Architecture
Kestra's architecture is designed to be scalable, flexible, and fault-tolerant. Depending on your needs, you can choose between two different architectures: JDBC and Kafka.
Architecture with JDBC backend
The following diagram shows the main components of Kestra using the JDBC backend.
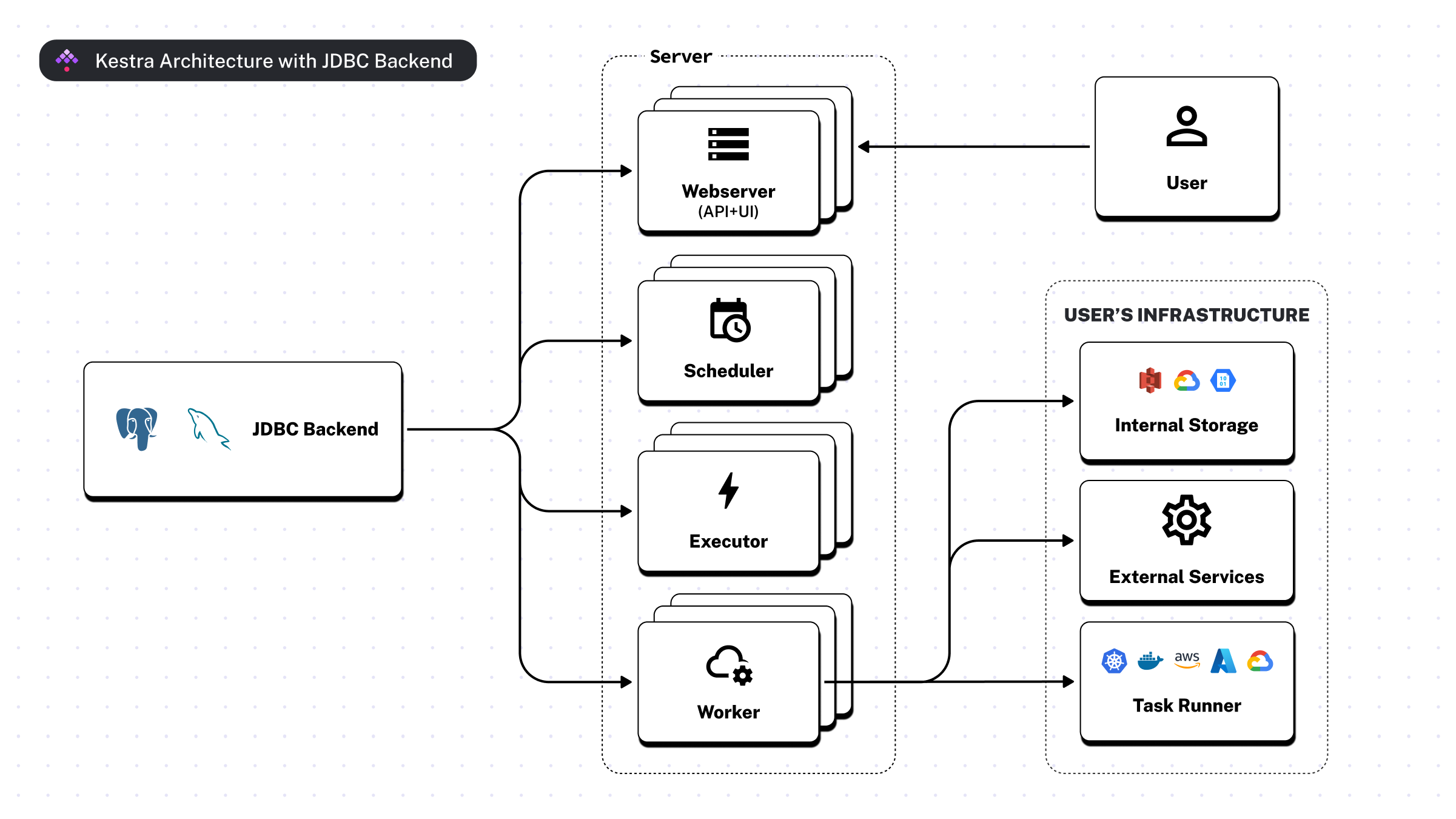
Here are the components and their interactions:
- JDBC Backend: the data storage layer used for orchestration metadata
- Server: the central part of the system, composed of:
- Webserver: serves both the API and the User Interface
- Scheduler: schedules workflows and handles all triggers except for the flow triggers (see below)
- Executor: responsible for the orchestration logic including flow triggers
- Worker: one or multiple processes that carry out the heavy computation of runnable tasks and Polling Triggers. For privacy reasons, workers are the only components that interact with the user's infrastructure, including the Internal Storage and external services.
