENCODED_STRING_OF_32_CHARCTERS
To generate a 32-character string and then base64 encode it, you can use the defacto standard for cryptography, OpenSSL:
openssl rand -base64 32
If you don't have OpenSSL installed, you can use the following Bash commands to generate a base64-encoded 32-character encryption key:
random_string=$(LC_ALL=C tr -dc 'A-Za-z0-9' < /dev/urandom | head -c 32)
echo "$random_string" | base64
If you run Kestra with Docker-Compose, here is how you can add that key in the KESTRA_CONFIGURATION environment variable in your docker-compose.yml file:
kestra:
image: kestra/kestra:latest
environment:
KESTRA_CONFIGURATION: |
kestra:
encryption:
secretKey: NWRhUDc5TERWY2QyMDhSSHhfeWYzbjJpNE5vb3M5NnY=
Once the secret key is set, you can use an input and output of type SECRET:
id: my_secret_flow
namespace: company.team
inputs:
- id: secret
type: SECRET
tasks:
- id: mytask
type: io.kestra.plugin.core.log.Log
message: task that needs the secret to connect to an external system
outputs:
- id: secret_output
type: SECRET
value: "{{ inputs.secret }}"
When executing this flow, you will see a masked field:

In the Execution Overview tab, you will see a masked value of the secret.
If the secretKey is not set in the kestra.encryption configuration, you will get an error: Illegal argument: Unable to use a SECRET input as encryption is not configured when trying to use a SECRET input or output type.
Endpoints
Management endpoints can be set up from the Micronaut endpoint configuration. You can also secure all endpoints with basic authentication using the endpoints configuration:
endpoints:
all:
basicAuth:
username: your-user
password: your-password
Environment
Here are the configuration options for the environment UI display.
You can add a label and a color to identify your environment in the UI by adding the kestra.environment configuration:
kestra:
environment:
name: Production
color: "#FCB37C"
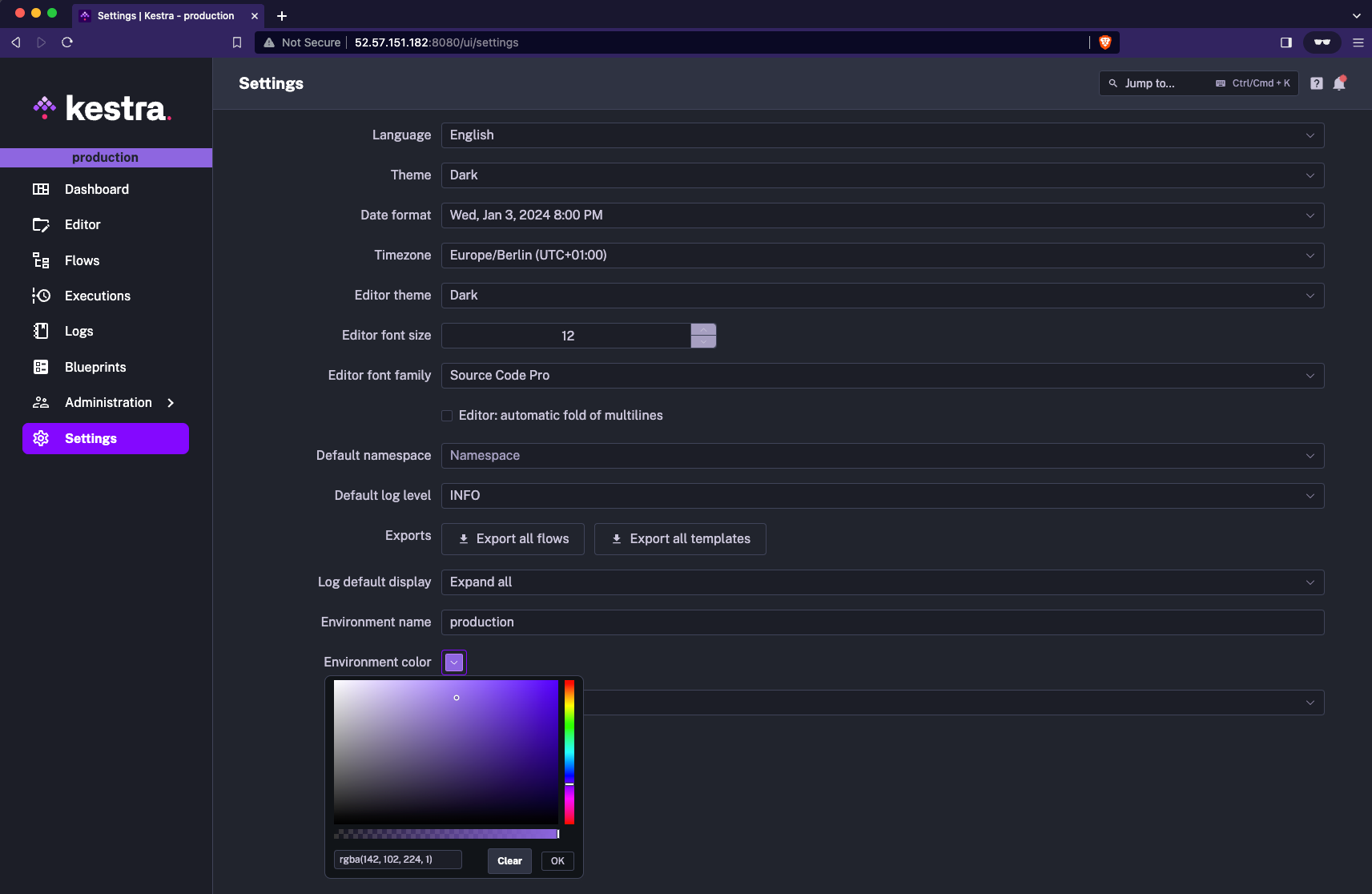
You can also set that environment name and color directly from the UI. Just go to the settings page and type the desired Environment name and select the color.
