Run Flows on a Cron Schedule with Backfills and Conditions
For the complete documentation index, see llms.txt. For a full content snapshot, see llms-full.txt. Append.mdto anykestra.io/docs/*URL for plain Markdown.
Schedule flows using cron expressions.
The Schedule trigger generates new executions on a regular cadence based on a Cron expression or custom scheduling conditions.
type: io.kestra.plugin.core.trigger.ScheduleKestra can trigger flows on a defined schedule. If you need to wait for another system to be ready and no event mechanism is available, you can configure one or more time-based schedules for your flow.
Kestra can automatically handle backfills to recover missed executions.
Check the Schedule task documentation for the list of the task properties and outputs.
To avoid unexpected differences, keep your Kestra server and database timezones aligned. If this isn’t possible, account for timezone implications such as Daylight Saving Time or regional variations.
Cron extension
Kestra supports the following cron extensions instead of writing a cron expression:
@yearlyand@annually- runs yearly on 1st January at00:00@monthly- runs monthly on the 1st at00:00@weekly- runs weekly on Sunday at00:00@dailyand@midnight- runs at00:00every day@midnight- runs at00:00every day@hourly- runs every hour, on the hour
Examples
Schedule that runs every 15 minutes:
triggers: - id: schedule type: io.kestra.plugin.core.trigger.Schedule cron: "*/15 * * * *"Schedule that runs only on the first monday of every month at 11 AM:
triggers: - id: schedule type: io.kestra.plugin.core.trigger.Schedule cron: "0 11 * * 1" conditions: - type: io.kestra.plugin.core.condition.DayWeekInMonth date: "{{ trigger.date }}" dayOfWeek: "MONDAY" dayInMonth: "FIRST"A schedule that runs daily at midnight US Eastern time:
triggers: - id: daily type: io.kestra.plugin.core.trigger.Schedule cron: "@daily" timezone: America/New_YorkSchedule that runs on the last day of month:
The Schedule trigger also supports L in the day-of-month field to represent the last day of the month.
For example:
triggers: - id: month_end type: io.kestra.plugin.core.trigger.Schedule cron: "0 12 L * *"This runs at 12:00 on the last day of every month, including shorter months like February.
Schedules cannot overlap, meaning concurrent schedule executions are not allowed. If the previous schedule is not ended when the next one must start, the scheduler will wait until the end of the previous one. The same applies during backfills.
By default, schedule executions depend on trigger.date. For example, this may be used when querying files or databases by date. However, this prevents manual execution since trigger.date is only available for scheduled runs.
You can use this expression to make your manual execution work: {{ trigger.date ?? execution.startDate | date("yyyy-MM-dd") }}. It will use the current date if there is no schedule date making it possible to start the flow manually.
Schedule conditions
When a cron expression alone is not sufficient (e.g., only first Monday of the month, only weekends), you can refine schedules using conditions.
You must use the {{ trigger.date }} expression on the property date of the current schedule.
This condition will be evaluated and {{ trigger.previous }} and {{ trigger.next }} will reflect the date with the conditions applied.
The list of core conditions that can be used are:
Here’s an example using the DayWeek condition:
id: conditionsnamespace: company.team
tasks: - id: hello type: io.kestra.plugin.core.log.Log message: This will execute only on Thursday!
triggers: - id: schedule type: io.kestra.plugin.core.trigger.Schedule cron: "@hourly" conditions: - type: io.kestra.plugin.core.condition.DayWeek dayOfWeek: "THURSDAY"Recover missed schedules
Automatically
By default, Kestra automatically recovers missed schedules. This means that if the Kestra server is down, the missed schedules will be executed as soon as the server is back up. However, this behavior is not always desirable, e.g. during a planned maintenance window. This behavior can be disabled by setting the recoverMissedSchedules configuration to NONE.
Configure recoverMissedSchedules behavior in your global Kestra configuration to choose whether you want to recover missed schedules automatically or not:
kestra: plugins: configurations: - type: io.kestra.plugin.core.trigger.Schedule values: # available options: LAST | NONE | ALL -- default: ALL recoverMissedSchedules: NONEThe recoverMissedSchedules configuration can be set to ALL, NONE or LAST:
ALL: Kestra will recover all missed schedules. This is the default value.NONE: Kestra will not recover any missed schedules.LAST: Kestra will recover only the last missed schedule for each flow.
Note that this is a global configuration that will apply to all flows, unless other behavior is explicitly defined within the flow definition like below:
triggers: - id: schedule type: io.kestra.plugin.core.trigger.Schedule cron: "*/15 * * * *" recoverMissedSchedules: NONEIn this example, the recoverMissedSchedules is set to NONE, which means that Kestra will not recover any missed schedules for this specific flow regardless of the global configuration or default recoverMissedSchedules behavior. If you have a missed window of executions with recoverMissedSchedules: NONE, then use Backfill to replay the missed executions.
Using Backfill
Backfills are replays of missed schedule intervals between a defined start and end date.
To backfill the missed executions, go to the Triggers tab on the flow’s detail page and click on the Backfill executions button.
