 Expressions
Expressions
Expressions & Context Variables
Overview
Kestra's expressions combine the Pebble templating engine with the execution context to dynamically render flow properties. This page lists available expressions and explains how to use them in your flows.
Using Expressions
To dynamically set values in your flows, wrap an expression in curly braces, e.g. {{ your_expression }}.
Flows, tasks, executions, triggers, and schedules come with built-in expressions. For example:
{{ flow.id }}gives the flow's identifier within an execution{{ inputs.myinput }}retrieves an input value passed to the execution{{ outputs.mytask.myoutput }}fetches a task's output.
To debug expressions, use the Debug Outputs console as demonstrated in the video below:
Flow and Execution Expressions
Flow and execution expressions let you use the execution context to set task properties. For example, you can reference {{ execution.startDate }} to include the execution's start date in a file name.
Some expressions, such as flow.id or flow.namespace, access metadata stored in the execution context. Others, such as FILE-type inputs and outputs, pull data from Kestra's internal storage or environment variables.
The execution context includes these variables:
flowexecutioninputsoutputslabelstaskstrigger— available if at least one trigger is defined in the flowvars— available if variables are defined in the flow configurationnamespace— available in EE when Variables are set in the Namespace configurationenvs— environment variablesglobals— global variables.
To see all metadata available in the execution context, use {{ printContext() }} in the Debug Outputs console.
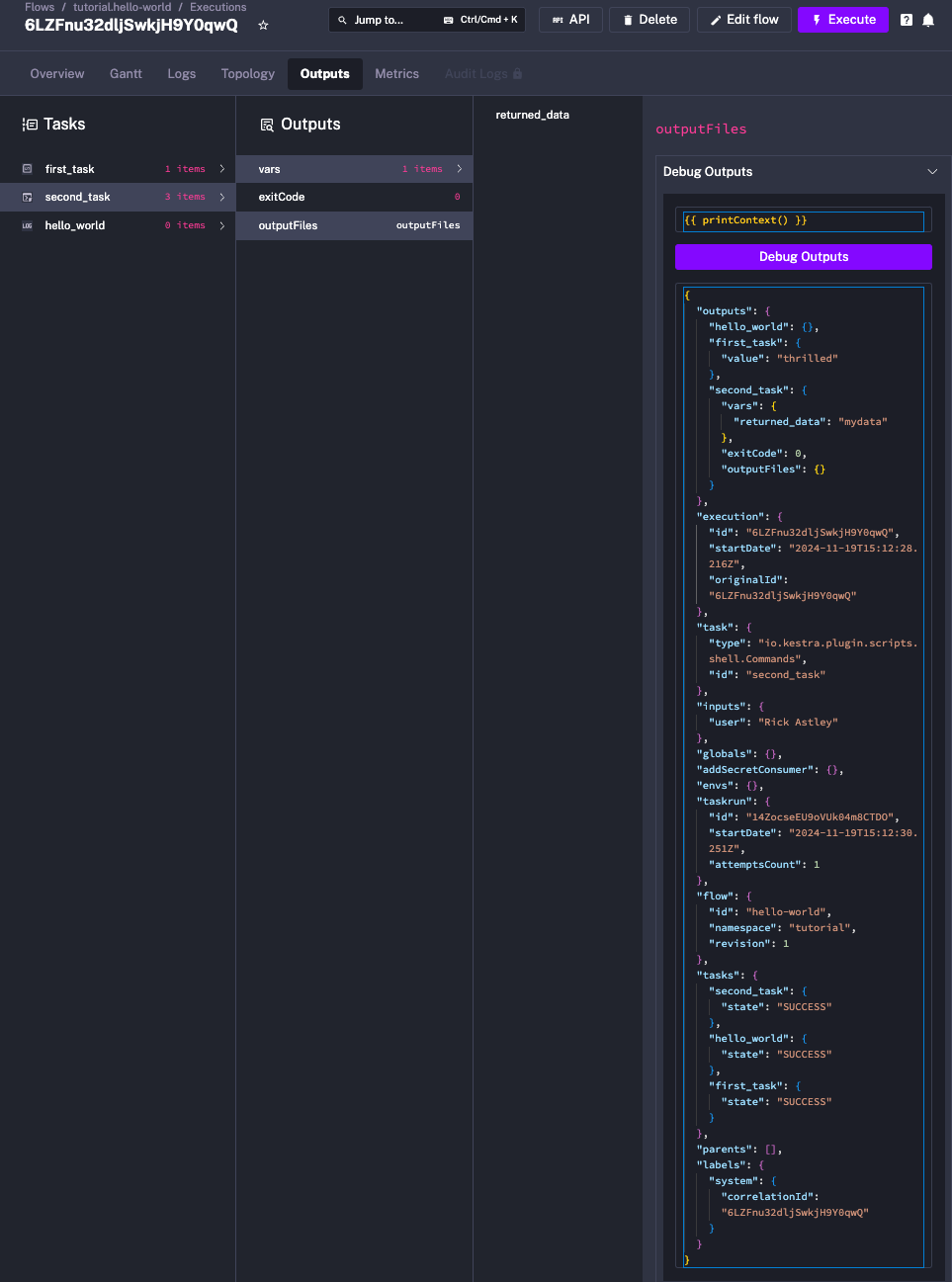
Default Execution Context Variables
The following table lists the default execution context variables available in Kestra:
| Parameter | Description |
|---|---|
{{ flow.id }} | Identifier of the flow. |
{{ flow.namespace }} | Namespace of the flow. |
{{ flow.tenantId }} | Identifier of the tenant (Enterprise Edition only). |
{{ flow.revision }} | Revision number of the flow. |
{{ execution.id }} | Unique ID of the execution. |
{{ execution.startDate }} | Start date of the execution, which can be formatted using {{ execution.startDate | date("yyyy-MM-dd HH:mm:ss.SSSSSS") }}. |
{{ execution.state }} | The state of the current execution. |
{{ execution.originalId }} | Original execution ID, remains the same even during replay, retaining the first execution ID. |
{{ task.id }} | ID of the current task. |
{{ task.type }} | Type of the current task (Java fully qualified class name). |
{{ taskrun.id }} | ID of the current task run. |
{{ taskrun.startDate }} | Start date of the current task run. |
{{ taskrun.attemptsCount }} | Number of attempts for the current task (includes retries or restarts). |
{{ taskrun.parentId }} | Parent ID of the current task run. Available only for tasks nested under a Flowable task. |
{{ taskrun.value }} | Value of the current task run. Available only for tasks wrapped in Flowable tasks. |
{{ parent.taskrun.value }} | Value of the nearest parent task run. Available only for tasks nested under a Flowable task. |
{{ parent.outputs }} | Outputs of the nearest parent task run. Available only for tasks nested under a Flowable task. |
{{ parents }} | List of parent tasks. Available only for tasks nested under a Flowable task. |
{{ labels }} | Execution labels accessible by keys, e.g. {{ labels.myKey }}. |
Additional Variables for Schedule Trigger
When the execution is triggered by a Schedule, the following variables are also available:
| Parameter | Description |
|---|---|
{{ trigger.date }} | Date of the current schedule. |
{{ trigger.next }} | Date of the next schedule. |
{{ trigger.previous }} | Date of the previous schedule. |
Additional Variables for Flow Trigger
When the execution is triggered by a Flow, the following variables are also available:
| Parameter | Description |