JVM
All JVM options can be passed in an environment variable named JAVA_OPTS. You can use it to change all JVM options available, such as memory, encoding, etc.
Example:
export JAVA_OPTS="-Duser.timezone=Europe/Paris"
Timezone
By default, Kestra will handle all dates using your system's timezone. You can change the timezone using the user.timezone JVM option.
Changing the timezone will mostly affect:
- scheduler: by default, all schedule dates are UTC; changing the Java timezone will allow scheduling the flow in your timezone.
- logs display: in your configured timezone.
Indexer
Indexer send data from Kafka to Elasticsearch using Bulk Request. You can control the batch size and frequency to reduce the load on ElasticSearch using the kestra.indexer configuration. This will delay some information on the UI raising that values, example:
kestra:
indexer:
batchSize: 500 # (default value, any integer > 0)
batchDuration: PT1S # (default value, any duration)
Kafka
Kafka is part of the Enterprise Edition.
You can set up your Kafka connection using the kestra.kafka configuration.
Client Properties
The most important configuration step is defining how Kestra should connect to the Kafka cluster. You can set this up using the kestra.kafka.client.properties configuration.
Here is a minimal configuration example:
kestra:
kafka:
client:
properties:
bootstrap.servers: "localhost:9092"
queue:
type: kafka
Here is another example with SSL configuration:
kestra:
kafka:
client:
properties:
bootstrap.servers: "host:port"
security.protocol: "SSL"
ssl.endpoint.identification.algorithm: ""
ssl.key.password: "<your-password>"
ssl.keystore.location: "/etc/ssl/private/keystore.p12"
ssl.keystore.password: "<your-password>"
ssl.keystore.type: "PKCS12"
ssl.truststore.location: "/etc/ssl/private/truststore.jks"
ssl.truststore.password: "<your-password>"
queue:
type: kafka
kestra.kafka.client.properties allows passing any standard Kafka properties. More details can be found on the Kafka Documentation.
Topics
By default, Kestra automatically creates all the needed topics. You can change the partition count and replication factor of these topics using the kestra.kafka.defaults.topic configuration.
kestra.kafka.defaults.topic.partitions: (default 16)kestra.kafka.defaults.topic.replicationFactor: (default 1)
The number of topic's partitions limits the number of concurrently processing server instances consuming that particular topic. For example, using 16 partitions for every topic limits the effective number of instances to 16 executor servers, 16 worker servers, etc.
For the optimal value of the replication factor, validate the actual configuration of the target Kafka cluster. Generally, for high availability, the value should match the number of Kafka brokers in the cluster. For example, a cluster consisting of 3 nodes should use the replication factor of 3.
Consumer, Producer and Stream properties
You can change the default properties of the Kafka client used by Kestra using the kestra.kafka.defaults.[consumer|producer|stream].properties configuration. These allow you to change any available properties.
Here is the default configuration:
kestra:
kafka:
defaults:
consumer:
properties:
isolation.level: "read_committed"
auto.offset.reset: "earliest"
enable.auto.commit: "false"
producer:
properties:
acks: "all"
compression.type: "lz4"
max.request.size: "10485760"
stream:
properties:
processing.guarantee: "exactly_once"
replication.factor: "${kestra.kafka.defaults.topic.replicationFactor}"
acks: "all"
compression.type: "lz4"
max.request.size: "10485760"
state.dir: "/tmp/kafka-streams"
Topic names and properties
All the topics used by Kestra are declared with the default name and properties. You can change the default values using the kestra.kafka.defaults.topics configuration:
kestra.kafka.defaults.topics.{{topic}}.name: Change the name of the topic.kestra.kafka.defaults.topics.{{topic}}.properties: Change the default properties used during topic automatic creation.
You can see default configuration on this file.
Consumer Prefix
The kestra.kafka.defaults.consumerPrefix configuration allows changing the consumer-group prefix. By default, the prefix will be kestra.
For example, if you want to share a common Kafka cluster for multiple instances of Kestra, you must configure a different prefix for each instance like this:
kestra:
kafka:
defaults:
consumerPrefix: "uat_kestra"
Topic Prefix
The kestra.kafka.defaults.topicPrefix configuration allows changing the topic name prefix. By default, the prefix will be kestra_.
For example, if you want to share a common Kafka cluster for multiple instances of Kestra, add a different prefix for each instance like this:
kestra:
kafka:
defaults:
topicPrefix: "uat_kestra"
Client Loggers
The kestra.kafka.client.loggers configuration allows enabling logging for all messages processed by the Kafka cluster. Use it to debug all the messages consumed or produced on the Kafka cluster.
