 Worker Groups in Kestra Enterprise – Configure Targeted Workers
Worker Groups in Kestra Enterprise – Configure Targeted Workers
Available on: >= 0.10.0
How to configure Worker Groups in Kestra Enterprise Edition.
Worker groups – configure targeted workers
A Worker Group is a set of workers that can be explicitly targeted for task execution or polling trigger evaluation. For example, tasks that require heavy resources can be isolated to a Worker Group designed to handle that load, and tasks that perform best on a specific Operating System can be optimized to run on a Worker Group designed for them.
Please note that Worker Groups are not yet available in Kestra Cloud, only in Kestra Enterprise Edition.
Creating Worker Groups from the UI
To create a new Worker Group, navigate to the Instance page, go to the Worker Groups tab, and click on the + Add Worker Group button. Then, set a Key, a Description, and optionally Allowed Tenants for that worker group. You can also accomplish this via API, CLI, or Terraform.
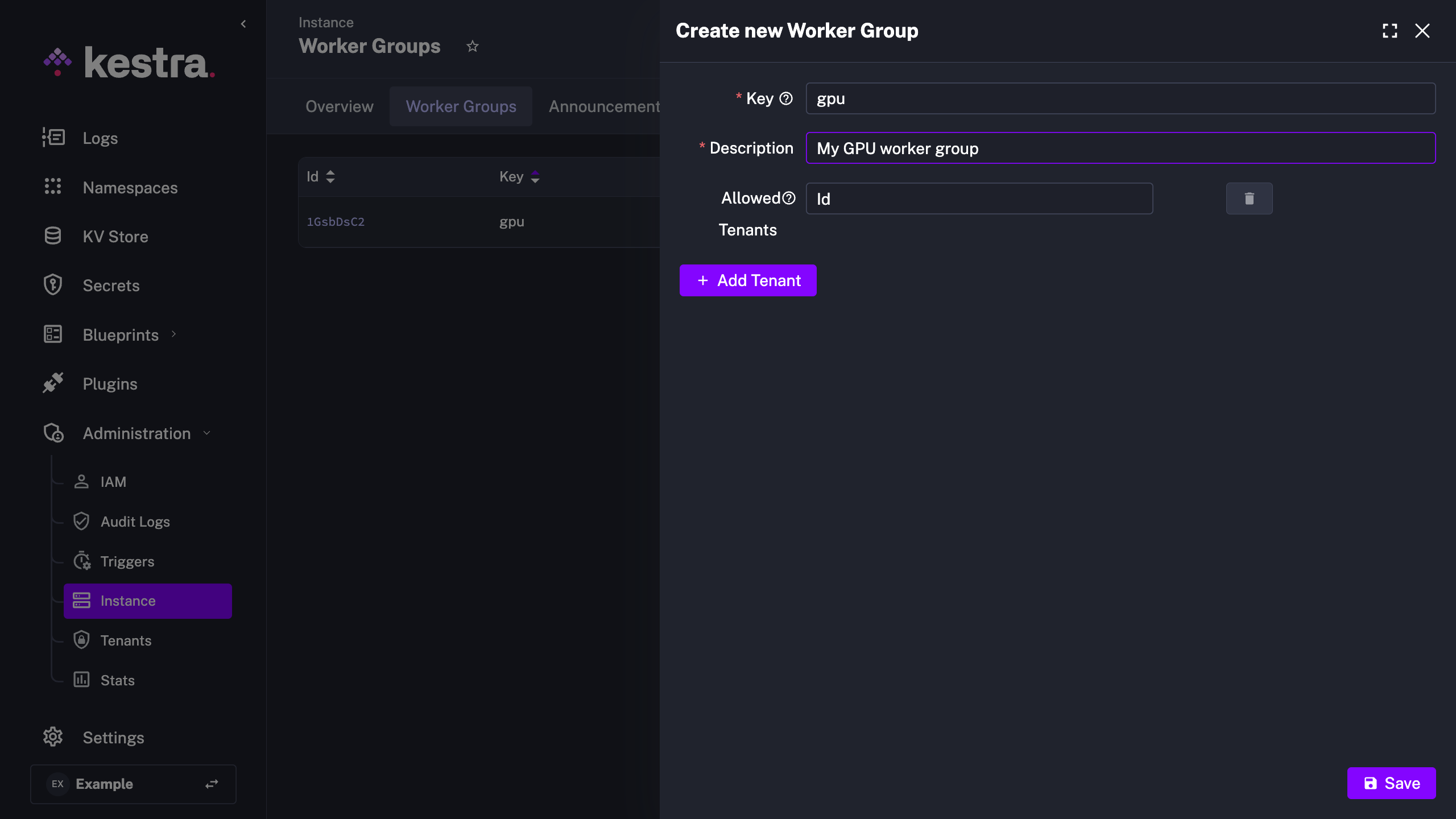
Starting workers for a Worker Group
Once a worker group key is created, you can start a worker with the kestra server worker --worker-group {workerGroupKey} flag to assign it to that worker group. You can also assign a default worker group at the namespace and tenant level.
