Configure and Use Dynamic Variables with Pebble Templating
For the complete documentation index, see llms.txt. For a full content snapshot, see llms-full.txt. Append.mdto anykestra.io/docs/*URL for plain Markdown.
Variables are key-value pairs that let you reuse values across tasks.
You can also store variables at the namespace level to reuse them across multiple flows in that namespace.
How to configure variables
The example below shows how you can configure variables in your flow:
id: hello_worldnamespace: company.team
variables: myvar: hello numeric_variable: 42
tasks: - id: log type: io.kestra.plugin.core.debug.Return format: "{{ vars.myvar }} world {{ vars.numeric_variable }}"Use variables with the syntax {{ vars.variable_name }}.
How variables are rendered
You can use variables in any task property documented as dynamic.
Dynamic variables are rendered by the Pebble templating engine, which processes expressions with filters and functions. More information on variable processing can be found under Expressions.
Variables are no longer rendered recursively. Learn more about this change — and how to adjust behavior — in the migration guide.
Dynamic variables
If a variable contains an expression, wrap it with render when using it in a task.
For example, the variable below displays the current time only when wrapped with render; otherwise, the log prints the expression as a string:
id: dynamic_variablenamespace: company.team
variables: time: "{{ now() }}"
tasks: - id: log type: io.kestra.plugin.core.log.Log message: "{{ render(vars.time) }}"Wrap the variable expression with render every time you use it in a task.
Set or modify execution variables
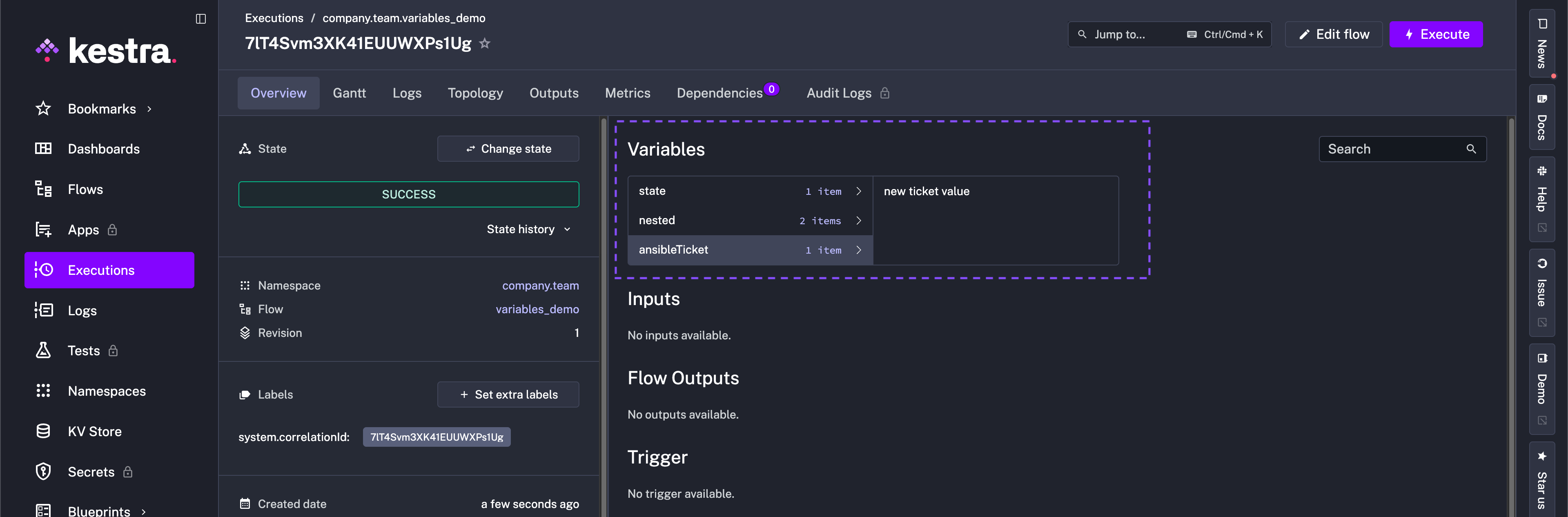
The SetVariables and UnsetVariables tasks can modify or delete variables within the execution context. For example, take the following flow:
id: variables_demonamespace: company.team
variables: state: FAILED ansibleTicket: myticket nested: child: property unchanged: stay the same
tasks: - id: request type: io.kestra.plugin.core.output.OutputValues values: ansibleTicket: new ticket value state: SUCCESS
- id: updateVariables type: io.kestra.plugin.core.execution.SetVariables overwrite: true # true by default variables: state: "{{ outputs.request.values.state }}" ansibleTicket: "{{ outputs.request.values.ansibleTicket }}" nested: child: new value
- id: confirmUpdate type: io.kestra.plugin.core.log.Log message: Hello "{{ vars }}"Initially, state is FAILED and ansibleTicket is myticket. Within the flow, the updateVariables task uses io.kestra.plugin.core.execution.SetVariables to modify state to SUCCESS and ansibleTicket to new ticket value per the request task, as well as change one of the nested variables, nested.child to new value (nested.unchanged is unmodified so it’ll remain the same).
