Re-run Any Workflow Execution from a Chosen Task
For the complete documentation index, see llms.txt. For a full content snapshot, see llms-full.txt. Append.mdto anykestra.io/docs/*URL for plain Markdown.
Replay allows you to re-run a workflow execution from any chosen task run.
By using Replay, you can re-run a workflow execution from any selected task run. To do that, simply go to the Gantt view of the chosen workflow execution (it doesn’t need to be a Failed execution, it can be an execution in any state) and click on the task run you want to re-run. Additionally, you can re-run an execution or bulk executions from the Executions tab with the option to use the latest revision.
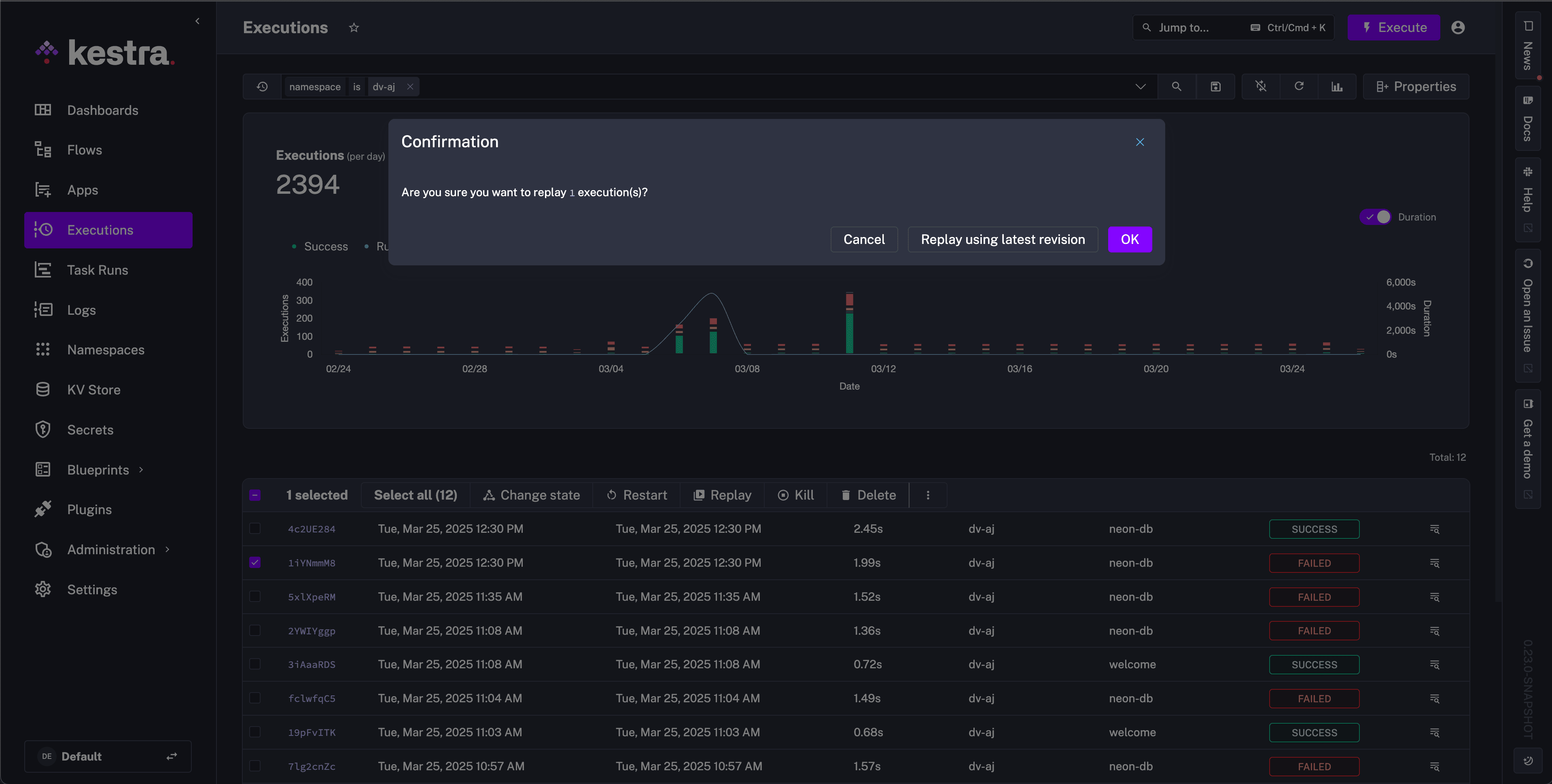
Replays are extremely useful for iterative development and reprocessing data.