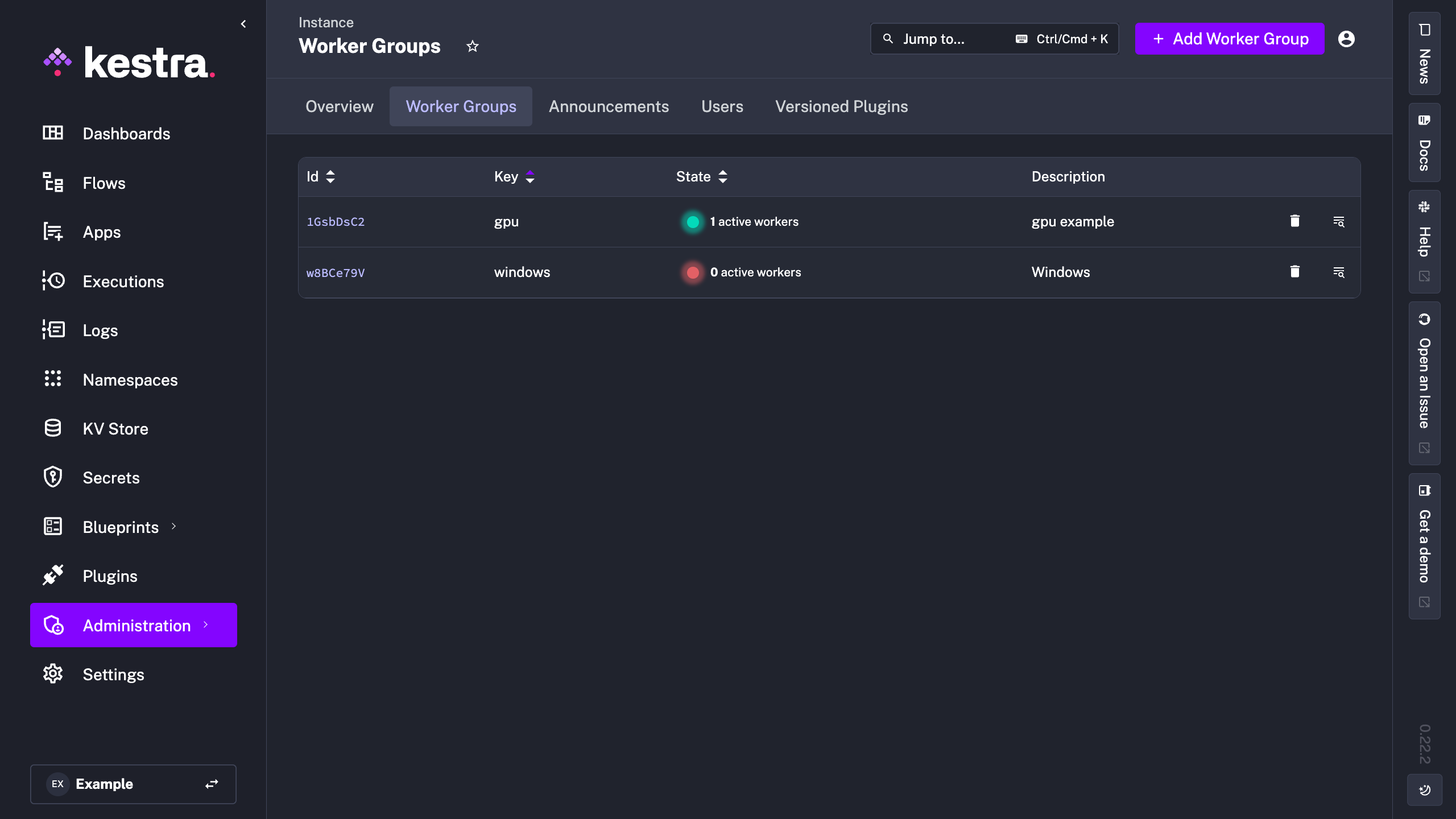
The Worker Groups UI tracks the health of worker groups, showing how many workers are polling for tasks within each worker group. This gives you visibility into which worker groups are active and the number of active workers.
