Replay Missed Schedule Intervals with Backfill
For the complete documentation index, see llms.txt. For a full content snapshot, see llms-full.txt. Append.mdto anykestra.io/docs/*URL for plain Markdown.
Backfills are replays of missed schedule intervals between a defined start and end date.
Let’s take the following flow as an example:
id: scheduled_flownamespace: company.team
tasks: - id: label type: io.kestra.plugin.core.execution.Labels labels: # label to track scheduled date scheduledDate: "{{trigger.date ?? execution.startDate}}" - id: external_system_export type: io.kestra.plugin.scripts.shell.Commands taskRunner: type: io.kestra.plugin.core.runner.Process commands: - echo "processing data for {{trigger.date ?? execution.startDate}}" - sleep $((RANDOM % 5 + 1))
triggers: - id: schedule type: io.kestra.plugin.core.trigger.Schedule cron: "*/30 * * * *"This flow runs every 30 minutes. However, imagine that your source system had an outage for 5 hours. The flow will miss 10 executions. To replay these missed executions, you can use the backfill feature.
Ensure the backfill’s start and end dates encompass every missed schedule, so the trigger can replay each execution. Note that Backfill does not only replay missed executions in the time window. If there are successful executions, then these are also replayed. To target specific executions, rather than a time window, to avoid duplication use Replay.
All missed schedules are automatically recovered by default if the Kestra server is down. The missed schedules will be executed as soon as Kestra is back up because of the recoverMissedSchedules: ALL property default. If you have configured this differently in your global Kestra configuration or specifically on a trigger, a Backfill achieves the same behavior. Read more about recoverMissedSchedules in the dedicated documentation.
To backfill the missed executions, go to the Triggers tab on the Flow’s detail page and click on the Backfill executions button.
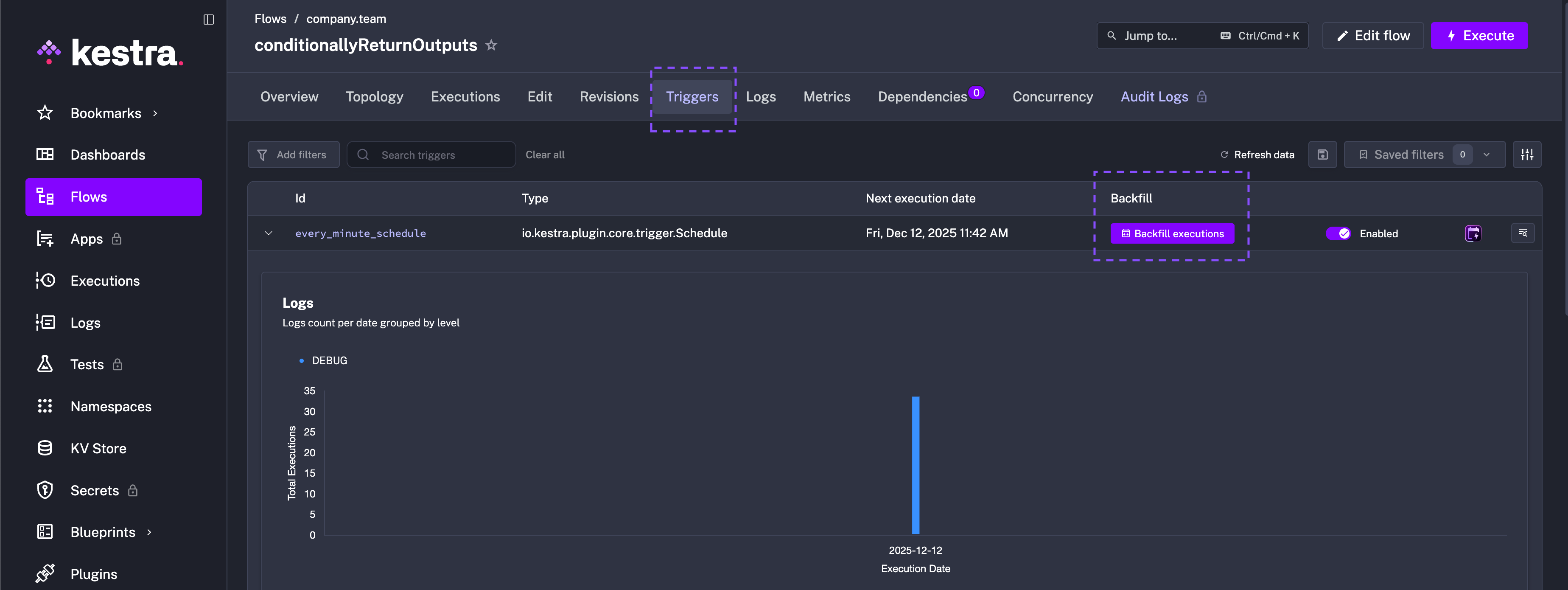
You can then select the start and end date for the backfill. Additionally, you can set custom labels for the backfill executions to help you identify them in the future.