Imagine the following scenario: you have a workflow that extracts a large compressed CSV dataset and you want to transform it into a Parquet file with a specific schema.
id: divvy_tripdatanamespace: company.team
variables: file_id: "{{ execution.startDate | dateAdd(-3, 'MONTHS') | date('yyyyMM') }}"
tasks: - id: get_zipfile type: io.kestra.plugin.core.http.Download uri: "https://divvy-tripdata.s3.amazonaws.com/{{ render(vars.file_id) }}-divvy-tripdata.zip"
- id: unzip type: io.kestra.plugin.compress.ArchiveDecompress algorithm: ZIP from: "{{ outputs.get_zipfile.uri }}"
- id: convert type: io.kestra.plugin.serdes.csv.CsvToIon from: "{{outputs.unzip.files[render(vars.file_id) ~ '-divvy-tripdata.csv']}}"
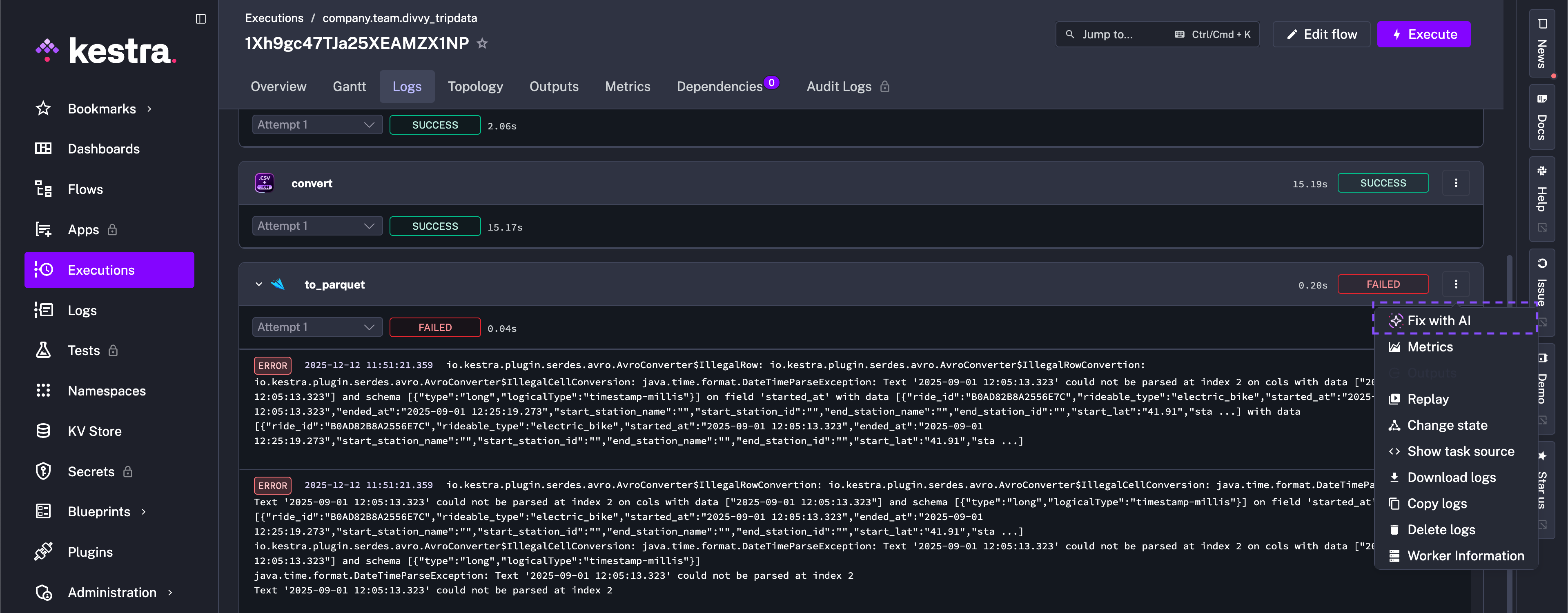
- id: to_parquet type: io.kestra.plugin.serdes.avro.IonToAvro # render(vars.file_id) from: "{{ outputs.convert.uri }}" datetimeFormat: "yy-MM-dd' 'HH:mm:ss" schema: | { "type": "record", "name": "Ride", "namespace": "com.example.bikeshare", "fields": [ {"name": "ride_id", "type": "string"}, {"name": "rideable_type", "type": "string"}, {"name": "started_at", "type": {"type": "long", "logicalType": "timestamp-millis"}}, {"name": "ended_at", "type": {"type": "long", "logicalType": "timestamp-millis"}}, {"name": "start_station