Make Flows Modular and Reusable with Terraform Templates
For the complete documentation index, see llms.txt. For a full content snapshot, see llms-full.txt. Append.mdto anykestra.io/docs/*URL for plain Markdown.
Scale your codebase using Terraform to template and define flows
This guide shows how to use Terraform’s HCL (Hashicorp Configuration Language) templating features in a Kestra codebase.
To make your codebase accessible to users unfamiliar with Kestra syntax, encapsulate most of the logic and DSL (Domain-specific programming language) into Terraform modules.
This quick tutorial, will show you how templating capabilities brought by Terraform can help you :
- DRY (Do Not Repeat Yourself) your codebase
- Facilitate onboarding on Kestra
- Incorporate extra modularity
- Implement complex pipelines while keeping syntax clear
You can check the kestra-flows-template repo which contains a set of modules and subflows to help you get started with Terraform.
This guide covers creating a Terraform module and a subflow, and how to use them in your codebase.
Code structure
.└── environment/ ├── development ├── production/ # Contains subfolders defining Kestra flows resources │ ├── airbyte/ │ ├── dbt/ │ ├── triggers/ │ ├── main.tf # Instantiate each folder (airbyte, dbt ...) │ └── ... ├── modules/ # Terraform modules to be used in environments │ ├── airbyte_sync/ │ ├── trigger_cron/ │ └── ... └── subflows/ # Kestra subflows ├── main.tf ├── sub_cloud_sql_airbyte_query.yml └── ...Modules are folders under modules folder and can be instantiated either in development or production environments.
They only expose variables that are meant to be changed for usage purpose.
Inside a module, you can define a main.tf file that will define the resources to be created.
Creating a module, example with Airbyte
Create a module that defines a Kestra flow to sync data from Airbyte.
Tree structure of a Terraform module
.└── airbyte_sync/ ├── main.tf ├── tasks.yml └── variables.tfmain.tf contains the kestra_flow terraform resource, which will define the flow using a templated YAML file
resource "kestra_flow" "airbyte_sync" { keep_original_source = true flow_id = var.flow_id namespace = var.namespace content = join("", [ yamlencode({ id = var.flow_id namespace = var.namespace labels = var.priority != null ? merge(var.labels, { priority = var.priority }) : var.labels description = var.description }), templatefile("${path.module}/tasks.yml", { description = var.description airbyte-url = var.airbyte_url airbyte-connections = var.airbyte_connections max-duration = var.max_sync_duration late-maximum-delay = var.late_maximum_delay cron-expression = var.cron_expression }), var.trigger, ])}variables.tf will contain all the variables that can be passed to the module with appropriate validation and description
variable "airbyte_connections" { description = "List of Airbyte connections to trigger : id (can be found in URL), name is whatever makes sense" type = list(object({ name = string id = string }))
validation { condition = length(var.airbyte_connections) > 0 && length([ for o in var.airbyte_connections : true if length(regexall("^[A-Za-z_]+$", o.name)) > 0 ]) == length(var.airbyte_connections) error_message = "At least one connection should be provided, and connection names should not contain hyphens." }}
variable "flow_id" { type = string}
variable "description" { type = string}
variable "namespace" { type = string default = "blueprint"}
variable "airbyte_url" { type = string}
variable "trigger" { type = string description = "String containing triggers sections of the flow" default = ""}
variable "max_sync_duration" { type = string description = "Tell Kestra to wait logs for this max duration" default = ""}
variable "labels" { type = map(string) default = null description = "Labels to apply to the flow"}
variable "priority" { type = string default = null description = "Priority tag to apply to the flow"}
variable "cron_expression" { type = string description = "Cron expression or supported expression like : @hourly" default = null}
variable "late_maximum_delay" { type = string description = "Allow to disable auto-backfill : if the schedule didn't start after this delay, the execution will be skip."}tasks.yml: flow definition with Terraform templatefile jinja syntax
tasks:## Here we leverage the Terraform templating capabilities to generate the tasks## Using jinja-like syntax, we can loop over the list of connections and generate tasks for each of them%{ for connection in airbyte-connections ~}
- id: "trigger_${connection.name}" type: io.kestra.plugin.airbyte.connections.Sync connectionId: ${connection.id} url: "${airbyte-url}" httpTimeout: "PT1M" wait: false
- id: "check_${connection.name}" type: io.kestra.plugin.airbyte.connections.CheckStatus url: "${airbyte-url}" jobId: "{{ outputs.trigger_${connection.name}.jobId }}" pollFrequency: "PT1M" httpTimeout: "PT1M" retry: type: constant interval: PT1M maxAttempts: 5 %{ if length(max-duration) > 0} maxDuration: "${max-duration}" %{ endif }%{ endfor ~}
triggers: - id: cron_trigger type: io.kestra.plugin.core.trigger.Schedule cron: "${cron-expression}" lateMaximumDelay: "${late-maximum-delay}"Using the module in a Terraform environment
Using the module will look like this :
module "stripe_events_incremental" { source = "../../../modules/airbyte_sync" flow_id = "stripe_events" priority = "high" namespace = local.namespace description = "Stripe Events" airbyte_connections = [ { name = "stripe_events_incremental" id = module.airbyte_connection_stripe_offical.connection_id } ] max_sync_duration = "PT30M" airbyte_url = var.airbyte_url cron_expression = "@hourly" late_maximum_delay = "PT1H"}It is now easy to instantiate the module in your main.tf file, and to expose only the variables that are meant to be changed:
flow_id: the flow idnamespace: the namespace to save the flow indescription: the descriptionairbyte_connections: the list of Airbyte connections to trigger in a linear ordermax_sync_duration: the maximum duration to wait for logsairbyte_url: the Airbyte URL of the instancecron_expression: the cron expression to trigger the flowlate_maximum_delay: the maximum delay to wait for the flow to start, in case of missed schedules (backfill)
In case of changes in the way you want to implement the underlying tasks, you can modify the Terraform module without changing the interface (variables).
