Run Resource-Intensive Processes on Kubernetes Pods
For the complete documentation index, see llms.txt. For a full content snapshot, see llms-full.txt. Append.mdto anykestra.io/docs/*URL for plain Markdown.
Schedule long running and intensive processes with Kestra on Kubernetes.
Long running tasks hold strong importance in the world of automation. They can range from data processing, machine learning, and data analytics to batch processing, ETL, and more.
While these tasks are essential for business operations, they can be resource-intensive and time-consuming while requiring specific hardware. To execute these tasks efficiently, you need a robust and scalable infrastructure that can handle the workload effectively.
Kestra offers various task execution solutions such as Docker, local processes, and Kubernetes. See Task Runners for more details.
This guide focuses on executing long-running tasks on Kubernetes using Kestra.
Kubernetes pods are a great fit due to the control and flexibility they provide. With Kubernetes, you can precisely define resource requirements, permissions, namespace, handle workload identity, and ensure proper networking for your tasks. Pods can also access other Kubernetes services hosted on the cluster such as databases, storage, and applications.
As an example, this guide uses a dbt job to demonstrate how Kestra executes complex tasks on Kubernetes with resource requirements.
Schedule task in a Kubernetes pod using podCreate
Kestra’s podCreate task allows you to launch a Kubernetes pod directly by providing the complete Kubernetes YAML configuration as an input. This gives you full control over the pod’s specifications, such as CPU, memory, image, or node selector.
Here is an example of a dbt job that runs on Kubernetes using Kestra:
id: my-dbt-jobnamespace: dev
tasks: - id: dbt-command type: io.kestra.plugin.kubernetes.PodCreate
# Retry the task if it fails retry: behavior: RETRY_FAILED_TASK maxAttempts: 2 type: constant interval: PT5M warningOnRetry: true namespace: kestra
# Define the commands to run inputFiles: dbt-commands.sh: | #!/bin/bash
# Exit on error set -eo pipefail
# Clone the dbt example repository git clone --depth 1 https://github.com/dbt-labs/jaffle_shop_duckdb.git --branch duckdb --single-branch
# Copy the dbt example repository to the working directory cp -a jaffle_shop_duckdb/. .
# dbt commands to run dbt deps dbt build
# Define the pod specification using the Kubernetes YAML syntax spec: restartPolicy: Never containers: - name: dbt-duckdb image: ghcr.io/kestra-io/dbt-duckdb:latest
# Specify resource requirements resources: request: cpu: "300m" memory: "500Mi"
# Run the script in the container command: - "/bin/bash" - "{{workingDir}}/dbt-commands.sh"
# Node selector to run the pod on a specific node nodeSelector: {}This flow will:
- create a Kubernetes pod in the