_name", "type": "string"}, {"name": "start_station_id", "type": "string"}, {"name": "end_station_name", "type": "string"}, {"name": "end_station_id", "type": "string"}, {"name": "start_lat", "type": "double"}, {"name": "start_lng", "type": "double"}, { "name": "end_lat", "type": ["null", "double"], "default": null }, { "name": "end_lng", "type": ["null", "double"], "default": null }, {"name": "member_casual", "type": "string"} ] }When you run the above workflow, you should see an error in the to_parquet task.
From the logs, you are able to see that the error is due to a misconfigured date format in the datetimeFormat field — in fact, the date format should have a full year, not just a two-digit year: "yyyy-MM-dd' 'HH:mm:ss".
You ask AI to fix the flow for you, or you correct the error yourself in the workflow code and save it.
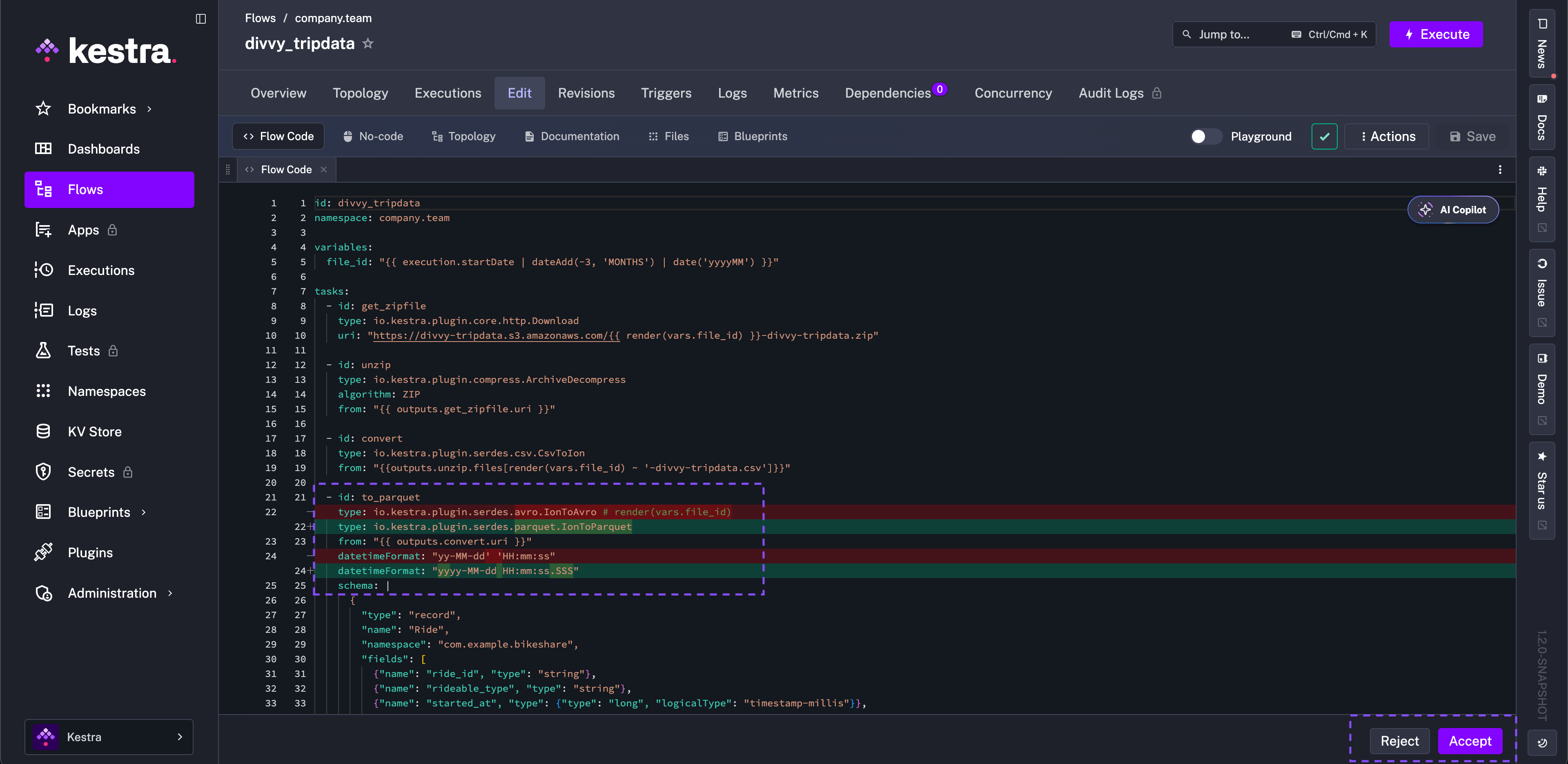
Full corrected flow code
id: divvy_tripdatanamespace: company.team
variables: file_id: "{{ execution.startDate | dateAdd(-3, 'MONTHS') | date('yyyyMM') }}"
tasks: - id: get_zipfile type: io.kestra.plugin.core.http.Download uri: "https://divvy-tripdata.s3.amazonaws.com/{{ render(vars.file_id) }}-divvy-tripdata.zip"
- id: unzip type: io.kestra.plugin.compress.ArchiveDecompress algorithm: ZIP from: "{{ outputs.get_zipfile.uri }}"