This configuration has a huge performance impact, using regexp and serialization for most of the messages.
kestra:
kafka:
client:
loggers:
- level: INFO # mandatory: ERROR, WARN, INFO, DEBUG, TRACE, the logger must be configured at least at this level for class io.kestra.runner.kafka.AbstractInterceptor
type: PRODUCER # optional: CONSUMER or PRODUCER
topicRegexp: "kestra_(executions|workertaskresult)" # optional: a regexp validating the topic
keyRegexp: .*parallel.* # optional: a regexp validating the key
valueRegexp: .*parallel.* # optional: a regexp validating the json full body
Kafka Stream State Directory
Kestra uses the Kafka Stream framework, this framework uses a local directory for state persistence.
By default, the state directory is /tmp/kafka-streams and can be configured using the kestra.kafka.stream.properties.state.dir configuration property.
This directory should not be purged while the application runs but can be purged between restarts. If persisted between restarts, the startup time could be improved as the state of the Kafka Stream will be recovered from the directory.
It is advised to purge this directory before a Kestra update, if not, an error message may be displayed in the log that can be safely ignored.
Topic retention
Each Kafka topic used by Kestra is configurable using the following configuration property:
kestra:
kafka:
topics:
execution:
properties:
kafka.property: value
By default, except for topics where we need unlimited retention as they store referential data like flow or trigger definition, all topics are configured with a default retention of 7 days.
For example, for the topic storing executions, you can configure the retention via this configuration property:
kafka:
topics:
execution:
properties:
retention.ms: "86400000"
Protecting against too big messages
Note: this is an experimental feature.
Kafka topic has a limit of the size of messages it can handle. By default, we set this limit to 10MiB. If a message exceeds this limit, it may crash the executor and Kestra will stop.
To prevent that, you can configure a functionality that will automatically store too big messages to the internal storage.
kestra:
kafka:
messageProtection:
enabled: true
The hard-limit is not mandatory, in this case messages of any size will be accepted.
Listeners
Listeners are deprecated and disabled by default since the 0.11.0 release. You can re-enable them using the kestra.listeners configuration:
kestra:
listeners:
enabled: true
Logger
You can change the log behavior in Kestra by adjusting the logger configuration parameters:
logger:
levels:
io.kestra.runner: TRACE
org.elasticsearch.client: TRACE
org.elasticsearch.client.sniffer: TRACE
org.apache.kafka: DEBUG
io.netty.handler.logging: TRACE
Access Log configuration
You can configure the access log from the webserver using the micronaut.server.netty.accessLogger configuration:
micronaut.server.netty.accessLogger.enabled: enable access log from webserver (defaulttrue).micronaut.server.netty.accessLogger.name: logger name (defaultio.kestra.webserver.access).micronaut.server.netty.accessLogger.format: access log format (default"%{yyyy-MM-dd'T'HH:mm:ss.SSS'Z'}t | %r | status: %s | ip: %a | length: %b | duration: %D").micronaut.server.netty.accessLogger.exclusions: list of regexp to define which log to exclude.
Here are the default values:
micronaut:
server:
netty:
accessLogger:
enabled: true
name: io.kestra.webserver.access
format: "[Date: {}] [Duration: {} ms] [Method: {}] [Url: {}] [Status: {}] [Length: {}] [Ip: {}] [Port: {}]"
exclusions:
- /ui/.+
- /health
- /prometheus
Log Format
We are using Logback to handle log. You change the format of the log format, and we provide some default and common one configuring a logback configuration files.
If you want to customize the log format, you can create a logback.xml file and add it to the classpath. Then, add a new JAVA_OPTS environment variable: "-Dlogback.configurationFile=file:/path/to/your/configuration/logback.xml"
We provide some predefined configuration, and some example of the logback.xml files:
GCP
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="false">
<include resource="logback/base.xml" />
<include resource="logback/gcp.xml" />
<root level="WARN">
<appender-ref ref="CONSOLE_JSON_OUT" />
<appender-ref ref="CONSOLE_JSON_ERR" />
</root>
</configuration>
Elastic Common Schema (ECS) format
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="true">
<include resource="logback/base.xml" />
<include resource="logback/ecs.xml" />
<root level="WARN">
<appender-ref ref="CONSOLE_ECS_OUT" />
<appender-ref ref="CONSOLE_ECS_ERR" />
</root>
</configuration>
Metrics
You can set the prefix for all Kestra metrics using the kestra.metrics configuration:
kestra:
metrics:
prefix: kestra
Micronaut
Given that Kestra is a Java-based application built on top of Micronaut, there are multiple Micronaut settings that you can configure based on your needs using the micronaut configuration.
To see all the possible configuration options, check the official Micronaut guide.
Below are some tips on the Micronaut configuration options which are most relevant to Kestra.