|---|---|
{{ trigger.executionId }} | ID of the execution triggering the current flow. |
{{ trigger.namespace }} | Namespace of the flow triggering the current flow. |
{{ trigger.flowId }} | ID of the flow triggering the current flow. |
{{ trigger.flowRevision }} | Revision of the flow triggering the current flow. |
All expressions can be used with the Pebble template syntax {{ expression }}. For example:
id: expressions
namespace: company.team
tasks:
- id: debug_expressions
type: io.kestra.plugin.core.debug.Return
format: |
taskId: {{ task.id }}
date: {{ execution.startDate | date("yyyy-MM-dd HH:mm:ss.SSSSSS") }}
Use the date filter to format the execution.startDate variable as yyyy-MM-dd HH:mm:ss.SSSSSS, e.g., {{ execution.startDate | date("yyyy-MM-dd HH:mm:ss.SSSSSS") }}.
Environment Variables
Kestra provides access to environment variables prefixed with KESTRA_ by default, unless configured otherwise in the variables configuration.
To use an environment variable, such as KESTRA_FOO, reference it as {{ envs.foo }}. The variable name is derived by removing the KESTRA_ prefix and converting the remainder to lowercase.
To reference the environment name defined in Kestra configuration, you can use {{kestra.environment.name}}. Similarly, using {{kestra.url}}, you can reference the environment's URL set in your Kestra configuration.
Global Variables
You can define global variables in Kestra's configuration and access them using {{ globals.foo }}.
Flow Variables
To avoid hardcoding values in tasks, you can declare variables at the flow level using the variables property. These variables can be accessed anywhere in the flow with the vars.my_variable syntax. For example:
id: flow_variables
namespace: company.team
variables:
my_variable: "my_value"
tasks:
- id: print_variable
type: io.kestra.plugin.core.debug.Return
format: "{{ vars.my_variable }}"
Inputs
Flow inputs can be referenced using the inputs.inputName syntax. For example:
id: render_inputs
namespace: company.team
inputs:
- id: myInput
type: STRING
tasks:
- id: myTask
type: io.kestra.plugin.core.debug.Return
format: "{{ inputs.myInput }}"
Secrets
You can retrieve secrets in your flow using the secret() function. Secrets are stored in a secure way and can be accessed as follows:
id: use_secret_in_flow
namespace: company.team
tasks:
- id: myTask
type: io.kestra.plugin.core.debug.Return
format: "{{ secret('MY_SECRET') }}"
Secrets are supported in both the open-source version and Enterprise Edition. For additional details, refer to the Secrets documentation.
Namespace Variables (EE)
Namespace variables are key-value pairs defined in YAML configuration. They can be nested and referenced in flows using dot notation, e.g., {{ namespace.myproject.myvariable }}. To define namespace variables:
- Navigate to
Namespacesin the Kestra UI. - Select the namespace.
- Add variables in the
Variablestab.
Namespace variables are scoped to the specific namespace and inherited by child namespaces. Reference these variables in your flow using the namespace.your_variable syntax. Example:
id: namespace_variables
namespace: company.team
tasks:
- id: myTask
type: io.kestra.plugin.core.debug.Return
format: "{{ namespace.your_variable }}"
If a namespace variable contains Pebble expressions, such as {{ secret('GITHUB_TOKEN') }}, you need to use the render function to evaluate it. For example, assume the following variable is defined in the Variables tab:
github:
token: "{{ secret('GITHUB_TOKEN') }}"
To reference github.token in your flow, use "{{ render(namespace.github.token) }}":
id: recursive_namespace_variables_rendering
namespace: company.team
tasks:
- id: myTask
type: io.kestra.plugin.core.debug.Return
format: "{{ render(namespace.github.token) }}"
The render() function is required to parse namespace or flow variables containing Pebble expressions. Without it, the variable is treated as a string, and its expressions are not evaluated.