After the flow runs, state, ansibleTicket, and nested.child have their new values, and nested.unchanged remains unchanged.
Delete or unset execution variables
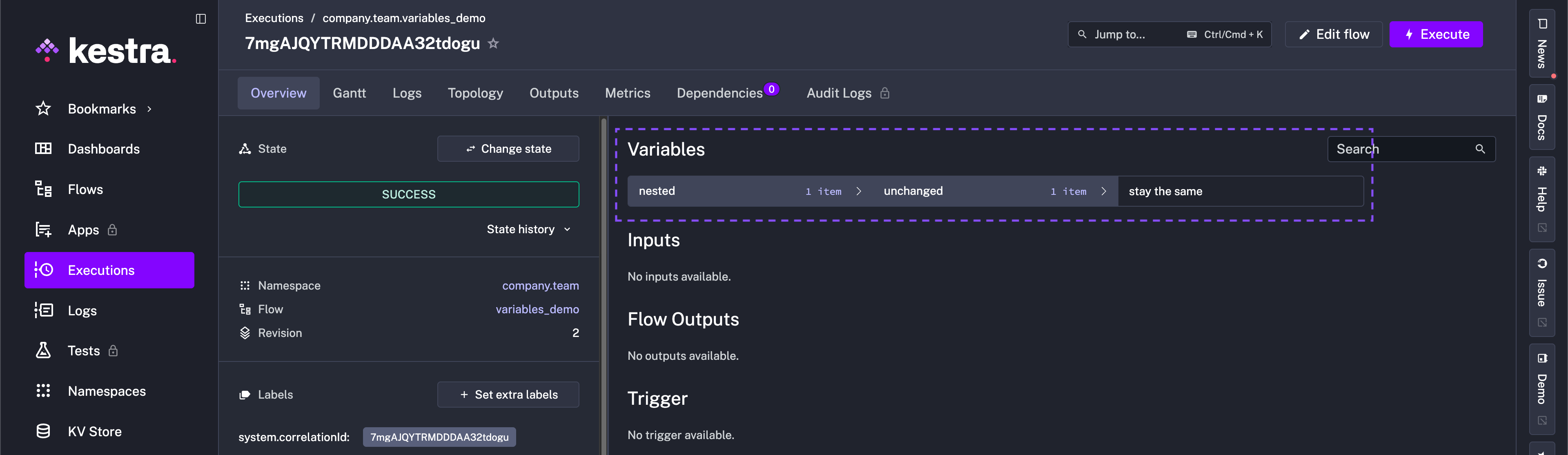
To unset variables, use io.kestra.plugin.core.execution.UnsetVariables. Building on the example above, add the following task:
- id: deleteVariables type: io.kestra.plugin.core.execution.UnsetVariables variables: - state - ansibleTicket - nested.child # remove only this key from the nested mapAfter executing the flow, the only remaining variable is nested.unchanged with the value stay the same. In the unset task, state, ansibleTicket, and nested.child were deleted.
FAQ
How do I escape a block in Pebble syntax to ensure that it won’t be parsed?
To ensure that a block of code won’t be parsed by Pebble, you can use the {% raw %} and {% endraw %} Pebble tags. For example, the following returns the string {{ myvar }} instead of the value of myvar:
{% raw %}{{ myvar }}{% endraw %}In which order are inputs and variables resolved?
Inputs are resolved first, before the execution starts. If a flow has an invalid input value, the execution will not be created.
Therefore, you can use inputs within variables, but you cannot use variables or Pebble expressions in most contexts (Check out Dynamic Inputs for more information) within inputs.
Expressions are rendered recursively: if a variable references another variable, the inner one is resolved first.
Triggers are handled similarly to inputs because they are known before the execution starts (they create the execution). This means you cannot use inputs (unless they have defaults) within triggers, but you can use trigger variables inside variables.