You can pause and resume the backfill process at any time:
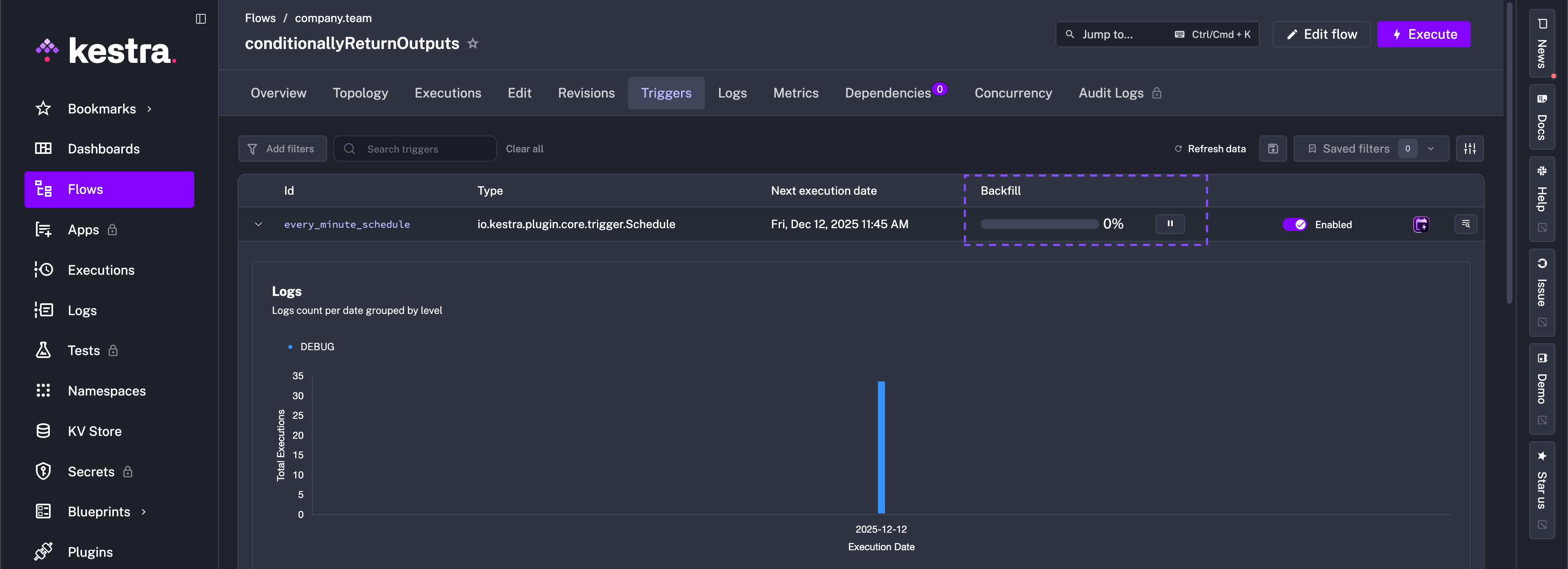
And by clicking on the Details button, you can see more details about that backfill process:
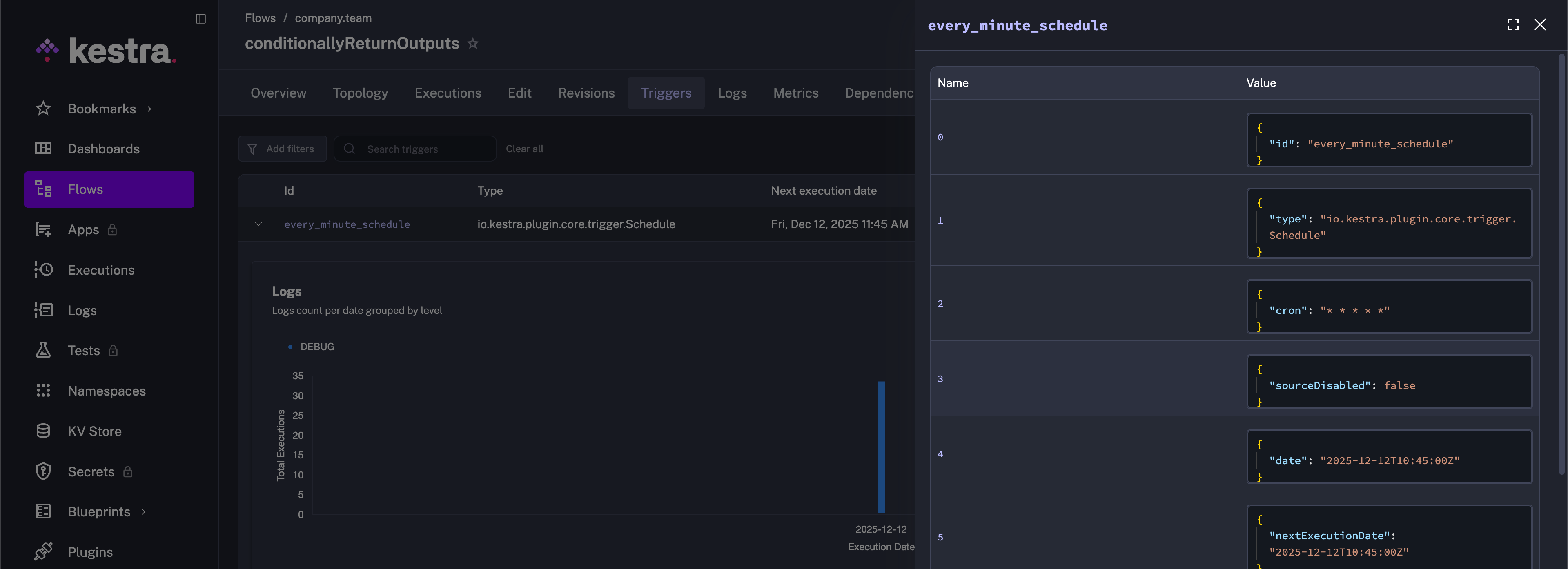
Backfill executions will not be processed if the associated trigger is disabled.
Delete a backfill
You can delete a Backfill from the Administrations - Triggers view. Select the triggers you’d like to delete Backfills for if you do not want to replay any missed executions.
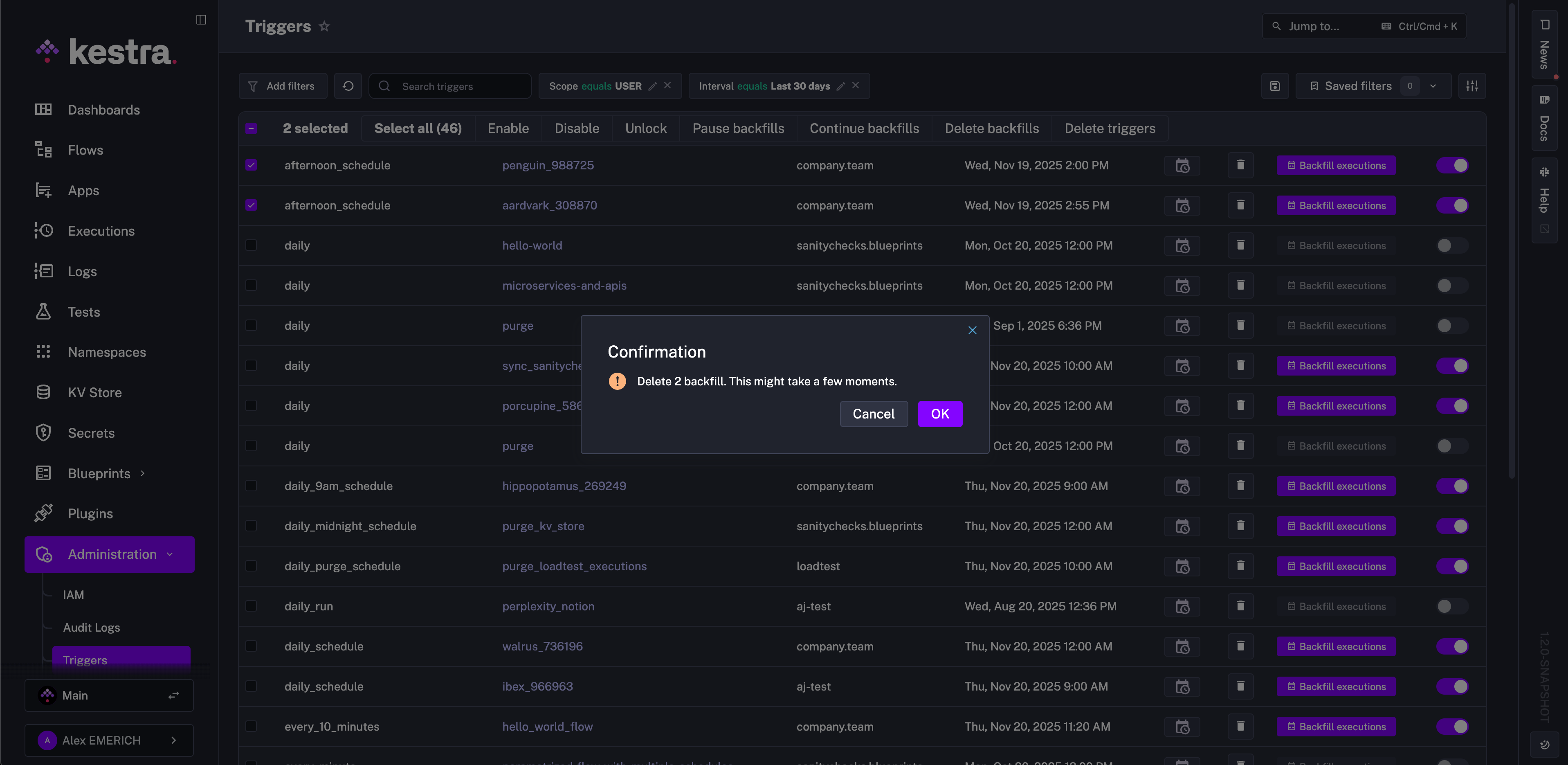
Deleting a backfill only cancels the scheduled catch-up executions. For example, if you defined a * * * * * schedule and backfilled the last five minutes, removing that backfill prevents those five replayed runs from being emitted. This is different from Delete trigger, which clears the trigger state itself — effectively recreating the trigger so it starts evaluating from the current time. Use Delete backfill to stop pending replays, and Delete trigger when you need to reset a stuck trigger or start it fresh.
Trigger backfill via an API call
Using cURL
You can invoke the backfill executions using the cURL call as follows:
curl -X PUT http://localhost:8080/api/v1/main/triggers \ -H "Authorization: Bearer $KESTRA_API_TOKEN" \ -H "Content-Type: application/json" \ -d '{ "namespace": "company.team", "flowId": "myflow", "triggerId": "schedule", "backfill": { "start": "2025-04-29T11:30:00Z", "end": null, "labels": [ { "key": "reason", "value": "outage" } ] } }'In the backfill attribute, you need to provide the start time for the backfill; the end time can be optionally provided. You can provide inputs to the flow with inputs, as well as assign labels to the backfill executions by providing key-value pairs in the labels section. In the example reason:outage is labelled to make it clear what caused the need to backfill.
Other attributes in this PUT call are flowId, namespace, and triggerId, corresponding to the flow to backfill.
Check out the API Reference for further backfill operations via the API.
Using a service account
Available on:
v>=0.15Enterprise EditionCloudFor Enterprise and Cloud users, the same process as above can be done with Service Accounts, so no human user needs to be involved. In this case, you must specify the Tenant to use in the request header and definition: X-KESTRA-TENANT and tenantId. In the example, we use a Tenant named production.
curl -X PUT http://localhost:8080/api/v1/main/triggers \ -H "Authorization: Bearer $KESTRA_API_TOKEN" \ -H "X-Kestra-Tenant: production" \ -H "Content-Type: application/json" \ -d '{ "namespace": "company.team", "flowId": "myflow", "triggerId": "schedule", "tenantId": "production", "backfill": { "start": "2025-04-29T11:30:00Z", "end": null, "labels": [ { "key": "reason", "value": "outage" } ] } }'To use a Service Account, go to Administration -> IAM -> Service Accounts. From the Service Accounts tab, create a Service Account, generate an API Token, copy the token, and give the Service Account the appropriate access to backfill a flow. Use this API token in your cURL instead of a user’s token.
The interactive demo below walks through the steps one-by-one.
Using Python requests
You can invoke the backfill executions using Python requests as follows:
import requestsimport json
url = 'http://localhost:8080/api/v1/main/triggers'
headers = { 'Content-Type': 'application/json'}
data = { "backfill": { "start": "2025-06-03T06:30:00.000Z", "end": None, "inputs": None, "labels": [ { "key": "reason", "value": "outage" } ] }, "flowId": "myflow", "namespace": "company.team", "triggerId": "schedule"}
response = requests.put(url, headers=headers, data=json.dumps(data))
print(response.status_code)print(response.text)With this code, you will be invoking the backfill for scheduled_flow flow under company.team namespace based on schedule trigger ID within the flow. The number of backfills that will be executed will depend on the schedule present in the schedule trigger and the start and end times mentioned in the backfill. When the end time is null, as in this case, the end time would be considered as the present time.
Was this page helpful?