Outputs
Task outputs can be accessed using {{ outputs.taskId.outputAttribute }}, where:
taskIdis the ID of the taskoutputAttributeis the attribute of the task's output. Each task emits specific output attributes — refer to task documentation for details.
Example of passing data between tasks using outputs:
id: pass_data_between_tasks
namespace: company.team
tasks:
- id: first
type: io.kestra.plugin.core.debug.Return
format: First output value
- id: second-task
type: io.kestra.plugin.core.debug.Return
format: Second output value
- id: print_both_outputs
type: io.kestra.plugin.core.log.Log
message: |
First: {{ outputs.first.value }}
Second: {{ outputs['second-task'].value }}
The Return-type task emits an output attribute called value. The print_both_outputs task demonstrates two ways to access outputs:
- Dot notation:
{{ outputs.first.value }} - Subscript notation:
{{ outputs['second-task'].value }}— required for task IDs with special characters (e.g., hyphens). We recommend usingcamelCaseorsnake_casefor task IDs to avoid this issue.
Pebble Templating
Pebble templating provides many ways to dynamically evaluate expressions.
The example below demonstrates parsing Pebble expressions within variables, based on inputs and trigger values. The Null-Coalescing Operator ?? is used to select the first non-null value.
Parsing Complex Variables
The workflow shown below defines two variables:
trigger_or_yesterday:- Evaluates to
trigger.dateif the flow runs on a schedule. - If no schedule is available, it defaults to yesterday’s date by subtracting one day from
execution.startDate.
- Evaluates to
input_or_yesterday:- Evaluates to the
mydateinput if provided. - If the input is absent, it defaults to yesterday’s date, calculated using
execution.startDateminus one day with thedateAddfunction.
- Evaluates to the
id: render_complex_expressions
namespace: company.team
inputs:
- id: mydate
type: DATETIME
required: false
variables:
trigger_or_yesterday: "{{ trigger.date ?? (execution.startDate | dateAdd(-1, 'DAYS')) }}"
input_or_yesterday: "{{ inputs.mydate ?? (execution.startDate | dateAdd(-1, 'DAYS')) }}"
tasks:
- id: yesterday
type: io.kestra.plugin.core.log.Log
message: "{{ render(vars.trigger_or_yesterday) }}"
- id: input_or_yesterday
type: io.kestra.plugin.core.log.Log
message: "{{ render(vars.input_or_yesterday) }}"
Render Function and Null-Coalescing
renderFunction: therenderfunction is required to evaluate variables containing Pebble expressions. Without it, variables will be treated as strings, and expressions inside them will not be evaluated.- Null-Coalescing Operator (
??): this operator ensures that the first non-null value is selected, providing a fallback mechanism.
Combining the render() function with the Null-Coalescing operator enables dynamic and flexible parsing of complex expressions.
Expression Usage
This section summarizes the main syntax of filters, functions, and control structures available in Pebble templating.
Syntax Reference
Pebble templates use two primary delimiters:
{{ ... }}: outputs the result of an expression. Expressions can be simple variables or complex calculations.{% ... %}: controls the template’s flow, such as withifstatements orforloops.
To escape expressions or control structures, use the raw tag. This prevents Pebble from interpreting content within {{ ... }} or {% ... %}.
Dot notation (.) is used to access nested attributes. For attributes with special characters, use square brackets:
{{ foo.bar }} # Accesses 'bar' in 'foo'
{{ foo['foo-bar'] }} # Accesses 'foo-bar' in 'foo'
For names with hyphens (-), use subscript notation: {{ outputs.mytask.myoutput['foo-bar'] }}. To avoid this, use camelCase or snake_case for names.
For lists, access elements by index with square brackets ([]):
{{ foo[0] }} # Accesses the first element in the list 'foo'
Filters
Filters transform values and are applied using the pipe (|) symbol. Filters can be chained:
{{ "Lemons to lemonade." | upper | abbreviate(10) }}
# Output: LEMONS TO ...
Functions
Functions generate new values. They are called with a name followed by parentheses:
{{ max(user.score, highscore) }}
# Outputs the maximum of 'user.score' and 'highscore'
Control Structures
Pebble supports loops and conditionals to control the flow of templates.
For Loop:
{% for article in articles %}
{{ article.title }}
{% else %}
"No articles available."
{% endfor %}
If Statement:
{% if category == "news" %}
{{ news }}
{% elseif category == "sports" %}
{{ sports }}
{% else %}
"Select a category"
{% endif %}
Macros
Macros are reusable template snippets, similar to functions:
{% macro input(type, name) %}
{{ name }} is of type {{ type }}
{% endmacro %}
Usage:
{{ input("text", "example") }}
# Output: example is of type text
Macros only access their local arguments.
Named Arguments
Filters, functions, and macros support named arguments for clarity:
{{ stringDate | date(existingFormat="yyyy-MMMM-d", format="yyyy/MMMM/d") }}
Named arguments can define defaults in macros:
{% macro input(type="text", name, value="") %}
type: "{{ type }}", name: "{{ name }}", value: "{{ value }}"
{% endmacro %}
{{ input(name="country") }}
# Output: type: "text", name: "country", value: ""
Comments
Add comments using {# ... #}. They do not appear in output:
{# This is a comment #}
{{ "Visible content" }}
In YAML, use # for comments.
Literals
Pebble supports literals for strings, numbers, booleans, and null values:
"Hello World": Strings use single or double quotes.100 + 10l * 2.5: Numbers include integers, longs, and floats.true,false: Boolean values.null: Represents no value.
Collections
Create lists and maps directly:
["apple", "banana"]: a list of strings.{"apple":"red", "banana":"yellow"}: a map of key-value pairs.