Examples
This flow uses inputs, trigger, and execution variables which are resolved before variables:
id: upload_to_s3namespace: company.team
inputs: - id: bucket type: STRING defaults: declarative-data-orchestration
tasks: - id: get_zip_file type: io.kestra.plugin.core.http.Download uri: https://wri-dataportal-prod.s3.amazonaws.com/manual/global_power_plant_database_v_1_3.zip
- id: unzip type: io.kestra.plugin.compress.ArchiveDecompress algorithm: ZIP from: "{{outputs.get_zip_file.uri}}"
- id: csv_upload type: io.kestra.plugin.aws.s3.Upload from: "{{ outputs.unzip.files['global_power_plant_database.csv'] }}" bucket: "{{ inputs.bucket }}" key: "powerplant/{{ trigger.date ?? execution.startDate | date('yyyy_MM_dd__HH_mm_ss') }}.csv"
triggers: - id: hourly type: io.kestra.plugin.core.trigger.Schedule cron: "@hourly"This flow starts a task conditionally based on whether the input is provided or not:
id: conditional_branchingnamespace: company.team
inputs: - id: parameter type: STRING required: false
tasks: - id: if type: io.kestra.plugin.core.flow.If condition: "{{inputs.parameter ?? false }}" then: - id: if_not_null type: io.kestra.plugin.core.log.Log message: Received input {{inputs.parameter}} else: - id: if_null type: io.kestra.plugin.core.log.Log message: No input providedBelow is an example that uses a trigger variable within a trigger itself (that’s allowed!):
id: backfill_past_mondaysnamespace: company.team
tasks: - id: log_trigger_or_execution_date type: io.kestra.plugin.core.log.Log message: "{{ trigger.date ?? execution.startDate }}"
triggers: - id: first_monday_of_the_month type: io.kestra.plugin.core.trigger.Schedule timezone: Europe/Berlin backfill: start: 2023-11-11T00:00:00Z cron: "0 11 * * MON" # at 11:00 every Monday conditions: # only first Monday of the month - type: io.kestra.plugin.core.condition.DayWeekInMonth date: "{{ trigger.date }}" dayOfWeek: "MONDAY" dayInMonth: "FIRST"Can I transform variables with Pebble expressions?
Yes. Kestra uses Pebble templates along with the execution context to render dynamic properties. (such as filters, functions, and operators) to transform inputs and variables.
The example below illustrates how to use variables and Pebble expressions to transform string values in dynamic task properties:
id: variables_demonamespace: company.team
variables: DATE_FORMAT: "yyyy-MM-dd"
tasks: - id: seconds_of_day type: io.kestra.plugin.core.debug.Return format: '{{ 60 * 60 * 24 }}'
- id: start_date type: io.kestra.plugin.core.debug.Return format: "{{ execution.startDate | date(vars.DATE_FORMAT) }}"
- id: curr_date_unix type: io.kestra.plugin.core.debug.Return format: "{{ now() | date(vars.DATE_FORMAT) | timestamp() }}"
- id: next_date type: io.kestra.plugin.core.debug.Return format: "{{ now() | dateAdd(1, 'DAYS') | date(vars.DATE_FORMAT) }}"
- id: next_date_unix type: io.kestra.plugin.core.debug.Return format: "{{ now() | dateAdd(1, 'DAYS') | date(vars.DATE_FORMAT) | timestamp() }}"
- id: pass_downstream type: io.kestra.plugin.scripts.shell.Commands taskRunner: type: io.kestra.plugin.core.runner.Process commands: - echo "{{ outputs.next_date_unix.value }}"Can I use nested variables?
Yes. Depending on the task, you may need to wrap the root variable with json() to access specific keys. Below is an example using a list of maps as a variable:
id: varsnamespace: company.myteam
variables: servers: - fqn: server01.mydomain.io user: root - fqn: server02.mydomain.io user: guest - fqn: server03.mydomain.io user: rick
tasks: - id: parallel type: io.kestra.plugin.core.flow.ForEach concurrencyLimit: 0 values: "{{ vars.servers }}" tasks: - id: log type: io.kestra.plugin.core.log.Log message: - "{{ taskrun.value }}" # for each element, prints the full JSON object (e.g., {"fqn":"server01.mydomain.io","user":"root"}) - "{{ json(taskrun.value).fqn }}" # prints the value for that key (e.g., server01.mydomain.io) - "{{ json(taskrun.value).user }}" # prints the value for that key (e.g., root)Was this page helpful?