Configure port
micronaut:
server:
port: 8086
Configure SSL
This guide will help you configure SSL with Micronaut. A final working configuration would look as follows (considering you would use environment variables injection for passwords):
micronaut:
security:
x509:
enabled: true
ssl:
enabled: true
server:
ssl:
clientAuthentication: need
keyStore:
path: classpath:ssl/keystore.p12
password: ${KEYSTORE_PASSWORD}
type: PKCS12
trustStore:
path: classpath:ssl/truststore.jks
password: ${TRUSTSTORE_PASSWORD}
type: JKS
Timeout and max uploaded file size
Below is the default configuration for the timeout and max uploaded file size. You can change these values as needed:
micronaut:
server:
maxRequestSize: 10GB
multipart:
maxFileSize: 10GB
disk: true
readIdleTimeout: 60m
writeIdleTimeout: 60m
idleTimeout: 60m
netty:
maxChunkSize: 10MB
Changing base path
If behind a reverse proxy, you can change the base path of the application with the following configuration:
micronaut:
server:
contextPath: "kestra-prd"
Changing host resolution
If behind a reverse proxy, you can change host resolution (http/https/domain name) providing the header sent by your reverse proxy:
micronaut:
server:
hostResolution:
hostHeader: Host
protocolHeader: X-Forwarded-Proto
Configuring CORS
In case you run into issues related to CORS policy, say while calling the webhook API from a JS application, you can enable the processing of CORS requests with the following configuration:
micronaut:
server:
cors:
enabled: true
For more detailed changes like allowing only specific origins or specific methods, you can refer this guide.
Configure Local Flow Syncronization
Below is the minimal configuration to enable local flow synchronization:
micronaut:
io:
watch:
enabled: true
paths:
- /path/to/your/flows
For more information, check out the dedicated guide.
Plugins
Maven repositories used by the command kestra plugins install can be configured using the kestra.plugins configuration.
Maven Central is mandatory for Kestra and its plugins. However, you can add your own (Maven) repository in order to download your custom plugins using the following configuration:
kestra:
plugins:
repositories:
central:
url: https://repo.maven.apache.org/maven2/
jcenter:
url: https://jcenter.bintray.com/
kestra:
url: https://dl.bintray.com/kestra/maven
Enable or disable features
The configuration of plugins section can be also used to enable or disable some features of specific Kestra plugins, or to set some default values for them.
Here is an example of how to enable outputs for Subflow and Flow tasks:
kestra:
plugins:
configurations:
- type: io.kestra.plugin.core.flow.Subflow
values:
outputs:
enabled: true # for backward-compatibility -- false by default
- type: io.kestra.plugin.core.flow.Flow
values:
outputs:
enabled: true # for backward-compatibility -- false by default
By default, the outputs property of a parent flow's Subflow task is deprecated in favor of flow outputs in Kestra 0.15.0 and higher. However, setting such configuration will keep the old behavior with the outputs property.
Set default values
You can also set default values for a plugin. For example, starting from Kestra 0.15.0, you can set the default value for the recoverMissedSchedules property of the Schedule trigger to NONE to avoid recovering missed scheduled executions after a server restart:
kestra:
plugins:
configurations:
- type: io.kestra.plugin.core.trigger.Schedule
values:
# Available options: LAST | NONE | ALL. The default is ALL
recoverMissedSchedules: NONE
Before 0.15, Kestra was always recovering missed schedules. This means that if your server was down for a few hours, Kestra would recover all missed schedules when it was back up. This behavior was not always desirable, as often the recovery of missed schedules is not necessary e.g. during a planned maintenance window. This is why, starting from Kestra 0.15 release, you can customize the recoverMissedSchedules property and choose whether you want to recover missed schedules or not.
The recoverMissedSchedules configuration can be set to ALL, NONE or LAST:
ALL: Kestra will recover all missed schedules. This is the default value.NONE: Kestra will not recover any missed schedules.LAST: Kestra will recover only the last missed schedule for each flow.
Note that this is a global configuration that will apply to all flows, unless explicitly overwritten within the flow definition:
triggers:
- id: schedule
type: io.kestra.plugin.core.trigger.Schedule
cron: "*/15 * * * *"
recoverMissedSchedules: NONE
In this example, the recoverMissedSchedules is set to NONE, which means that Kestra will not recover any missed schedules for this specific flow regardless of the global configuration.
Allowed plugins
This is an Enterprise Edition feature available starting with Kestra 0.19.
You can restrict which plugins can be used in a Kestra instance by configuring an allowlist / exclude list using regexes.
The following configuration only allow plugin from the io.kestra package and disallow the io.kestra.plugin.core.debug.Echo plugin.
kestra:
plugins:
security:
includes:
- io.kestra.*
excludes:
- io.kestra.plugin.core.debug.Echo
Plugin defaults
You can provide global plugin defaults using the kestra.plugins.defaults configuration. Those will be applied to each task on your cluster if a property is not defined on flows or tasks. Plugin defaults allow ensuring a property is defined at a default value for these tasks.
kestra:
plugins:
defaults:
- type: io.kestra.plugin.core.log.Log
values:
level: ERROR
Forced plugin defaults:
- ensure a property is set globally for a task, and no task can override it
- are critical for security and governance, e.g. to enforce Shell tasks to run as Docker containers.
kestra:
plugins:
defaults:
- type: io.kestra.plugin.scripts.shell.Script
forced: true
values:
taskRunner:
type: io.kestra.plugin.scripts.runner.docker.Docker
Retries
Kestra uses external storage and secrets so that your private data and secrets are stored in a secure way in your private infrastructure. These external systems communicate with Kestra through APIs. Those API calls, however, might eperience transient failures. To handle these transient failures, Kestra allows you to set up automatic retries using the kestra.retries configuration.