Math
Basic mathematical operators are supported:
+: Addition-: Subtraction*: Multiplication/: Division%: Modulus
Logical Operators
Combine expressions using:
and: True if both are true.or: True if either is true.not: Negates an expression.
Comparisons
Pebble supports common comparison operators:
==, !=, <, >, <=, >=.
Tests
Use the is operator to test expressions:
{% if 3 is odd %}
"Odd number"
{% endif %}
Negate tests with is not:
{% if name is not null %}
"Name exists"
{% endif %}
Conditional (Ternary) Operator
The conditional operator (?) works like Java's ternary operator:
{{ foo ? "yes" : "no" }}
Null-Coalescing Operator
The ?? operator provides a fallback if a variable is null:
{{ foo ?? bar ?? "default" }}
Raises an exception if no variable is defined:
{{ foo ?? bar ?? raise }}
Operator Precedence
Operators are evaluated in the following order:
.|%,/,*-,+==,!=,>,<,>=,<=is,is notandor
Basic Filters
Filters transform variables in expressions, allowing for operations like formatting, string manipulation, and list processing. Filters are applied using the pipe symbol (|) and can be chained together.
To apply a filter, use this syntax:
{{ name | title }}
This example converts name to title case.
Filters that accept arguments use parentheses. For example, to join a list of strings with commas:
{{ list | join(', ') }}
To apply a filter to a block of text, wrap it with the filter tag:
{% filter lower | title %}
hello world
{% endfilter %}
JSON Filters
JSON filters are specifically designed to manipulate JSON objects, such as API responses.
toJson
The toJson filter converts any object into a JSON string. Examples:
{{ [1, 2, 3] | toJson }} # Outputs: '[1, 2, 3]'
{{ true | toJson }} # Outputs: 'true'
{{ "foo" | toJson }} # Outputs: '"foo"'
In versions prior to v0.18.0, this filter was named json. Using json will still work but raises a warning in the UI.
toIon
The toIon filter converts any object into an Ion string. Example:
{{ myObject | toIon }}
jq
The jq filter applies a JQ expression to a variable. The result is always an array formatted as JSON. Use the first filter to extract the first (or only) result.
Examples:
{{ [1, 2, 3] | jq('.') }}
# Outputs: '[1, 2, 3]'
{{ [1, 2, 3] | jq('.[0]') | first }}
# Outputs: '1'
Given the context:
{
"outputs": {
"task1": {
"value": 1,
"text": "awesome1"
},
"task2": {
"value": 2,
"text": "awesome2"
}
}
}
The following expression extracts the value of task1:
{{ outputs | jq('.task1.value') | first }}
# Outputs: '1'
Arguments
expression: The JQ expression to apply.
Manipulating JSON Payloads
Here is a comprehensive example of JSON manipulation. This flow takes a JSON payload as input and performs multiple transformations:
id: myflow
namespace: company.myteam
inputs:
- id: payload
type: JSON
defaults: |-
{
"name": "John Doe",
"score": {
"English": 72,
"Maths": 88,
"French": 95,
"Spanish": 85,
"Science": 91
},
"address": {
"city": "Paris",
"country": "France"
},
"graduation_years": [2020, 2021, 2022, 2023]
}
tasks:
- id: print_status
type: io.kestra.plugin.core.log.Log
message:
- "Student name: {{ inputs.payload.name }}" # Extracting a value
- "Score in languages: {{ inputs.payload.score.English + inputs.payload.score.French + inputs.payload.score.Spanish }}" # Summing numbers
- "Total subjects: {{ inputs.payload.score | length }}" # Counting keys in a map
- "Total score: {{ inputs.payload.score | values | jq('reduce .[] as $num (0; .+$num)') | first }}" # Summing all values
- "Complete address: {{ inputs.payload.address.city }}, {{ inputs.payload.address.country | upper }}" # Concatenation and transformation
- "Total years for graduation: {{ inputs.payload.graduation_years | length }}" # Counting array elements
- "Started college in: {{ inputs.payload.graduation_years | first }}" # First element in an array
- "Completed college in: {{ inputs.payload.graduation_years | last }}" # Last element in an array
Running this flow will log:
Student name: John Doe
Score in languages: 252
Total subjects: 5
Total score: 431
Complete address: Paris, FRANCE
Total years for graduation: 4
Started college in: 2020
Completed college in: 2023
Numeric Filters
Numeric filters are used to format numbers or convert strings to numbers.
abs
The abs filter returns the absolute value of a number.
{{ -7 | abs }}
# output: 7
number
The number filter parses a string into a number. If no type is specified, the type is inferred.
{{ "12.3" | number | className }}
# output: java.lang.Float
{{ "9223372036854775807" | number('BIGDECIMAL') | className }}
# output: java.math.BigDecimal
- type:
INTFLOATLONGDOUBLEBIGDECIMALBIGINTEGER
numberFormat
The numberFormat filter formats a number using java.text.DecimalFormat.
{{ 3.141592653 | numberFormat("#.##") }}
# output: 3.14
Object Filters
Object filters manipulate collections such as maps, arrays, or strings.
chunk
The chunk filter partitions a list into chunks of the specified size.
{{ [1, 2, 3, 4, 5] | chunk(2) }}
# results in: [[1, 2], [3, 4], [5]]
className
The className filter returns the class name of an object.
{{ "12.3" | number | className }}
# output: java.lang.Float
distinct
The distinct filter deduplicates a list and returns only the unique values.
"{{ ['1', '1', '2', '3'] | distinct }}"
# results in ["1","2","3"]
first
The first filter retrieves the first item of a collection or the first character of a string.