Subflow example: query and display results for a given Postgres database
Subflows are a way to encapsulate logic and make it reusable across your codebase.
Here is an example of a subflow that will query a Cloud SQL instance:
id: query_my_postgres_databasenamespace: company.teamdescription: "Query Postgres database and display results in logs"
inputs:- id: sqlQuery type: STRING defaults: "SELECT * FROM public.jobs ORDER BY created_at desc limit 1" # SQL query example
tasks:- id: query_data type: io.kestra.plugin.jdbc.postgresql.Query url: jdbc:postgresql://MY_HOST/MY_DATABASE username: MY_USER password: "{{ secrets.get('my-postgres-password') }}" sql: "{{ inputs.sqlQuery }}" fetchType: FETCH
- id: show_result type: io.kestra.plugin.core.log.Log message: | {% for row in outputs.query_data.rows %} {%- for key in row.keySet() -%} {{key}} : {{row.get(key)}} | {%- endfor -%} \n {% endfor %}"
## To make it easier to use the results in another flow## we expose the query result by using `outputs`outputs:- id: query_result value: "{{ outputs.query_data.rows }}" type: JSONYou can either execute this subflow as is, or use it in another flow to avoid repeating the same logic.
Executing the subflow will prompt you to enter the SQL query you want to execute :
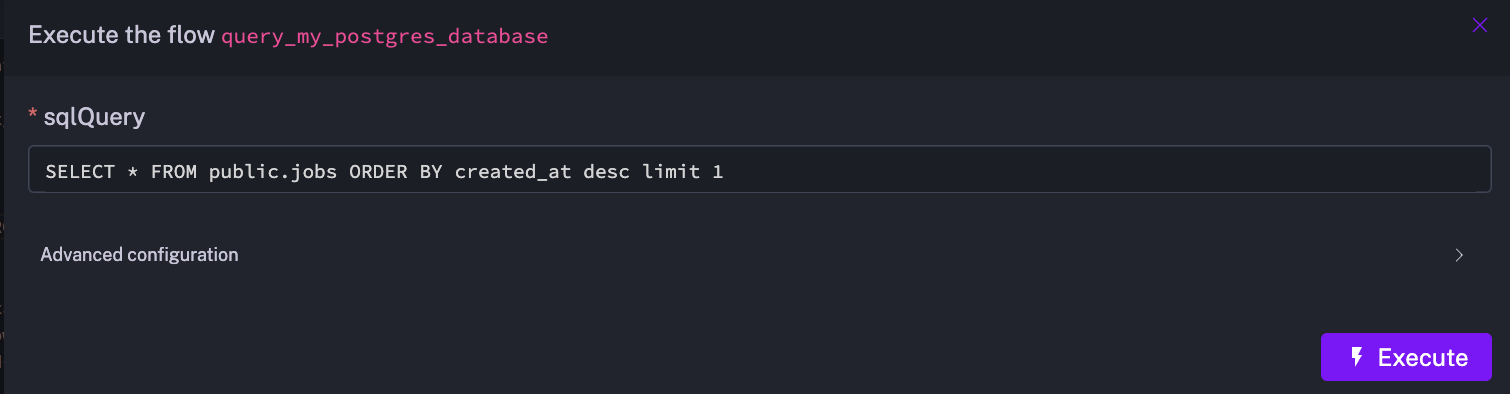
Using the subflow in a flow
- id: query_last_job type: io.kestra.core.tasks.flows.Subflow namespace: company.team flowId: query_my_postgres_database inputs: sqlQuery: "SELECT * FROM public.jobs ORDER BY created_at desc limit 1" wait: true transmitFailed: true