- id: convert type: io.kestra.plugin.serdes.csv.CsvToIon from: "{{outputs.unzip.files[render(vars.file_id) ~ '-divvy-tripdata.csv']}}"
- id: to_parquet type: io.kestra.plugin.serdes.parquet.IonToParquet from: "{{ outputs.convert.uri }}" datetimeFormat: "yyyy-MM-dd HH:mm:ss.SSS" schema: | { "type": "record", "name": "Ride", "namespace": "com.example.bikeshare", "fields": [ {"name": "ride_id", "type": "string"}, {"name": "rideable_type", "type": "string"}, {"name": "started_at", "type": {"type": "long", "logicalType": "timestamp-millis"}}, {"name": "ended_at", "type": {"type": "long", "logicalType": "timestamp-millis"}}, {"name": "start_station_name", "type": "string"}, {"name": "start_station_id", "type": "string"}, {"name": "end_station_name", "type": "string"}, {"name": "end_station_id", "type": "string"}, {"name": "start_lat", "type": "double"}, {"name": "start_lng", "type": "double"}, { "name": "end_lat", "type": ["null", "double"], "default": null }, { "name": "end_lng", "type": ["null", "double"], "default": null }, {"name": "member_casual", "type": "string"} ] }Now, you can go to the previously failed Execution and click on the to_parquet task run to re-run it (either from the Gantt or from the Logs view).