{{ ['apple', 'banana'] | first }}
# output: apple
{{ 'Mitch' | first }}
# output: M
join
The join filter concatenates the items in a collection into a single string, separated by a specified delimiter.
{{ ['apple', 'banana'] | join(', ') }}
# output: apple, banana
keys
The keys filter retrieves the keys from a map or the indices of an array.
{{ {'foo': 'bar', 'baz': 'qux'} | keys }}
# output: ['foo', 'baz']
values
The values filter retrieves the values from a map.
{{ {'foo': 'bar', 'baz': 'qux'} | values }}
# output: ['bar', 'qux']
last
The last filter retrieves the last item of a collection or the last character of a string.
{{ ['apple', 'banana'] | last }}
# output: banana
{{ 'Mitch' | last }}
# output: h
length
The length filter returns the size of a collection or the length of a string.
{{ 'Mitch' | length }}
# output: 5
merge
The merge filter combines two collections (lists or maps).
{{ [1, 2] | merge([3, 4]) }}
# output: [1, 2, 3, 4]
reverse
The reverse filter reverses the order of items in a collection.
{{ ['apple', 'banana'] | reverse }}
# output: ['banana', 'apple']
rsort
The rsort filter sorts a list in reverse order.
{{ [3, 1, 2] | rsort }}
# output: [3, 2, 1]
slice
The slice filter extracts a portion of a collection or string.
{{ ['apple', 'banana', 'cherry'] | slice(1, 2) }}
# output: ['banana']
{{ 'Mitch' | slice(1, 3) }}
# output: it
Arguments:
fromIndex: starting index (inclusive).toIndex: ending index (exclusive).
sort
The sort filter sorts a collection in ascending order.
{{ [3, 1, 2] | sort }}
# output: [1, 2, 3]
split
The split filter divides a string into a list based on a delimiter.
{{ 'apple,banana,cherry' | split(',') }}
# output: ['apple', 'banana', 'cherry']
Arguments:
delimiter: the string to split on.limit: limits the number of splits:- Positive: limits the array size, with the last entry containing the remaining content.
- Zero or negative: no limit on splits.
{{ 'apple,banana,cherry,grape' | split(',', 2) }}
# output: ['apple', 'banana,cherry,grape']
String Filters
String filters manipulate textual data, enabling operations like transformation, encoding, or formatting.
abbreviate
The abbreviate filter shortens a string using an ellipsis. The length includes the ellipsis.
{{ "this is a long sentence." | abbreviate(7) }}
# output: this...
Arguments:
- length: the maximum length of the output.
base64decode
The base64decode filter decodes a base64-encoded string into UTF-8.
{{ "dGVzdA==" | base64decode }}
# output: test
Throws an exception for invalid base64 strings.
base64encode
The base64encode filter encodes a string to base64.
{{ "test" | base64encode }}
# output: dGVzdA==
capitalize
The capitalize filter capitalizes the first letter of a string.
{{ "article title" | capitalize }}
# output: Article title
title
The title filter capitalizes the first letter of each word.
{{ "article title" | title }}
# output: Article Title
default
The default filter provides a fallback value for empty variables.
{{ user.phoneNumber | default("No phone number") }}
# output: No phone number (if user.phoneNumber is empty)
Suppresses exceptions if the attribute is missing.
escapeChar
The escapeChar filter escapes special characters in a string.
{{ "Can't be here" | escapeChar('single') }}
# output: Can\'t be here
Arguments:
type: escape type (single,double, orshell).
lower
The lower filter converts a string to lowercase.
{{ "LOUD TEXT" | lower }}
# output: loud text
replace
The replace filter replaces substrings in a string with specified values.
{{ "I like %this% and %that%." | replace({'%this%': foo, '%that%': "bar"}) }}
# output: I like foo and bar
Arguments:
replace_pairs: a map of search-replace pairs.regexp: enables regex-based replacements.
sha256
The sha256 filter generates a SHA-256 hash of a string.
{{ "test" | sha256 }}
# output: 9f86d081884c7d659a2feaa0c55ad015a3bf4f1b2b0b822cd15d6c15b0f00a08
startsWith
The startsWith filter checks if a string starts with a given prefix.
{{ "hello world" | startsWith("hello") }}
# output: true
slugify
The slugify filter converts a string to a URL-friendly format.
{{ "Hello World!" | slugify }}
# output: hello-world
substringAfter
The substringAfter filter extracts the substring after the first occurrence of a separator.
{{ "a.b.c" | substringAfter(".") }}
# output: b.c
substringAfterLast
The substringAfterLast filter extracts the substring after the last occurrence of a separator.
{{ "a.b.c" | substringAfterLast(".") }}
# output: c
substringBefore
The substringBefore filter extracts the substring before the first occurrence of a separator.
{{ "a.b.c" | substringBefore(".") }}
# output: a
substringBeforeLast
The substringBeforeLast filter extracts the substring before the last occurrence of a separator.
{{ "a.b.c" | substringBeforeLast(".") }}
# output: a.b
trim
The trim filter removes whitespace from the start and end of a string.
{{ " padded text " | trim }}
# output: padded text
upper
The upper filter converts a string to uppercase.
{{ "quiet sentence" | upper }}
# output: QUIET SENTENCE
urldecode
The urldecode filter decodes a URL-encoded string.
{{ "The+string+%C3%BC%40foo-bar" | urldecode }}
# output: The string ü@foo-bar
urlencode
The urlencode filter encodes a string for URLs.
{{ "The string ü@foo-bar" | urlencode }}
# output: The+string+%C3%BC%40foo-bar
string
The string filter casts an object to string.
