Choosing Between Task Runners and Worker Groups in Kestra
For the complete documentation index, see llms.txt. For a full content snapshot, see llms-full.txt. Append.mdto anykestra.io/docs/*URL for plain Markdown.
Find out when to use Task Runners or Worker Groups.
Choose between task runners and worker groups
Task Runners and Worker Groups both offload compute-intensive tasks to dedicated workers. However, worker groups have a broader scope, applying to all tasks in Kestra, whereas task runners are limited to scripting tasks (Python, R, JavaScript, Shell, dbt, etc. — see the full list here). Worker groups can be used with any plugins.
For instance, if you need to query an on-premise SQL Server database running on a different server than Kestra, your SQL Server Query task can target a worker with access to that server. Additionally, worker groups can fulfill the same use case as task runners by distributing the load of scripting tasks to dedicated workers with the necessary resources and dependencies (incl. hardware, region, network, operating system).
Key differences
Worker groups are always-on servers that can run any task in Kestra, while task runners are ephemeral containers that are spun up only when a task is executed. This has implications with respect to latency and cost:
- Worker groups start executing tasks immediately — latency is milliseconds. Task runners must provision compute before execution, which can take seconds to over a minute. For example:
- AWS Batch (ECS Fargate): up to 50 seconds to register a job definition and start the container.
- Google Batch without a reservation: up to 90 seconds because GCP provisions a new compute instance per task.
- Task runners can be more cost-effective for infrequent short-lived tasks, while worker groups are more cost-effective for frequent and long-running tasks.
- Worker Groups work at the task level, whereas Task Runners are only available for some task types, such as Scripts, Commands, and CLI tasks.
The table below summarizes the differences between task runners and worker groups.
| Task Runners | Worker Groups | |
|---|---|---|
| Scope | Limited to scripting tasks | Applicable to all tasks in Kestra |
| Use Cases | Scripting tasks (Python, R, etc.) | Any task, including database queries |
| Deployment | Ephemeral containers | Always-on servers |
| Resource Handling | Spins up as needed | Constantly available |
| Latency | High latency (seconds, up to minutes) | Low latency (milliseconds) |
| Cost Efficiency | Suitable for infrequent tasks | Suitable for frequent or long-running tasks |
Worker Groups are not yet available in Kestra Cloud, only in Kestra Enterprise Edition.
Use cases
Here are common use cases in which Worker Groups can be beneficial:
- Execute tasks and polling triggers on specific servers (e.g., a VM with access to your on-premise database or a server with preconfigured CUDA drivers).
- Execute tasks and polling triggers on a worker with a specific Operating System (e.g., a Windows server configured with specific software needed for a task).
- Restrict backend access to a set of workers (firewall rules, private networks, etc.).
Here are common use cases in which Task Runners can be beneficial:
- Offload compute-intensive tasks to compute resources provisioned on-demand.
- Run tasks that temporarily require more resources than usual e.g., during a backfill or a nightly batch job.
- Run tasks that require specific dependencies or hardware (e.g., GPU, memory, etc.).
Usage
Worker Groups usage
First, start the worker with the --worker-group myWorkerGroupKey flag. It’s important for the new worker to have a configuration similar to that of your principal Kestra server and to have access to the same backend database and internal storage. The configuration file will be passed via the --config flag, as shown in the example below.
kestra server worker --worker-group=myWorkerGroupKey --config=/path/to/kestra-config.yamlTo assign a task to the desired worker group, add a workerGroup.key property. This will ensure that the task or polling trigger is executed on a worker in the specified worker group.
id: myflownamespace: company.team
tasks: - id: gpu type: io.kestra.plugin.scripts.python.Commands namespaceFiles: enabled: true commands: - python ml_on_gpu.py workerGroup: key: myWorkerGroupKeyA default worker group can also be configured at the namespace level so that all tasks and polling triggers in that namespace are executed on workers in that worker group by default.