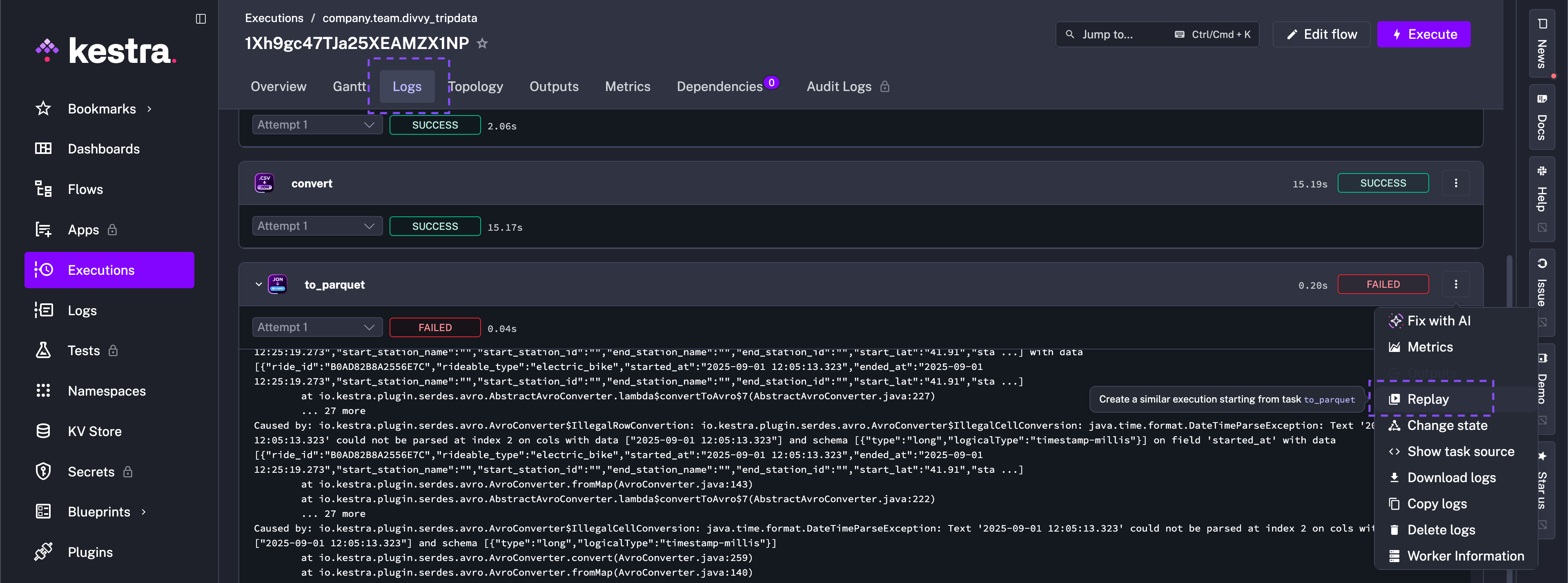
Now select the latest revision of the flow code that contains the fix.
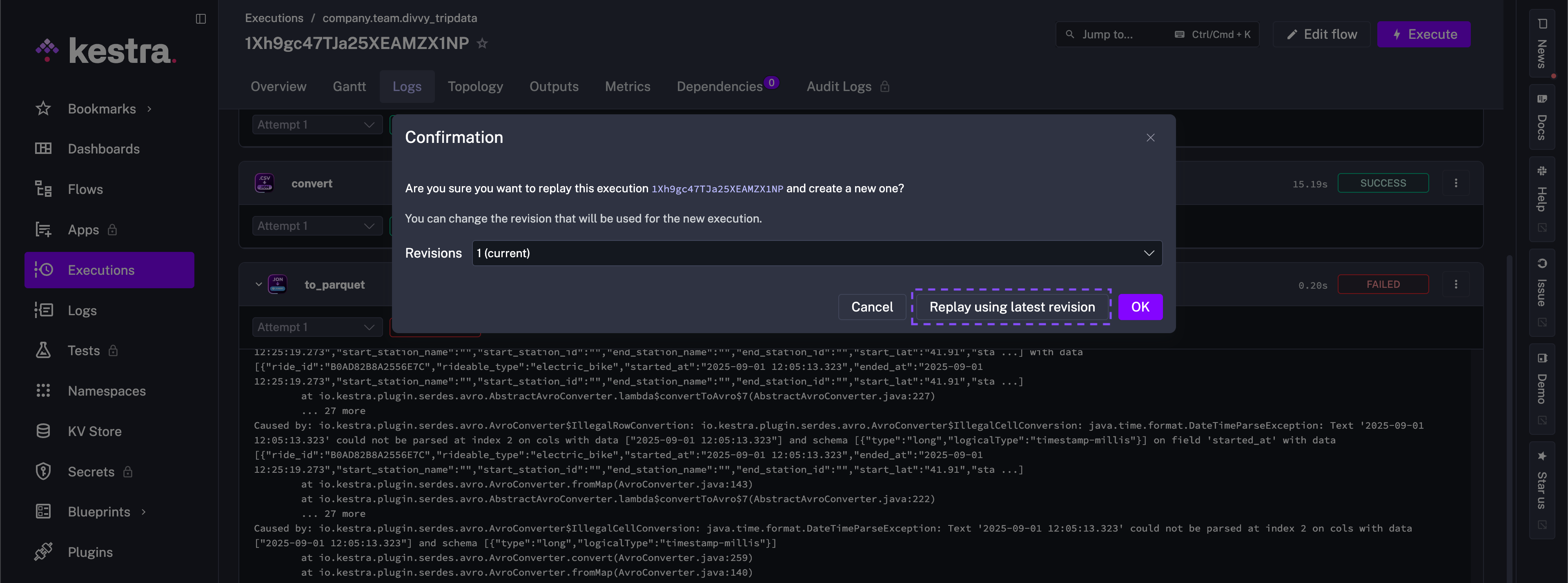
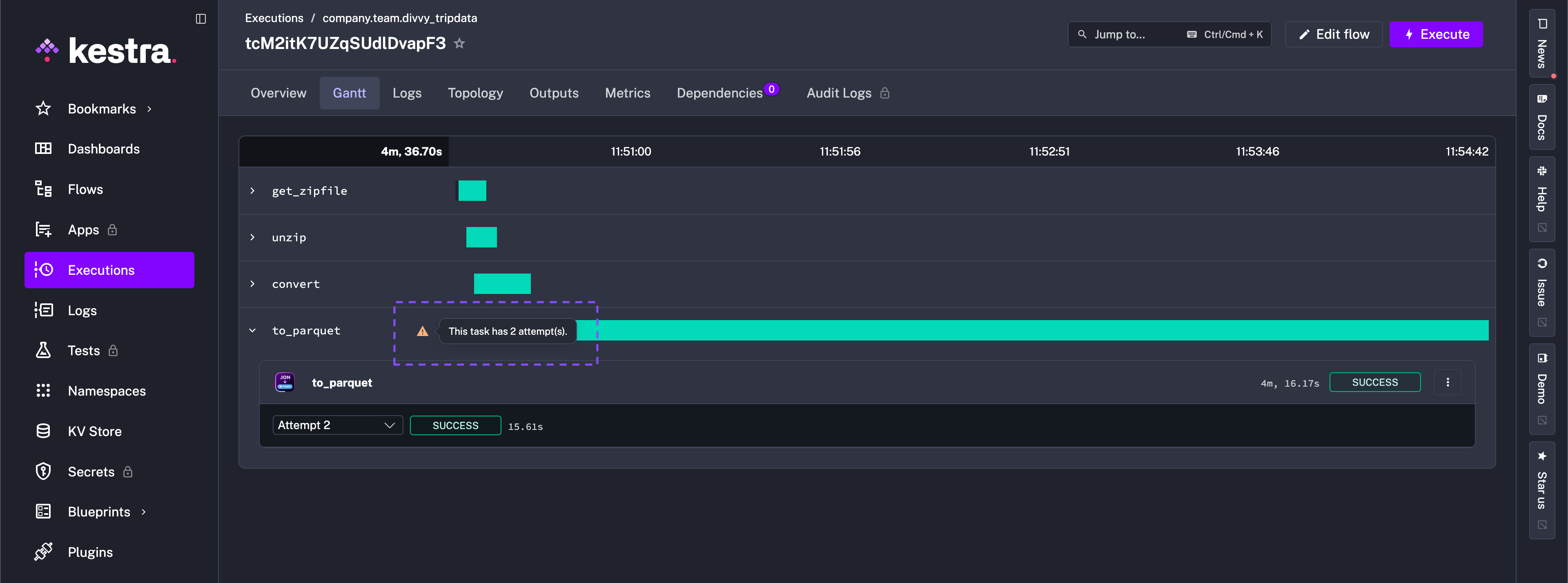
This re-runs the task with the new (corrected!) revision of the flow code. You can inspect the logs and verify that the task now completes successfully. The attempt number increments to show that this is a new run of the task.