{{ 123 | string }}
# output: "123"
Temporal Filters
Temporal filters are used for formatting, manipulating, and converting dates and timestamps.
date
The date filter formats a date object or string into a specified format. It supports java.util.Date, java.time constructs like OffsetDateTime, and epoch timestamps in milliseconds.
{{ user.birthday | date("yyyy-MM-dd") }}
# output: 2001-07-24
To format a string-based date, provide the desired output format and the existing format of the string:
{{ "July 24, 2001" | date("yyyy-MM-dd", existingFormat="MMMM dd, yyyy") }}
# output: 2001-07-24
Time Zones
Specify a custom time zone using the timeZone argument:
{{ now() | date("yyyy-MM-dd'T'HH:mm:ssX", timeZone="UTC") }}
Arguments:
format: the desired output format.existingFormat: the input format (if parsing a string).timeZone: the time zone for formatting.locale: the locale for formatting.
Supported Date Formats
- Standard Java formats: DateTimeFormatter
- Presets:
iso,sql,iso_date_time,iso_zoned_date_time, etc.
dateAdd
The dateAdd filter adds or subtracts a specified amount of time to/from a date.
{{ now() | dateAdd(-1, 'DAYS') }}
# output: 2024-07-08T06:17:01.174686Z
Arguments:
amount: an integer specifying the time to add/subtract.unit: the time unit (e.g.,DAYS,HOURS,YEARS).- Additional arguments: same as the
datefilter.
timestamp
The timestamp filter converts a date to a Unix timestamp in seconds.
{{ now() | timestamp(timeZone="Europe/Paris") }}
# output: 1720505821
Arguments:
existingFormat: the input format (if parsing a string).timeZone: the time zone for conversion.
timestampMicro
The timestampMicro filter converts a date to a Unix timestamp in microseconds.
{{ now() | timestampMicro(timeZone="Asia/Kolkata") }}
# output: 1720505821000180275
Arguments:
- Same as
timestamp.
timestampNano
The timestampNano filter converts a date to a Unix timestamp in nanoseconds.
{{ now() | timestampNano(timeZone="Asia/Kolkata") }}
# output: 1720505821182413000
Arguments:
- Same as
timestamp.
Example with Temporal Filters
Here’s an example flow showcasing the use of temporal filters:
id: temporal-dates
namespace: company.myteam
tasks:
- id: print_status
type: io.kestra.plugin.core.log.Log
message:
- "Present timestamp: {{ now() }}"
- "Formatted timestamp: {{ now() | date('yyyy-MM-dd') }}"
- "Previous day: {{ now() | dateAdd(-1, 'DAYS') }}"
- "Next day: {{ now() | dateAdd(1, 'DAYS') }}"
- "Timezone (seconds): {{ now() | timestamp(timeZone='Asia/Kolkata') }}"
- "Timezone (microseconds): {{ now() | timestampMicro(timeZone='Asia/Kolkata') }}"
- "Timezone (nanoseconds): {{ now() | timestampNano(timeZone='Asia/Kolkata') }}"
Running this flow will log the following:
Present timestamp: 2024-07-09T06:17:01.171193Z
Formatted timestamp: 2024-07-09
Previous day: 2024-07-08T06:17:01.174686Z
Next day: 2024-07-10T06:17:01.176138Z
Timezone (seconds): 1720505821
Timezone (microseconds): 1720505821000180275
Timezone (nanoseconds): 1720505821182413000
YAML Filters
YAML filters allow you to parse and manipulate YAML strings, converting them into objects that can be processed further.
yaml
The yaml filter, introduced in Kestra 0.16.0, parses a YAML string into an object. This is especially useful when working with templated tasks, such as the TemplatedTask.
Example:
{{ "foo: bar" | yaml }}
Example: Using the yaml filter in a templated task
id: yaml_filter_example
namespace: company.team
tasks:
- id: yaml_filter
type: io.kestra.plugin.core.log.Log
message: |
{{ "foo: bar" | yaml }}
{{ {"key": "value"} | yaml }}
indent
The indent filter adds indentation to strings, applying the specified number of spaces before each line (except the first).
Arguments:
amount: number of spaces to add.prefix: the string used for indentation (default is" ").
Example:
{{ "key: value" | indent(2) }}
# output:
key: value
nindent
The nindent filter adds a newline before the input and then indents all lines.
Arguments:
amount: number of spaces for indentation.prefix: the string used for indentation (default is" ").
Example:
{{ "key: value" | nindent(2) }}
# output:
key: value
Example with indent and nindent
id: templated_task_example
namespace: company.team
labels:
example: test
variables:
yaml_data: |
key1: value1
key2: value2
tasks:
- id: yaml_with_indent
type: io.kestra.plugin.core.templating.TemplatedTask
spec: |
id: example-task
type: io.kestra.plugin.core.log.Log
message: |
Metadata:
{{ labels | yaml | indent(4) }}
Variables:
{{ variables.yaml_data | yaml | nindent(4) }}
The above example generates a task with indented YAML content for both labels and variables.
Here is an explanation of the filters used:
- Using
yaml: converts the YAML string into an object. - Using
indent(4): adds four spaces before each line. - Using
nindent(4): adds a newline and then indents with four spaces.
Functions
Functions in Kestra allow you to dynamically generate or manipulate content. They are invoked by their name followed by parentheses () and can accept arguments.
errorLogs
The errorLogs() function retrieves a list of error logs from the failed task run. This is useful when sending alerts on failure. When using this function e.g. in a Slack alert message, you'll have a context about why the execution failed.
id: error_logs_demo
namespace: company.team
tasks:
- id: fail
type: io.kestra.plugin.core.execution.Fail
errorMessage: Something went wrong, make sure to fix it asap ⚠️
errors:
- id: alert
type: io.kestra.plugin.core.log.Log
message: list of error logs — {{ errorLogs() }}>
block
The block function renders the contents of a block multiple times. It is distinct from the block tag used to declare blocks.