Here are the available retry configuration options:
kestra.retries.attempts: the max number of retries (default5)kestra.retries.delay: the initial delay between retries (default1s)kestra.retries.maxDelay: the max amount of time to retry (defaultundefined)kestra.retries.multiplier: the multiplier ofdelaybetween each attempt (default2.0)
Note that those retries are only applied to API calls made to internal storage (like S3 or GCS) and to secrets managers (like Vault or AWS Secrets Manager). They are not applied to tasks.
In order to globally configure retries for tasks, you can use the plugin defaults with a global scope tied to the main io.kestra plugin path as follows:
- type: io.kestra
retry:
type: constant # type: string
interval: PT5M # type: Duration
maxDuration: PT1H # type: Duration
maxAttempt: 3 # type: int
warningOnRetry: true # type: boolean, default is false
Secret Managers
You can configure the secret manager backend using the kestra.secret configuration.
AWS Secret Manager
In order to use AWS Secret Manager as a secrets backend, make sure that your AWS IAM user or role have the required permissions including CreateSecret, DeleteSecret, DescribeSecret, GetSecretValue, ListSecrets, PutSecretValue, RestoreSecret, TagResource, UpdateSecret.
kestra:
secret:
type: aws-secret-manager
awsSecretManager:
accessKeyId: mysuperaccesskey
secretKeyId: mysupersecretkey
sessionToken: mysupersessiontoken
region: us-east-1
Azure Key Vault
To configure Azure Key Vault as your secrets backend, make sure that kestra's user or service principal (clientId) has the necessary permissions, including "Get", "List", "Set", "Delete", "Recover", "Backup", "Restore", "Purge". Then, paste the clientSecret from the Azure portal to the clientSecret property in the configuration below.
kestra:
secret:
type: azure-key-vault
azureKeyVault:
clientSecret:
tenantId: "id"
clientId: "id"
clientSecret: "secret"
Elasticsearch
Elasticsearch backend stores secrets with an additional layer of security using AES encryption. You will need to provide a cryptographic key (at least 32 characters-long string) in order to encrypt and decrypt secrets stored in Elasticsearch.
kestra:
secret:
type: elasticsearch
elasticsearch:
secret: "a-secure-32-character-minimum-key"
Google Secret Manager
To leverage Google Secret Manager as your secrets backend, you will need to create a service account with the roles/secretmanager.admin permission. Paste the contents of the service account JSON key file to the serviceAccount property in the configuration below. Alternatively, set the GOOGLE_APPLICATION_CREDENTIALS environment variable to point to the credentials file.
kestra:
secret:
type: google-secret-manager
googleSecretManager:
project: gcp-project-id
serviceAccount: |
Paste here the contents of the service account JSON key file
HashiCorp Vault
Kestra currently supports the KV secrets engine - version 2 as a secrets backend.
To authenticate Kestra with HashiCorp Vault, you can use Userpass, Token or AppRole Auth Methods, all of which requires full read and write policies. You can optionally change root-engine or namespace (if you use Vault Enterprise).
kestra:
secret:
type: vault
vault:
address: "http://localhostt:8200"
password:
user: john
password: foo
cache:
enabled: true
maximumSize: 1000
expireAfterWrite: 60s
kestra:
secret:
type: vault
vault:
address: "http://localhostt:8200"
token:
token: your-secret-token
kestra:
secret:
type: vault
vault:
address: "http://localhostt:8200"
appRole:
path: approle
roleId: your-role-id
secretId: your-secret-id
JDBC
kestra:
secret:
type: jdbc
jdbc:
secret: "your-secret-key"
Secret Tags
kestra:
secret:
<secret-type>:
# a map of default key/value tags
tags:
application: kestra-production
Secret Cache
kestra:
secret:
cache:
enabled: true
maximumSize: 1000
expireAfterWrite: 60s
Security
Using the kestra.security configuration, you can set up multiple security features of Kestra.
Super-Admin
The most powerful user in Kestra is the SuperAdmin
You can create a SuperAdmin user from the kestra.security.superAdmin configuration.
The super-admin requires three properties:
kestra.security.superAdmin.username: the username of the super-adminkestra.security.superAdmin.password: the password of the super-adminkestra.security.superAdmin.tenantAdminAccess: a list of tenants that the super-admin can access- This property can be omitted if you do not use multi-tenancy
- If a Tenant does not exists, it will be created
- At each startup, this user is checked and if the list of access permissions has been modified, new access permissions can be created, but none will be removed
The password should never be stored in clear text in the configuration file. Make sure to use an environment variable in the format ${KESTRA_SUPERADMIN_PASSWORD}.
kestra:
security:
superAdmin:
username: your_username
password: ${KESTRA_SUPERADMIN_PASSWORD}
tenantAdminAccess:
- <optional>
Default Role
The default role is the role that will be assigned to a new user when it is created.
You can define the default role using the kestra.security.defaultRole configuration.
Whenever you start Kestra, the default role will be checked and created if it doesn't exist.