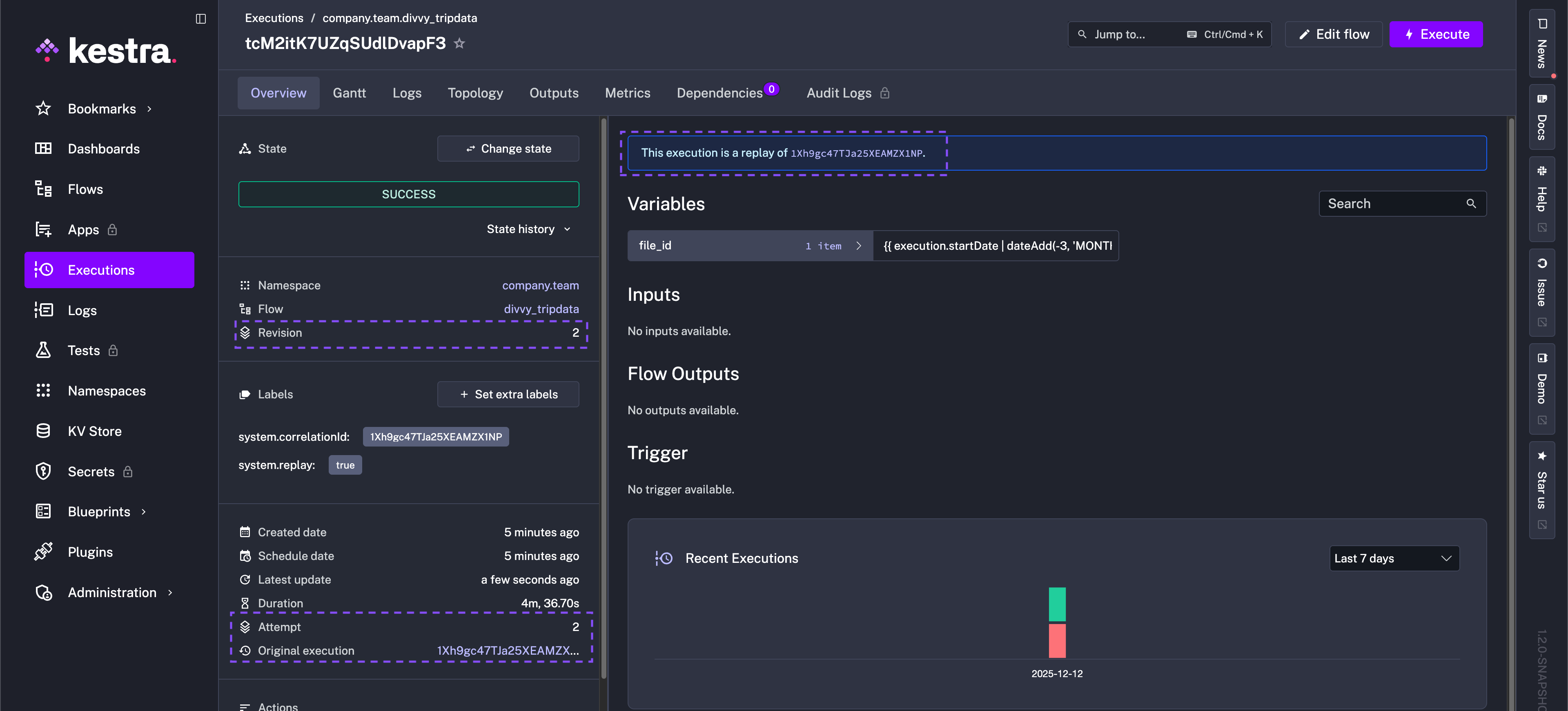
The Overview tab will additionally show the new attempt number and the new revision of the flow code that was used during Replay.
Replay lets you re-run a failed task with the corrected flow code without rerunning tasks that already completed successfully.
Was this page helpful?