Example:
{% block "post" %}content{% endblock %}
{{ block("post") }}
Output:
content
content
currentEachOutput
The currentEachOutput function simplifies retrieving outputs of sibling tasks within an EachSequential task.
Example:
tasks:
- id: each
type: io.kestra.plugin.core.flow.EachSequential
tasks:
- id: first
type: io.kestra.plugin.core.debug.Return
format: "{{task.id}}"
- id: second
type: io.kestra.plugin.core.debug.Return
format: "{{ currentEachOutput(outputs.first).value }}"
value: ["value 1", "value 2", "value 3"]
This eliminates the need for manual handling of taskrun.value or parents.
fromJson
The fromJson function parses a JSON string into an object, enabling property access.
Examples:
{{ fromJson('[1, 2, 3]')[0] }}
# output: 1
{{ fromJson('{"foo": [666, 1, 2]}').foo[0] }}
# output: 666
fromIon
The fromIon function parses a ION string into an object, enabling property access.
Example:
{{ fromIon(read(someItem)).someField }}
yaml
The yaml function parses a YAML string into an object.
Example:
{{ yaml('foo: [666, 1, 2]').foo[0] }}
# output: 666
max
The max function returns the largest of its arguments.
Example:
{{ max(20, 80, user.age) }}
# output: the largest value
min
The min function returns the smallest of its arguments.
Example:
{{ min(20, 80, user.age) }}
# output: the smallest value
now
The now function generates the current datetime. Formatting options are the same as the date filter.
Example:
{{ now() }}
{{ now(timeZone="Europe/Paris") }}
parent
The parent function renders the parent block's content within a child block.
Example:
Parent template (parent.peb):
{% block "content" %}parent content{% endblock %}
Child template (child.peb):
{% extends "parent.peb" %}
{% block "content" %}
child content
{{ parent() }}
{% endblock %}
Output:
child content
parent content
range
The range function generates a list of numbers.
Examples:
{% for i in range(0, 3) %}
{{ i }},
{% endfor %}
# output: 0, 1, 2, 3
{% for i in range(0, 6, 2) %}
{{ i }},
{% endfor %}
# output: 0, 2, 4, 6
printContext
The printContext function is used for debugging by printing all defined variables.
Example:
{{ printContext() }}
Output:
{"outputs": {...}, "execution": {...}, ...}
read
The read function retrieves the contents of a file from internal storage or namespace files.
Examples:
{{ read('subdir/file.txt') }}
{{ read(outputs.someTask.uri) }}
render
The render function enables recursive rendering of expressions. By default, Kestra only renders expressions once.
Example:
{{ render("{{ trigger.date ?? execution.startDate | date('yyyy-MM-dd') }}") }}
Arguments:
recursive: defaults totrue. Set tofalsefor one-time rendering.
renderOnce
Equivalent to render(expression, recursive=false). It simplifies rendering without recursion.
secret
The secret function retrieves secrets stored in Kestra's secret backend.
Example:
tasks:
- id: github_secret
type: io.kestra.plugin.core.log.Log
message: "{{ secret('GITHUB_ACCESS_TOKEN') }}"
randomInt
The randomInt function generates a random integer from a specified range.
Example with a range between 1 and 10:
tasks:
- id: random
type: io.kestra.plugin.core.log.Log
message: "{{ randomInt(1, 10) }}"
uuid
The uuid function generates a UUID in the Kestra format (i.e., a UUID encoded in Url62).
Example:
tasks:
- id: uuid
type: io.kestra.plugin.core.log.Log
message: "Generated UUID: {{ uuid() }}"
# Output: Generated UUID: d815cb05-ac71-429d-8e73-f7c92f5429c4
randomPort
The randomPort function generate a random available port.
Example:
tasks:
- id: port
type: io.kestra.plugin.core.log.Log
message: "Generated Port: {{ randomPort() }}"
fileSize
The fileSize function returns the size of the file present at the given URI.
Example:
tasks:
- id: download
type: io.kestra.plugin.core.http.Download
uri: https://huggingface.co/datasets/kestra/datasets/raw/main/csv/orders.csv
- id: fileSize
type: io.kestra.plugin.core.log.Log
message: "The file size is {{ fileSize(output.download.uri) }}"
fileExists
The fileExists function returns true if the file is present at the given URI.
tasks:
- id: download
type: io.kestra.plugin.core.http.Download
uri: https://huggingface.co/datasets/kestra/datasets/raw/main/csv/orders.csv
- id: fileExists
type: io.kestra.plugin.core.log.Log
message: "The file exists: {{ fileExists(output.download.uri) }}"
fileEmpty
The fileEmpty function returns true if the file present at the given URI is empty.
tasks:
- id: download
type: io.kestra.plugin.core.http.Download
uri: https://huggingface.co/datasets/kestra/datasets/raw/main/csv/orders.csv
- id: fileEmpty
type: io.kestra.plugin.core.log.Log
message: "Is the file empty? {{ fileEmpty(output.download.uri) }}"
Example with Functions
id: function_example
namespace: company.team
tasks:
- id: max_example
type: io.kestra.plugin.core.log.Log
message: "Maximum value: {{ max(5, 10, 15) }}"
- id: render_example
type: io.kestra.plugin.core.log.Log
message: "{{ render('{{ trigger.date ?? execution.startDate | date("yyyy-MM-dd") }}') }}"
- id: secret_example
type: io.kestra.plugin.core.log.Log
message: "{{ secret('API_KEY') }}"
allowFailure: true
Operators
Operators enable logical, arithmetic, and comparison operations within templated expressions. They are essential for dynamic content manipulation.