The default role requires three properties:
kestra.security.defaultRole.name: the name of the default rolekestra.security.defaultRole.description: the description of the default rolekestra.security.defaultRole.permissions: the permissions of the default role- This has to be a map with a Permission as a key and a list of Action as a value
kestra:
security:
defaultRole:
name: default
description: "Default role"
permissions:
FLOW: ["CREATE", "READ", "UPDATE", "DELETE"]
When using multitenancy, the default role will be added to every tenant and will grant specified access permissions to new users across all tenants. If you prefer to restrict the default role to only allow access to a given tenant e.g. staging, you can add the tenantId property as follows:
kestra:
security:
defaultRole:
name: default
description: "Default role"
permissions:
FLOW: ["CREATE", "READ", "UPDATE", "DELETE"]
tenantId: staging
Make sure that you attach the defaultRole configuration under kestra.securityrather than under micronaut.security — it's easy to confuse the two so make sure you enter that configuration in the right place.
Invitation Expiration
When you invite a new user to Kestra, the invitation will expire after a certain amount of time. By default, invitations expire after 7 days.
If you want to change the default expiration time, you can do so by setting the expireAfter property in the kestra.security.invitation section. For example, to set the expiration time to 30 days, add the following configuration:
kestra:
security:
invitations:
expireAfter: P30D
Server
Using the kestra.server configuration, you can set up multiple server-specific functionalities.
HTTP Basic Authentication
You can protect your Kestra installation with HTTP Basic Authentication.
kestra:
server:
basicAuth:
enabled: true
username: admin
password: kestra
HTTP Basic Authentication is disabled by default - you can enable it in your Kestra configuration, as shown above. If you need more fine-grained control over user and access management, the Enterprise Edition provides additional authentication mechanisms, including features such as SSO and RBAC. For more details, see the Authentication page.
Delete configuration files
kestra.configurations.deleteFilesOnStart:
This setting allows to delete all configuration files after the server startup. It prevents the ability to read configuration files (that may contain your secrets) from a Bash task for example. The server will keep these values in memory, and they won't be accessible from tasks.
| Type | Boolean |
| Default | false |
Server Liveness & Heartbeats
Kestra's servers use a heartbeat mechanism to periodically send their current state to the Kestra backend, indicating their liveness. That mechanism is crucial for the timely detection of server failures and for ensuring seamless continuity in workflow executions.
Here are the configuration parameters for all server types starting from Kestra 0.16.0.
Note that although it's recommended to deploy the same configuration for all Kestra servers, it's perfectly safe to set different values for those parameters depending on the server type.
kestra.server.liveness.enabled
Enable the liveness probe for the server. This property controls whether a server can be detected as DISCONNECTED or
not. Must always be true for production environment.
| Type | Boolean |
| Default | true |
kestra.server.liveness.interval
Frequency at which an Executor will check the liveness of connected servers.
| Type | Duration |
| Default | 5s |
kestra.server.liveness.timeout
The time an Executor will wait for a state update from a server before considering it as DISCONNECTED.
| Type | Duration |
| Default | 45s |
Note that this parameter MUST be configured with the same value for all Executor server.
kestra.server.liveness.initialDelay
The initial delay after which an Executor will start monitoring the liveliness of a server joining the cluster.
| Type | Duration |
| Default | 45s |
Note that this parameter MUST be configured with the same value for all Executor server.
kestra.server.liveness.heartbeatInterval
The interval at which a server will send a heartbeat indicating its current state.
Must be strictly inferior to kestra.server.liveness.timeout.
| Type | Duration |
| Default | 3s |
Recommended configuration for production
Here is the default and recommended configuration for production ():
For JDBC deployment-mode (OSS):
kestra:
server:
liveness:
enabled: true
interval: 5s
timeout: 45s
initialDelay: 45s
heartbeatInterval: 3s
For Kafka deployment-mode (Enterprise Edition):
kestra:
server:
liveness:
timeout: 1m
initialDelay: 1m
Note that Worker liveness is directly managed by the Apache Kafka protocol which natively provides durability and reliability of task executions.
Heartbeat Frequency
The interval at which a Worker will send a heartbeat indicating its current state can be configured using the kestra.heartbeat.frequency configuration.
| Type | Duration |
| Default | 10s |
Heartbeat Missed
The number of missed heartbeats before Executors will consider a Worker as DEAD can be configured using the kestra.heartbeat.heartbeatMissed configuration.
| Type | Integer |
| Default | 3 |
Worker Task Restart Strategy
Starting with Kestra 0.16.0, you can configure the strategy to be used by Executors when a Worker is
detected as unhealthy regarding uncompleted tasks (JDBC deployment mode).
kestra.server.workerTaskRestartStrategy
The strategy to be used for restarting uncompleted tasks in the event of a worker failure.
Supported strategies are:
NEVER:
Tasks will never be restarted in the event of a worker failure (i.e., tasks are run at most once).
IMMEDIATELY:
Tasks will be restarted immediately in the event of a worker failure, (i.e., as soon as a worker is detected
as DISCONNECTED).
This strategy can be used to reduce task recovery times at the risk of introducing duplicate executions (i.e., tasks are
run at least once).
AFTER_TERMINATION_GRACE_PERIOD:
Tasks will be restarted on worker failure after the kestra.server.terminationGracePeriod.
This strategy should prefer to reduce the risk of task duplication (i.e., tasks are run exactly once in the best
effort).
| Type | String |
| Default | AFTER_TERMINATION_GRACE_PERIOD |
| Valid values: | [ NEVER, IMMEDIATELY, AFTER_TERMINATION_GRACE_PERIOD ] |
Termination Grace Period
When a Kestra Server receives a SIGTERM signal it will immediately try to stop gracefully.