- User: interacts with the system via UI and API
- User's Infrastructure: private infrastructure components that are part of the user's environment, which Kestra interacts with:
- Internal Storage: object storage system within the user's infrastructure (e.g. AWS S3, Google Cloud Storage, or Azure Blob Storage)
- External Services: third-party APIs or services outside of Kestra which Workers might interact with to process data within a given task
The arrows indicate the direction of communication. The JDBC Backend connects to the Server, which in turn interacts with the User's Infrastructure. The User interacts with the system through the API and UI.
For either database backend, the respective PostgreSQL JDBC Driver can provide an encrypted connection with some configuration.
Scalability with JDBC
The scalable design of the architecture allows you to run multiple instances of the Webserver, Executor, Worker, and Scheduler to handle increased load. As your workload increases, more instances of the required components can be added to the system to distribute the load and maintain performance.
The JDBC Backend can be scaled too, either through clustering or sharding, to handle larger volumes of data and a higher number of requests from the Server components. Most cloud providers offer managed database services that can be scaled up and down as needed.
Architecture with Kafka and Elasticsearch backend
The following diagram shows the main components of Kestra using the Kafka and Elasticsearch backend.
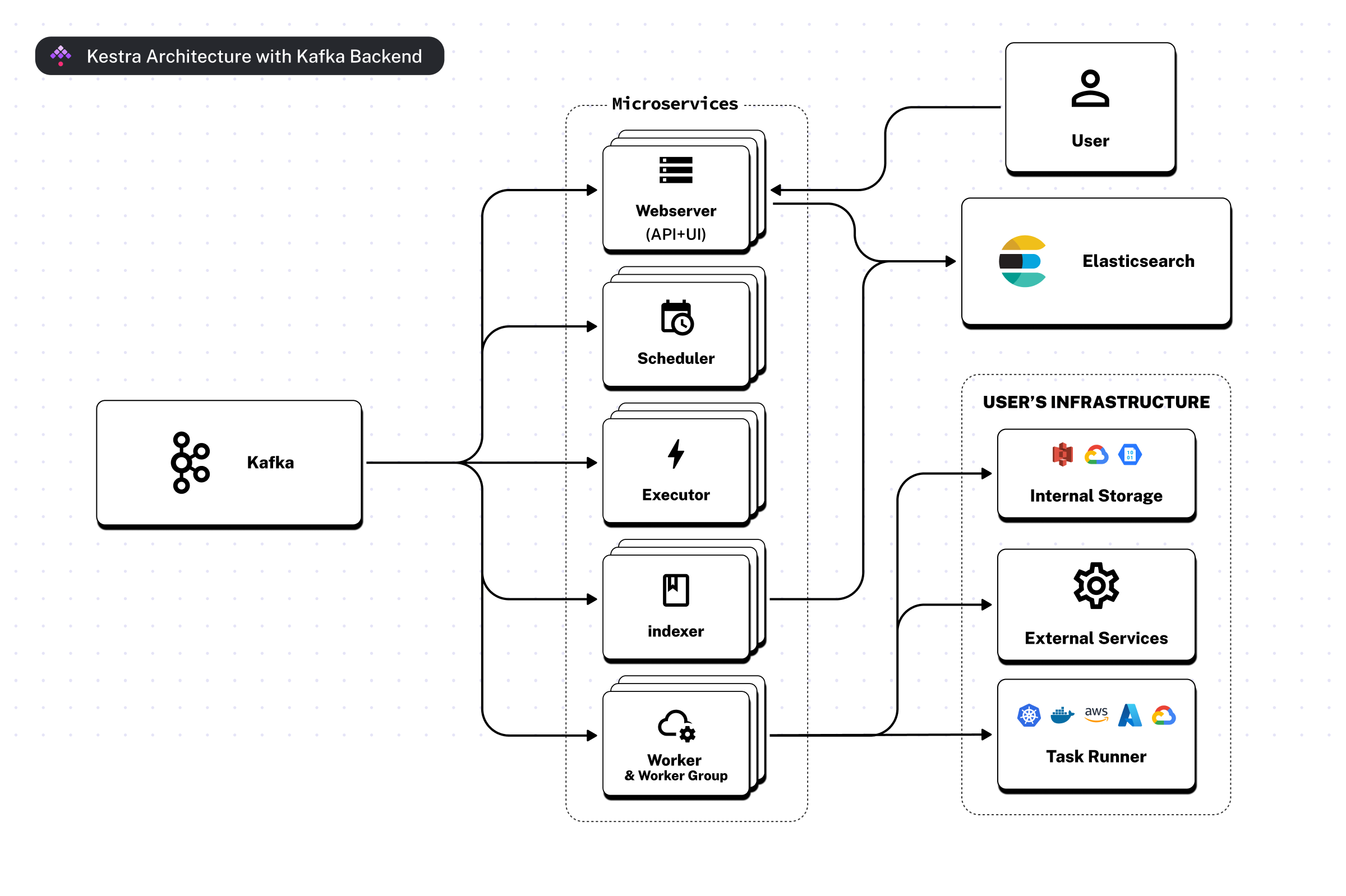
Note that this architecture is only available in the Enterprise Edition of Kestra.