Comparison Operators
Supported comparison operators: ==, !=, <, >, <=, >=.
==: UsesJava.util.Objects.equals(a, b)for null-safe comparisons. Alias:equals.
Example:
{% if user.name equals "Mitchell" %}
...
{% endif %}
concat
The ~ operator concatenates two or more strings.
Example:
{{ "apple" ~ "pear" ~ "banana" }}
# results in: 'applepearbanana'
contains
The contains operator checks if an item exists within a collection, map, or array.
Examples:
{% if ["apple", "pear", "banana"] contains "apple" %}
...
{% endif %}
For maps, it checks for an existing key:
{% if {"apple":"red", "banana":"yellow"} contains "banana" %}
...
{% endif %}
To check multiple items:
{% if ["apple", "pear", "banana", "peach"] contains ["apple", "peach"] %}
...
{% endif %}
is
The is operator tests variables, returning a boolean.
Examples:
{% if 2 is even %}
...
{% endif %}
Negation with not:
{% if 3 is not even %}
...
{% endif %}
logic
Combine boolean expressions using and and or. Use not for negation.
Examples:
{% if 2 is even and 3 is odd %}
...
{% endif %}
{% if 3 is not even %}
...
{% endif %}
Group expressions with parentheses for precedence:
{% if (3 is not even) and (2 is odd or 3 is even) %}
...
{% endif %}
math
Perform arithmetic operations with standard math operators. Follow the order of operations.
Example:
{{ 2 + 2 / (10 % 3) * (8 - 1) }}
Supported operators:
+: Addition-: Subtraction/: Division (returns a float)%: Modulus*: Multiplication
not
Use not with is to negate a test.
Example:
{% if 3 is not even %}
...
{% endif %}
null-coalescing
The null-coalescing operator (??) returns the first defined, non-null value. Use ??? to return the right-hand side only if the left-hand side is undefined.
Examples:
{% set baz = "baz" %}
{{ foo ?? bar ?? baz }}
# results in: 'baz'
{{ foo ?? bar ?? raise }}
# raises an exception if all variables are undefined
For details, see the Handling null and undefined values guide.
ternary operator
The ternary operator (? :) evaluates conditions succinctly.
Example:
{{ foo == null ? bar : baz }}
Tag
Tags in Pebble control the template's flow and logic. They are enclosed in {% %}.
block
The block tag defines reusable template blocks.
Example:
{% block header %}
Introduction
{% endblock %}
To reuse a block, use the block function:
{{ block("header") }}
filter
The filter tag applies a filter to a block of content.
Example:
{% filter upper %}
hello
{% endfilter %}
Output:
HELLO
Filters can be chained:
{% filter upper | title %}
hello
{% endfilter %}
Output:
Hello
for
The for tag iterates over arrays, maps, or any java.lang.Iterable.
Example:
{% for user in users %}
{{ user.name }} lives in {{ user.city }}.
{% endfor %}
Special variables available within a loop:
loop.index: zero-based indexloop.length: total size of the iterableloop.first: true if it's the first iterationloop.last: true if it's the last iterationloop.revindex: iterations remaining until the end
{% for user in users %}
{{ loop.index }}: {{ user.id }}
{% endfor %}
To handle empty collections, use the else tag:
{% for user in users %}
{{ user.name }}
{% else %}
No users found.
{% endfor %}
For maps:
{% for entry in map %}
{{ entry.key }}: {{ entry.value }}
{% endfor %}
if
The if tag evaluates conditional logic.
Example:
{% if users is empty %}
No users available.
{% elseif users.length == 1 %}
One user found.
{% else %}
Multiple users found.
{% endif %}
if expressions can include:
booleanvaluesisoperator (e.g.,is empty,is not empty)
macro
The macro tag defines reusable blocks of content.
Example:
{% macro input(type="text", name, value) %}
<input type="{{ type }}" name="{{ name }}" value="{{ value }}">
{% endmacro %}
{{ input(name="username") }}
Output:
<input type="text" name="username" value="">
Passing global context:
{% set foo = 'bar' %}
{{ test(_context) }}
{% macro test(_context) %}
{{ _context.foo }}
{% endmacro %}
Output:
bar
raw
The raw tag prevents Pebble from parsing its content.
Example:
{% raw %}
{{ user.name }}
{% endraw %}
Output:
{{ user.name }}
set
The set tag defines a variable in the template context.
Example:
{% set header = "Welcome Page" %}
{{ header }}
Output:
Welcome Page
Test
Tests in Pebble are used to perform logical checks, such as determining if a variable is defined, empty, or of a specific type.
defined
Checks if a variable is defined.
{% if missing is not defined %}
...
{% endif %}
empty
Checks if a variable is empty. A variable is considered empty if it is:
- null
- an empty string
- an empty collection
- an empty map
{% if user.email is empty %}
...
{% endif %}
even
Checks if an integer is even.
{% if 2 is even %}
...
{% endif %}
iterable
Checks if a variable implements java.lang.Iterable.
{% if users is iterable %}
{% for user in users %}
...
{% endfor %}
{% endif %}
json
Checks if a variable is a valid JSON string.
{% if '{"test": 1}' is json %}
...
{% endif %}
map
Checks if a variable is an instance of a map.
{% if {"apple":"red", "banana":"yellow"} is map %}
...
{% endif %}
null
Checks if a variable is null.
{% if user.email is null %}
...
{% endif %}
odd
Checks if an integer is odd.
{% if 3 is odd %}
...
{% endif %}
Expressions FAQ
Was this page helpful?