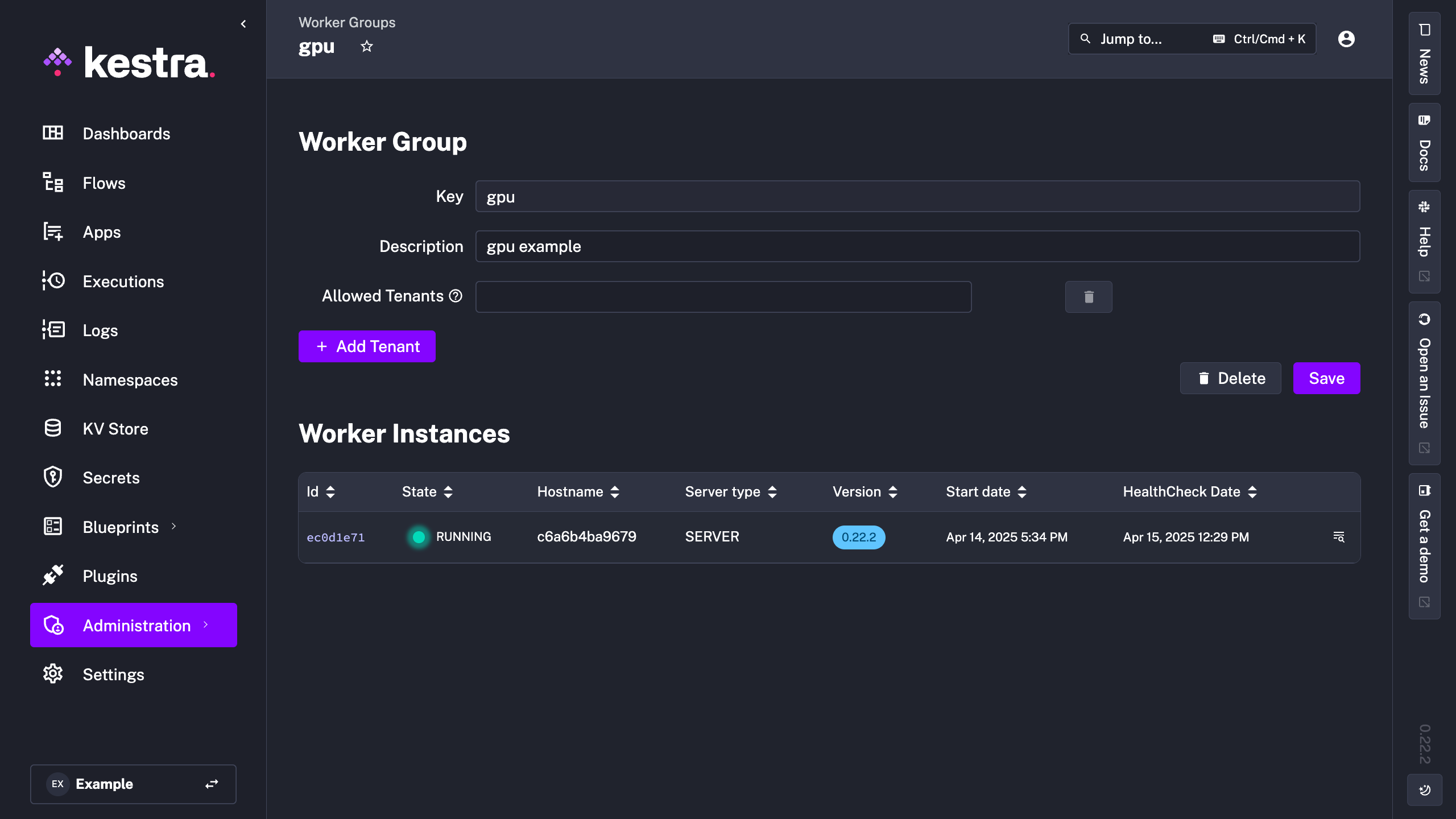
In order to run the command at startup, you need to run each component independently and use the command for the worker component startup. To set this up, read more about running Kestra with separated server components.