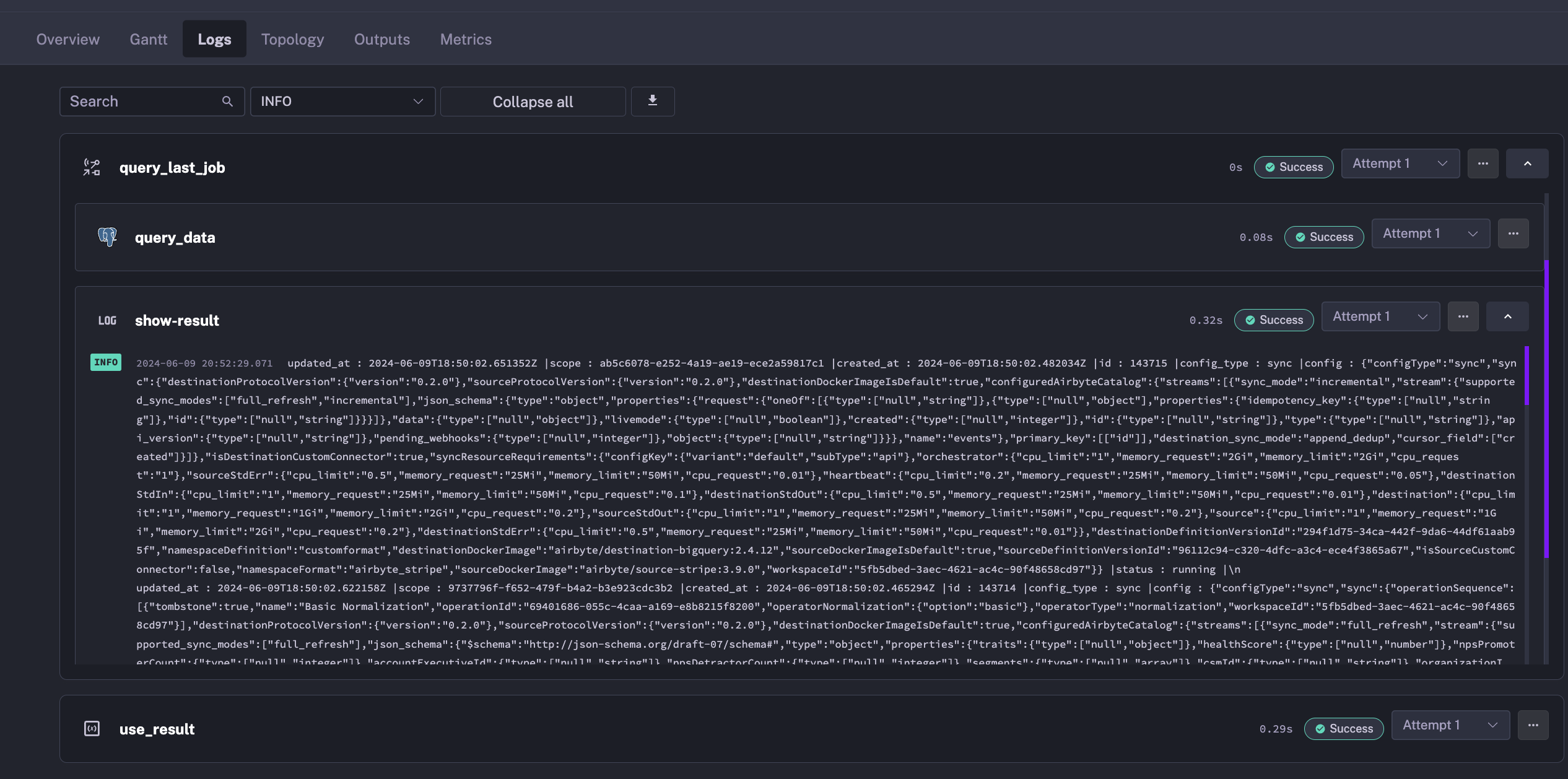
- id: use_result type: io.kestra.core.tasks.debugs.Return # Use the query result from the subflow format: "{{ outputs.query_last_job.outputs.query_result }}"- Connection details are stored in the subflow, and only the SQL query is exposed to the user.
- Subflow natively displays results in logs for easy debugging.
- Outputs of the subflow can be used in the parent flow by using
outputs.query_data.rowsin theshow_resulttask.
Note:
wait: truewill wait for the subflow to finish before continuing the flow execution.transmitFailed: truewill transmit the failed status of the subflow to the parent flow.
Parent flow logs will display tasks from subflow directly:
Subflows vs Terraform templating
Subflows hide unnecessary details to their users, abstracting connection details, logging and such for a given set of tasks.
Terraform modules allow you to define complex flows in a modular way. Also it supports passing outputs from one Terraform resource to another across systems (Airbyte terraform resource output to Kestra module input variable) and strongly validate inputs which is not possible with subflows.
Conclusion
Terraform templating is a powerful way to define flows in a modular way, and to expose only the variables that are meant to be changed.
It is a great way to make your codebase more maintainable and to facilitate onboarding for users unfamiliar with Kestra syntax.
Was this page helpful?