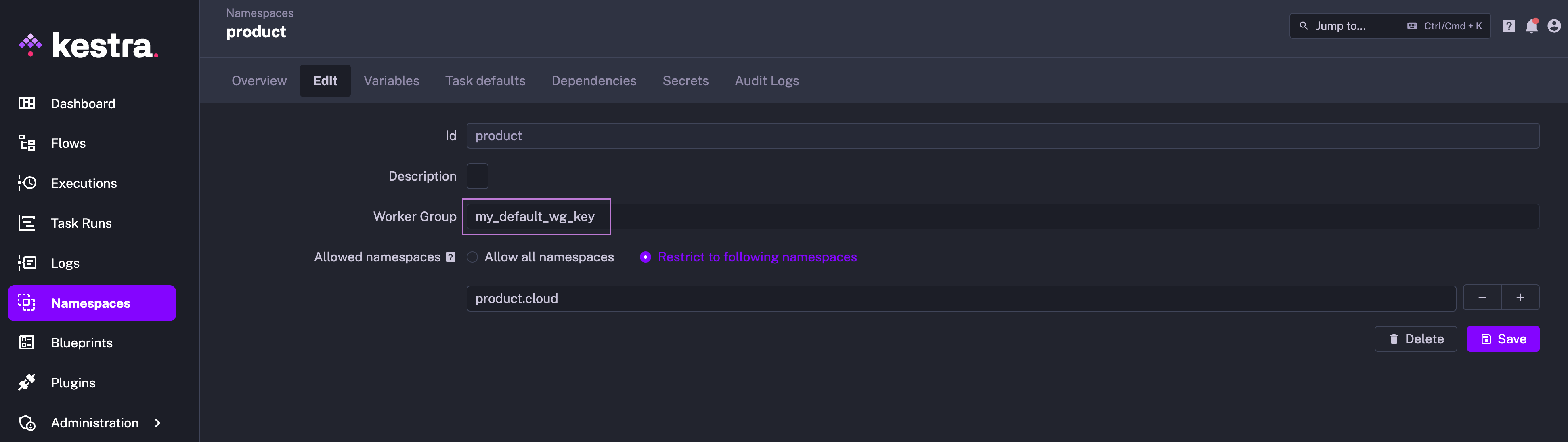
Task Runners usage
To use a task runner, add a taskRunner property to your task configuration and choose the desired type of task runner. For example, to use the AWS Batch task runner, you would configure your task as follows:
id: aws_ecs_fargate_pythonnamespace: company.team
tasks: - id: run_python type: io.kestra.plugin.scripts.python.Script containerImage: ghcr.io/kestra-io/pydata:latest taskRunner: type: io.kestra.plugin.ee.aws.runner.Batch computeEnvironmentArn: "arn:aws:batch:eu-west-1:707969873520:compute-environment/kestraFargateEnvironment" jobQueueArn: "arn:aws:batch:eu-west-1:707969873520:job-queue/kestraJobQueue" executionRoleArn: "arn:aws:iam::707969873520:role/kestraEcsTaskExecutionRole" taskRoleArn: "arn:aws:iam::707969873520:role/ecsTaskRole" accessKeyId: "{{ secret('AWS_ACCESS_KEY_ID') }}" secretKeyId: "{{ secret('AWS_SECRET_ACCESS_KEY') }}" region: eu-west-1 bucket: kestra-ie script: | import platform import socket import sys
def print_environment_info(): print("Hello from AWS Batch and kestra!") print(f"Host's network name: {platform.node()}") print(f"Python version: {platform.python_version()}") print(f"Platform information (instance type): {platform.platform()}") print(f"OS/Arch: {sys.platform}/{platform.machine()}")
try: hostname = socket.gethostname() ip_address = socket.gethostbyname(hostname) print(f"Host IP Address: {ip_address}") except socket.error as e: print("Unable to obtain IP address.")
if __name__ == '__main__': print_environment_info()Was this page helpful?