Using Worker Groups
To assign a worker group, add the workerGroup.key property to the task or the polling trigger. A default worker group can also be configured at the namespace or tenant level.
Worker groups can be defined at the flow level, and the flow editor validates worker group keys when creating flows from the UI. If the provided key doesn’t exist, the syntax validation will prevent the flow from being saved.
Below is an example flow configuration with a worker group:
id: worker_group
namespace: company.team
tasks:
- id: wait
type: io.kestra.plugin.scripts.shell.Commands
taskRunner:
type: io.kestra.plugin.core.runner.Process
commands:
- sleep 10
workerGroup:
key: gpu
If the workerGroup.key property is not provided, all tasks and polling triggers are executed on the default worker group. That default worker group doesn't have a dedicated key.
A workerGroup.key can also be assigned dynamically using inputs like in the following example:
id: worker_group_dynamic
namespace: company.team
inputs:
- id: my_worker_group
type: STRING
tasks:
- id: workerGroup
type: io.kestra.plugin.core.debug.Return
format: "{{ taskrun.startDate }}"
workerGroup:
key: "{{ inputs.my_worker_group }}"
Worker Group fallback behavior
By default, a task configured to run on a given worker will wait for the worker to be available (i.e., workerGroup.fallback: WAIT). If you prefer to fail the task when the worker is not available, set workerGroup.fallback: FAIL.
id: worker_group
namespace: company.team
tasks:
- id: wait
type: io.kestra.plugin.core.flow.Sleep
duration: PT0S
workerGroup:
key: gpu
fallback: FAIL
Possible values for workerGroup.fallback are WAIT (default), FAIL, or CANCEL:
WAIT: The task will wait for the worker to be available and will remain in aCREATEDstate until the worker picks it up.FAIL: The task run will be terminated immediately if the worker is not available, and the execution will be marked asFAILED.CANCEL: The task run will be gracefully terminated, and the execution will be marked asKILLEDwithout an error.
You can set a custom workerGroup.key and workerGroup.fallback per plugin type and/or per namespace using pluginDefaults.
When Fallback behavior is set in multiple places, Kestra resolves which action to take by following this priority order:
- Flow-Level: Uses the behavior specified in the
fallbackproperty of the Flow task. - Namespace-Level: Uses the behavior set in the the Namespace settings.
- Tenant-Level: Uses the behavior set in the the Tenant settings.