This architecture is designed to provide the enhanced scalability, high availability, and fault tolerance required to meet the needs of large-scale enterprise deployments.
- Kafka: serves as the messaging backend, which communicates between different components of the system and allows for robust scalability and fault tolerance
- Microservices: This layer includes several services:
- Webserver: serves the API and the User Interface for interaction with the system
- Scheduler: schedules workflows and processes all triggers except for the flow triggers
- Executor: handles the orchestration logic, including flow triggers
- Indexer: indexes data from Kafka to Elasticsearch for quick retrieval and search (optional component since Kestra v0.20)
- Worker: runs runnable tasks and interacts with the user's infrastructure
- User: engages with the system through the Webserver's UI and API
- Elasticsearch: acts as a search and UI backend, storing logs, execution history, and enabling fast data retrieval
- User's Infrastructure: private infrastructure components that are part of the user's environment, which Kestra interacts with:
- Internal Storage: object storage system where user's data is stored (e.g. AWS S3, Google Cloud Storage, or Azure Blob Storage)
- External Services: APIs or services that Workers might interact with during task processing
Scalability with Kafka and Elasticsearch
Kafka's messaging backend allows handling large volumes of data with the ability to scale out as needed. You can run multiple (horizontally scaled) instances of services such as Workers, Schedulers, Webservers and Executors to ensure fault tolerance, distribute the load and maintain system performance as demand increases.
Elasticsearch contributes to scalability by providing a robust, horizontally scalable UI backend that can efficiently search across large amounts of data.
Comparison between JDBC and Kafka architectures
When comparing both diagrams, the main difference between the JDBC and an Kafka architectures is the data layer (JDBC Database vs. Kafka and Elasticsearch).
Note that it's possible to use the Enterprise Edition with a JDBC database backend for smaller deployments. In fact, it's often easier to start with a JDBC backend and migrate to Kafka and Elasticsearch when your deployment grows.
The Worker is the only component communicating with your private data sources to extract and transform data. The Worker also interacts with Internal Storage to persist intermediary results and store the final task run outputs.
All components of the application layer (including the Worker, Executor, and Scheduler) are decoupled and stateless, communicating with each other through the Queue (Kafka/JDBC). You can deploy and scale them independently.
The Webserver communicates with the (Elasticsearch/JDBC) Repository to serve data for Kestra UI and API.
The data layer is decoupled from the application layer and provides a separation between:
- storing your private data processing artifacts — Internal Storage is used to store outputs of your executions; you can think of Internal Storage as your own private AWS S3 bucket
- storing execution metadata — (Kafka/JDBC) Queue is used as the orchestration backend
- storing logs and user-facing data — the (Elasticsearch/JDBC) Repository is used to store data needed to serve Kestra UI and API.
The Indexer, available only in the Enterprise Edition, indexes content from Kafka topics (such as the flows and executions topics) to the Elasticsearch repositories. Thanks to the separation between Queue and Repository in the Kafka Architecture, even if your Elasticsearch instance experiences downtime, your executions will continue to work by relying on the Kafka backend.
Components in detail
The following sections provide more details about the components of the architecture.
Main components
Technical description of Kestra's main components, including the internal storage, queue, repository, and plugins.
Server components
Detailed breakdown of the server components behind Kestra.
Deployment Architecture
Examples of deployment architectures, depending on your needs.
Executor
The Executor processes all executions and Flowable Tasks.
Worker
The Worker is a server component that processes all runnable tasks and Polling Triggers.
Scheduler
The Scheduler is a server component responsible for processing all triggers except for the Flow Triggers (managed by the Executor).
Indexer
Indexer is a required component when using Kafka and Elasticsearch to achieve low latency. By default, it is merged inside the Web Server, but you can run the Web Server independently by using the server webserver --no-indexer CLI command.
Webserver
The Webserver serves the APIs and the User Interface (UI).
Internal Storage
Internal Storage is a dedicated storage area to store arbitrary-sized files used during executions.
Multi-tenancy
Multi-tenancy allows you to manage multiple environments (e.g., dev, staging, prod) in a single Kestra instance.
Data Storage in Kestra
Understand where different data components (inputs, outputs, logs, etc.) are stored in Kestra's architecture.
Was this page helpful?