Starting with Kestra 0.16.0, you can configure the termination grace period for each Kestra Server.
The termination grace period defines the allowed period for a server to stop gracefully.
kestra.server.terminationGracePeriod
The expected time for the server to complete all its tasks before shutting down.
| Type | Duration |
| Default | 5m |
Internal Storage
Using the kestra.storage configuration, you can set up the desired internal storage type for Kestra.
The default internal storage implementation is the local storage which is not suitable for production as it will store data in a local folder on the host filesystem.
This local storage can be configured as follows:
kestra:
storage:
type: local
local:
basePath: /tmp/kestra/storage/ # your custom path
Other internal storage types include:
- Storage S3 for AWS S3
- Storage GCS for Google Cloud Storage
- Storage Minio compatible with others S3 like storage services
- Storage Azure for Azure Blob Storage
S3
First, make sure that the S3 storage plugin is installed in your environment. You can install it with the following Kestra command:
./kestra plugins install io.kestra.storage:storage-s3:LATEST. This command will download the plugin's jar file into the plugin's directory.
Then, enable the storage using the following configuration:
kestra:
storage:
type: s3
s3:
endpoint: "<your-s3-endpoint>" # Only needed if you host your own S3 storage
accessKey: "<your-aws-access-key-id>"
secretKey: "<your-aws-secret-access-key>"
region: "<your-aws-region>"
bucket: "<your-s3-bucket-name>"
forcePathStyle: "<true|false>" # optional, defaults to false, useful if you mandate domain resolution to be path-based due to DNS for eg.
If you are using an AWS EC2 or EKS instance, you can use the default credentials provider chain. In this case, you can omit the accessKey and secretKey options:
kestra:
storage:
type: s3
s3:
region: "<your-aws-region>"
bucket: "<your-s3-bucket-name>"
Additional configurations can be found here.
Minio
If you use Minio or similar S3-compatible storage options, you can follow the same process as shown above to install the Minio storage plugin. Then, make sure to include the Minio's endpoint and port in the storage configuration:
kestra:
storage:
type: minio
minio:
endpoint: your_endpoint_without_https_protocol_and_without_any_slashes
port: 9000 # the default is 9000 but if your endpoint is secured with TSL/SSL protocol, use 443
secure: false # set it to true when using TSL/SSL protocol
accessKey: ${AWS_ACCESS_KEY_ID}
secretKey: ${AWS_SECRET_ACCESS_KEY}
region: "default"
bucket: your_s3_bucket_name
partSize: your_part_size_for_multipart_uploads # syntax: <number><unit> without space e.g. 100KB, 5MB, 1GB — defaults to 5MB
Optionally and if the Minio configured is configured to do so (MINIO_DOMAIN=my.domain.com environment variable on Minio server), you can also use the kestra.storage.minio.vhost: true property to make Minio client to use the virtual host syntax.
Please note that the endpoint should always be your base domain (even if you use the virtual host syntax). In the above example, endpoint: my.domain.com, bucket: my-bucket. Setting endpoint: my-bucket.my.domain.com will lead to failure.
Azure
First, install the Azure storage plugin. To do that, you can leverage the following Kestra command:
./kestra plugins install io.kestra.storage:storage-azure:LATEST. This command will download the plugin's jar file into the plugins directory.
Adjust the storage configuration shown below depending on your chosen authentication method:
kestra:
storage:
type: azure
azure:
endpoint: "https://unittestkt.blob.core.windows.net"
container: storage
connectionString: "<connection-string>"
sharedKeyAccountName: "<shared-key-account-name>"
sharedKeyAccountAccessKey: "<shared-key-account-access-key>"
sasToken: "<sas-token>"
Note that your Azure Blob Storage should disable Hierarchical namespace as this feature is not supported in Kestra.
GCS
You can install the GCS storage plugin using the following Kestra command:
./kestra plugins install io.kestra.storage:storage-gcs:LATEST. This command will download the plugin's jar file into the plugins directory.
Then, you can enable the storage using the following configuration:
kestra:
storage:
type: gcs
gcs:
bucket: "<your-bucket-name>"
projectId: "<project-id or use default projectId>"
serviceAccount: "<serviceAccount key as JSON or use default credentials>"
If you haven't configured the kestra.storage.gcs.serviceAccount option, Kestra will use the default service account, which is:
- the service account defined on the cluster (for GKE deployments)
- the service account defined on the compute instance (for GCE deployments).
You can also provide the environment variable GOOGLE_APPLICATION_CREDENTIALS with a path to a JSON file containing GCP service account key.
You can find more details in the GCP documentation.
System Flows
By default, the system namespace is reserved for System Flows. These background workflows are intended to perform routine tasks such as sending alerts and purging old logs. If you want to overwrite the name used for System Flows, use the kestra.system-flows configuration:
kestra:
systemFlows:
namespace: system
Tasks
Using the kestra.tasks configuration, you can set up multiple task-specific features.
Plugin Default Configuration
You can set defaults for specific tasks using the kestra.plugins.defaults configuration. These defaults will be applied to all tasks on your cluster if a property is not defined on flows or tasks.