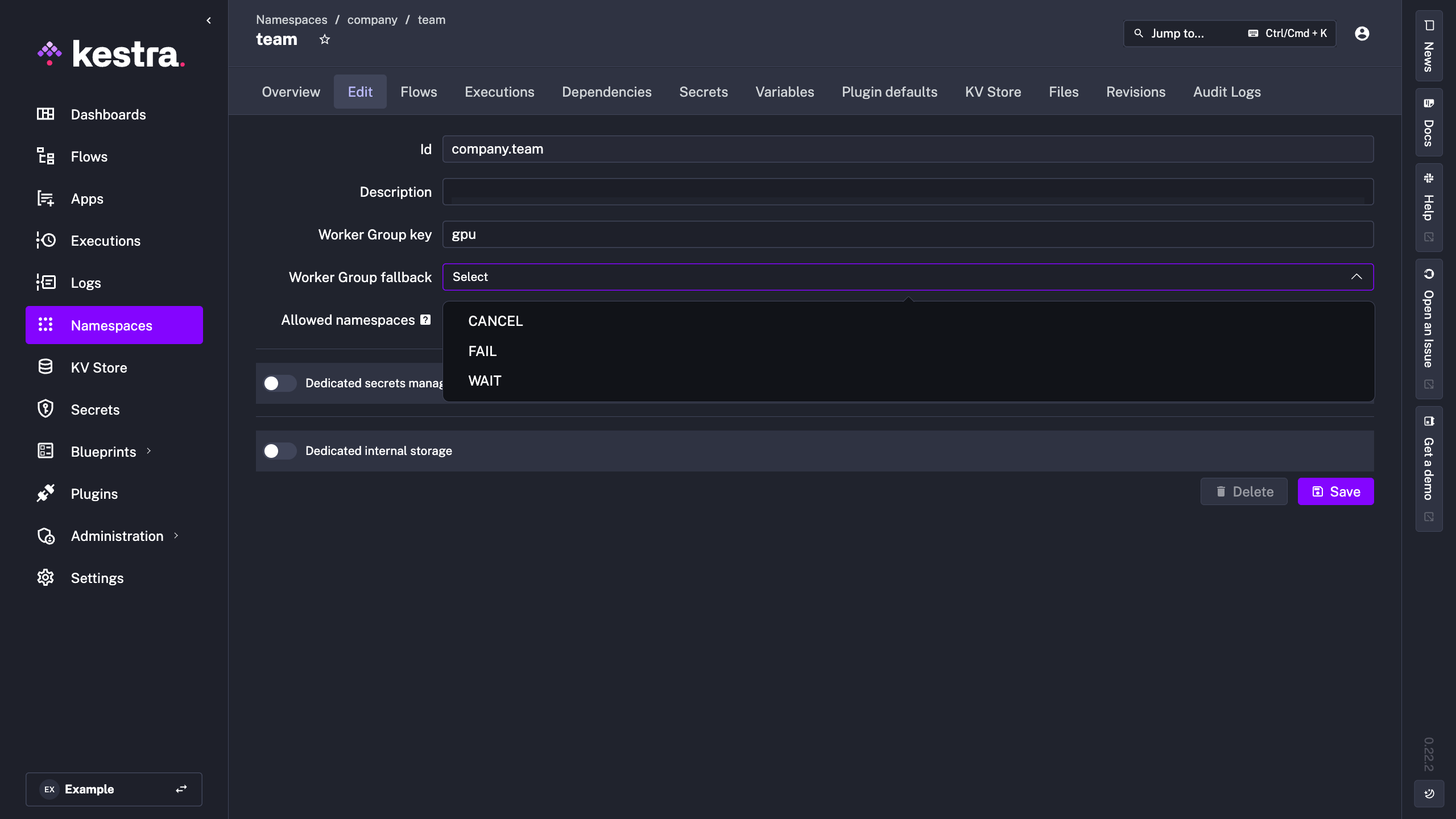
Fallback behavior at the namespace level
Namespaces can be configured to have a default fallback behavior. It can be configured by creating a namespace manaully or modifying in the Edit tab of the namespace.
Fallback behavior at the tenant level
Tenants can be configured to have a default fallback behavior. It can be configured when creating a tenant on in the tenant's properties.
When to use Worker Groups
Here are common use cases in which Worker Groups can be beneficial:
- Execute tasks and polling triggers on specific compute instances (e.g., a VM with a GPU and preconfigured CUDA drivers).
- Execute tasks and polling triggers on a worker with a specific Operating System (e.g., a Windows server).
- Restrict backend access to a set of workers (firewall rules, private networks, etc.).
- Execute tasks and polling triggers close to a remote backend (region selection).