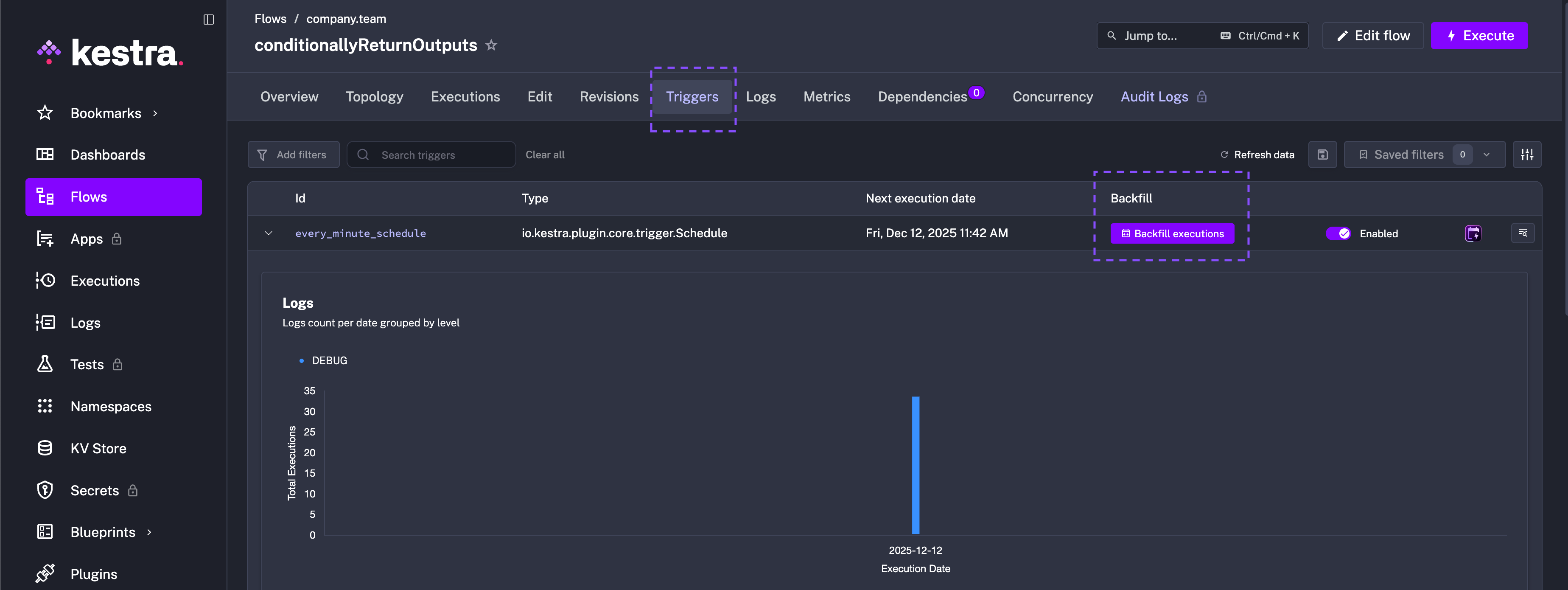
Note: Ensure the backfill date range spans every missed schedule so the trigger can replay each execution.
For more information on Backfill, check out the dedicated documentation.
Disabling the trigger
If you are unsure how to proceed, you can temporarily disable the trigger by setting disabled: true in the YAML or toggling it in the UI.
This is useful if you are figuring out what to do before the next schedule is due to run.
For more information on Disabled, check out the dedicated documentation.
Setting inputs inside of the schedule trigger
You can easily pass inputs to the Schedule Trigger by using the inputs property and passing them as a key-value pair.
In this example, the user input is set to “John Smith” inside of the schedule trigger:
id: myflownamespace: company.team
inputs: - id: user type: STRING defaults: Rick Astley
tasks: - id: hello type: io.kestra.plugin.core.log.Log message: "Hello {{ inputs.user }}! 🚀"
triggers: - id: schedule type: io.kestra.plugin.core.trigger.Schedule cron: "*/1 * * * *" inputs: user: John SmithDisable a schedule trigger after a specified execution state
Schedule triggers have an optional property, stopAfter, that disables a trigger after a specified execution state has been reached: for example, SUCCESS, FAILED, KILLED, SKIPPED, etc. Refer to the Schedule Trigger documentation for more property details.
For example, you may want to disable a trigger for a FAILED or KILLED flow to avoid multiple runs of that flow that is misconfigured and needs attention. The property is added to the trigger definition like below:
id: myflownamespace: company.team
inputs: - id: user type: STRING defaults: Rick Astley
tasks: - id: hello type: io.kestra.plugin.core.log.Log message: "Hello {{ inputs.user }}! 🚀"
triggers: - id: schedule type: io.kestra.plugin.core.trigger.Schedule cron: "*/1 * * * *" stopAfter: - FAILED - KILLED inputs: user: John SmithDetect stuck Schedule Triggers
Kestra has a plugin, ScheduleMonitor, for detecting stuck or misconfigured Schedule Triggers. It checks periodically and can run at the Tenant level, for a specific Namespace, or for a single Flow.
For example, set this up as a System Flow and send an alert if any Schedule Triggers come back showing an issue:
id: detect_stuck_schedulesnamespace: system
tasks: - id: send_alert runIf: "{{ trigger.data }}" type: io.kestra.plugin.slack.notifications.SlackIncomingWebhook url: https://kestra.io/api/mock messageText: The following Schedule triggers seem unhealthy {{ trigger.data }}
triggers: - id: stuck_schedules type: io.kestra.plugin.kestra.triggers.ScheduleMonitor auth: username: admin@kestra.io # pass your Kestra username as secret password: Admin1234 # pass your Kestra password as secret namespace: company.team flowId: daily_sync interval: PT1H # poll for stuck schedules every 1hBy default, the trigger checks all schedules in the current Tenant (Multi-tenancy is an Enterprise feature) if no Namespace or Flow is specified.
Was this page helpful?