You can use this to isolate tasks in containers, such as scripting tasks. For Bash tasks and other script tasks in the core, we advise you to force io.kestra.plugin.scripts.runner.docker.Docker isolation and to configure global cluster pluginDefaults:
kestra:
plugins:
defaults:
- type: io.kestra.plugin.scripts.shell.Commands
forced: true
values:
containerImage: ubuntu:latest
taskRunner:
type: io.kestra.plugin.scripts.runner.docker.Docker
Volume Enabled for Docker Task Runner
Volumes mount are disabled by default for security reasons, you can enabled it with this configurations:
kestra:
plugins:
configurations:
- type: io.kestra.plugin.scripts.runner.docker.Docker
values:
volumeEnabled: true
Temporary storage configuration
Kestra writes temporary files during task processing. By default, files will be created on /tmp, but you can change the location with this configuration:
kestra:
tasks:
tmpDir:
path: /home/kestra/tmp
Note: The tmpDir path must be aligned to the volume path otherwise Kestra will not know what directory to mount for the tmp directory.
volumes:
- kestraData:/app/storage
- /var/run/docker.sock:/var/run/docker.sock
- /home/kestra:/home/kestra
In this example, /home/kestra:/home/kestra matches the tasks tmpDir field.
Tutorial Flows
Tutorial flows are used to help users understand how Kestra works. They are used in the Guided Tour that allows you to select your use case and see how Kestra can help you solve it. You can disable the tutorial flows in production using the kestra.tutorialFlows configuration:
kestra:
tutorialFlows:
enabled: false
Disable Tutorial Flows
To disable the tutorial flows, set the tutorialFlows property to false in your configuration file.
kestra:
tutorialFlows:
enabled: false # true by default
The tutorial flows are included in the open-source edition of Kestra by default. It's recommended to set that property to false in production environments to avoid unnecessary flows from being loaded into the production system.
Enabling Templates
Templates are marked as deprecated and disabled by default starting from the 0.11.0 release. You can re-enable them with the kestra.templates configuration:
kestra:
templates:
enabled: true
Kestra URL
Some notification services require a URL configuration defined in kestra.url in order to add links from the alert message. Use a full URI here with a trailing / (without ui or api).
kestra:
url: https://www.my-host.com/kestra/
Variables
Using the kestra.variables configuration, you can determine how variables are handled in Kestra.
Environment Variables Prefix
Kestra provides a way to use environment variables in your flow. By default, Kestra will only look at environment variables that start with KESTRA_. You can change this prefix by setting the kestra.variables.envVarsPrefix configuration option:
kestra:
variables:
envVarsPrefix: KESTRA_
These variables will be accessible in a flow with {{ envs.your_env }} in lowercase without the prefix.
For example, an environment variable with the name KESTRA_MY_ENV can be accessed using {{ envs.my_env }}.
Global Variables
You can also set global variables directly in the kestra.variables.globals configuration. These variables will be accessible in all flows across the instance.
For example, the following variable will be accessible in a flow using {{ globals.host }}:
kestra:
variables:
globals:
host: pg.db.prod
Keep in mind that if a variable is in camel case, it will be transformed into hyphenated case. For example, the global variable shown below will be accessible in flows with {{ globals['myVar'] }} or {{ globals['environment-name'] }}:
kestra:
variables:
globals:
environment_name: dev
myVar: my variable
Recursive Rendering
The kestra.variables.recursiveRendering configuration allows you to enable the pre-0.14.0 recursive rendering behavior and give administrators more time to migrate deployed flows. It defaults to false:
kestra:
variables:
recursiveRendering: true
The rendering of template variables can be CPU intensive, and by default we enable a cache of "templates". You can disable it using the kestra.variables.cacheEnabled configuration:
kestra:
variables:
cacheEnabled: false
We recommend keeping the cache enabled, as it can improve the performance.
Cache Size
The rendering of template variables cache is an LRU cache (keeps most commonly used variables) and will be cached in memory (default 1000). You can change the size of the template cache (in number of templates) using the kestra.variables.cacheSize configuration.
kestra:
variables:
cacheSize: 1000
Keep in mind that the higher this number will be, the more memory the server will use.
Webserver
Using the kestra.webserver configuration, you can adjust the settings of the Kestra webserver.
Google Analytics ID
Using the kestra.webserver.googleAnalytics configuration, you can add a Google Analytics tracking ID to report all page tracking. Here is an example of how you can add your Google Analytics tracking ID:
kestra:
webserver:
googleAnalytics: UA-12345678-1
Append HTML tags to the webserver application
With the help of the kestra.webserver.htmlHead configuration, you can append HTML tags to the webserver application. This can bw used to inject CSS or JavaScript to customize the web application.
For example, here is how you can add a red banner in production environments:
kestra:
webserver:
htmlHead: |
<style type="text/css">
.v-sidebar-menu .logo:after {
background: var(--danger);
display: block;
content: "Local";
position: relative;
textTransform: uppercase;
bottom: -65px;
textAlign: center;
color: var(--white-always);
}
</style>
Configuring a mail server
Kestra can send emails for invitations and forgotten passwords. You can configure the mail server using the kestra.mail-service configuration.
host: host.smtp.io
port: 587
username: user
password: password
from: [email protected]
fromName: Kestra
auth: true #default
starttlsEnable: true #default
Was this page helpful?