You can configure plugin groups to use a specific worker group. In this example, all script tasks are set to run on the gpu worker group:
id: worker_group
namespace: company.team
tasks:
- id: wait
type: io.kestra.plugin.scripts.shell.Commands
taskRunner:
type: io.kestra.plugin.core.runner.Process
commands:
- sleep 10
- id: python_gpu
type: io.kestra.plugin.scripts.python.Commands
namespaceFiles:
enabled: true
commands:
- python ml_on_gpu.py
pluginDefaults:
- forced: false
type: io.kestra.plugin.scripts
values:
workerGroup:
key: gpu
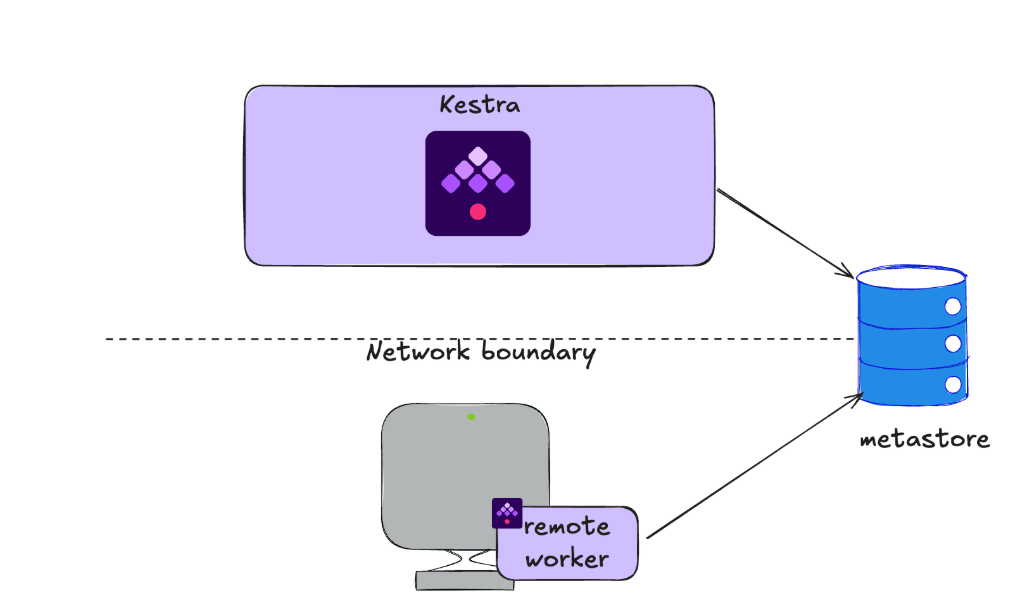
Distant workers
You can use a Worker Group to designate a worker to execute any task on a remote resource. Additionally, you may want to have an always-on worker that stays available for execution-intensive workloads.
The Distant Worker use case requires a connection to the Kestra metastore, and it solves for scenarios of always-on, intensive workloads and workloads that need to execute workloads on an external environment.
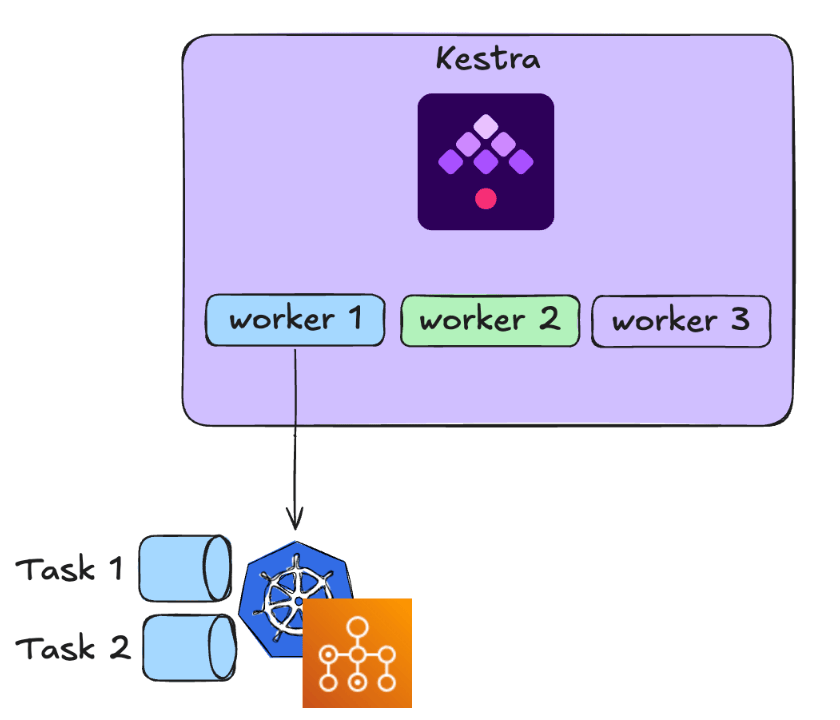
Task runners
If you are using scripting tasks, you can set up Worker Group of Task Runners to leverage on-demand cloud resources to execute intensive workloads. For example, you can have a Worker Group dedicated to executing on AWS Batch or Kubernetes.
This is particularly useful for script task workloads that have bursts in resource demand.
Data isolation
Worker Groups strongly fits Data Isolation use cases. Multi-tenancy requirements may demand that you have strict isolation of remote resources such as key vaults. Worker groups enable you to split out dedicated workers per tenant.
In the below architecture, it is not possible to execute tasks on worker 1 from tenant 3.
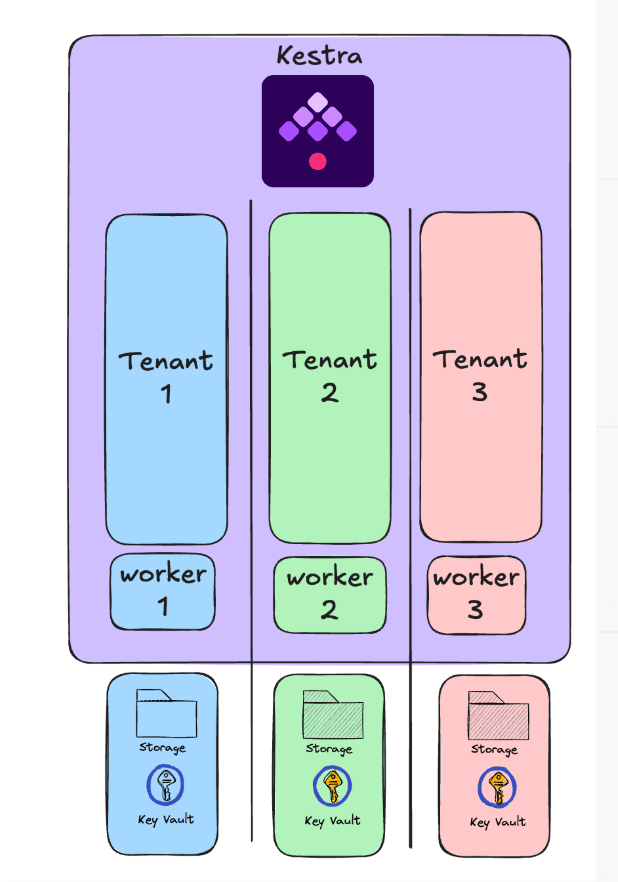
Even if you are using worker groups, we strongly recommend having at least one worker in the default worker group.
Load balancing
Whether you leverage worker groups or not, Kestra will balance the load across all available workers. The primary difference is that with worker groups, you can target specific workers for task execution or polling trigger evaluation.
A worker is part of a worker group if it is started with the --worker-group workerGroupKey argument.
There's a slight difference between Kafka and JDBC architectures in terms of load balancing:
- The Kafka architecture relies on Kafka consumer group protocol — each worker group will use a different consumer group protocol, therefore each worker group will balance the load independently.
- For JDBC, each worker within a group will poll the
queuesdatabase table using the same poll query. All workers within the same worker group will poll for task runs and polling triggers in a FIFO manner.
Central queue to distribute task runs and polling triggers
In both JDBC and Kafka architectures, we leverage a Central Queue to ensure that tasks and polling triggers are executed only once and in the right order.
Here's how it works:
- Jobs (task runs and polling triggers) are submitted to a centralized queue. The queue acts as a holding area for all incoming jobs.
- Workers periodically poll the central queue to check for available jobs. When a worker becomes free, it requests the next job from the queue.
- Kestra backend keeps track of assignment of jobs to workers to ensure reliable execution and prevent duplicate processing.
What if multiple workers from the same Worker Group poll for jobs from the central queue?
Whether the jobs (task runs and polling triggers) are evenly distributed among workers depends on several factors:
- The order in which workers poll the queue will affect distribution — workers that poll the queue first will get jobs first (FIFO).
- Variations in worker compute capabilities (and their processing speeds) can cause uneven job distribution. Faster workers will complete jobs and return to poll the queue more quickly than slower workers.
Was this page helpful?