kestranamespace with the specified resource requirements: 300m CPU and 500Mi memory - clone the dbt example repository inside the pod
- run the dbt seed and build commands
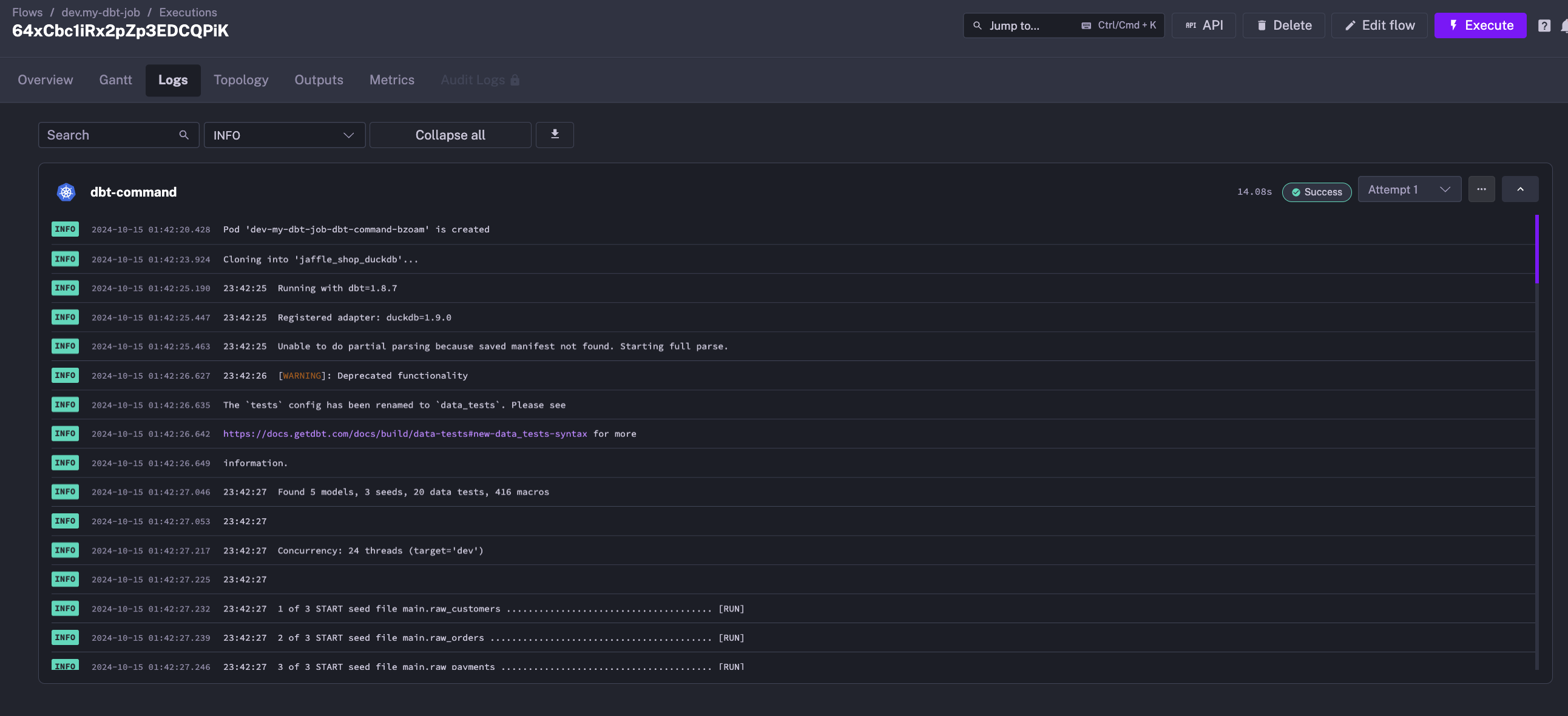
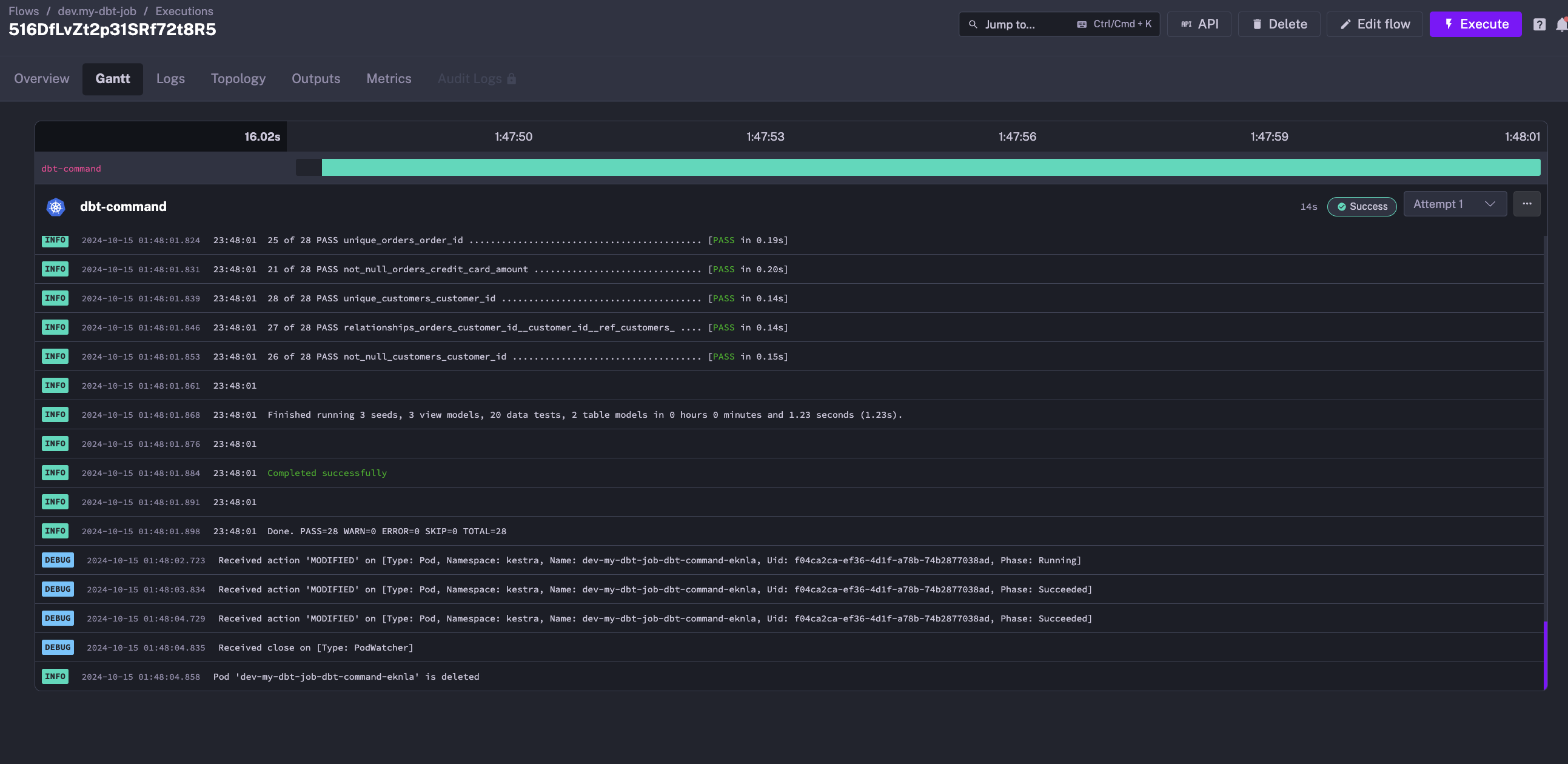
At the end of the execution, the pod is deleted, and the logs remain available in the Kestra UI.
Embrace Kestra versality with Kubernetes Task Runners
While podCreate provides deep control, it takes aways all the benefits of Kestra’s rich plugins ecosystem, dbt plugin in this case. Also it can be cumbersome to manage complex Kubernetes pod YAML specification for each task, especially when you have multiple commands to run.
Kestra’s Task Runners let you define workflows that benefit from the plugin system, using familiar plugins while still taking advantage of Kubernetes to secure and scale tasks effectively.
Task Runners also let you test a task locally using Docker or Process before deploying it on Kubernetes.
The same example would look like this using a Task Runner:
id: dbt-task-runnernamespace: dev
tasks: - id: dbt_build type: io.kestra.plugin.dbt.cli.DbtCLI taskRunner: type: io.kestra.plugin.ee.kubernetes.runner.Kubernetes namespace: kestra resources: request: cpu: "300m" memory: "500Mi" containerImage: ghcr.io/kestra-io/dbt-duckdb:latest commands: - git clone --depth 1 https://github.com/dbt-labs/jaffle_shop_duckdb.git --branch duckdb --single-branch - cp -a jaffle_shop_duckdb/. . - dbt deps - dbt build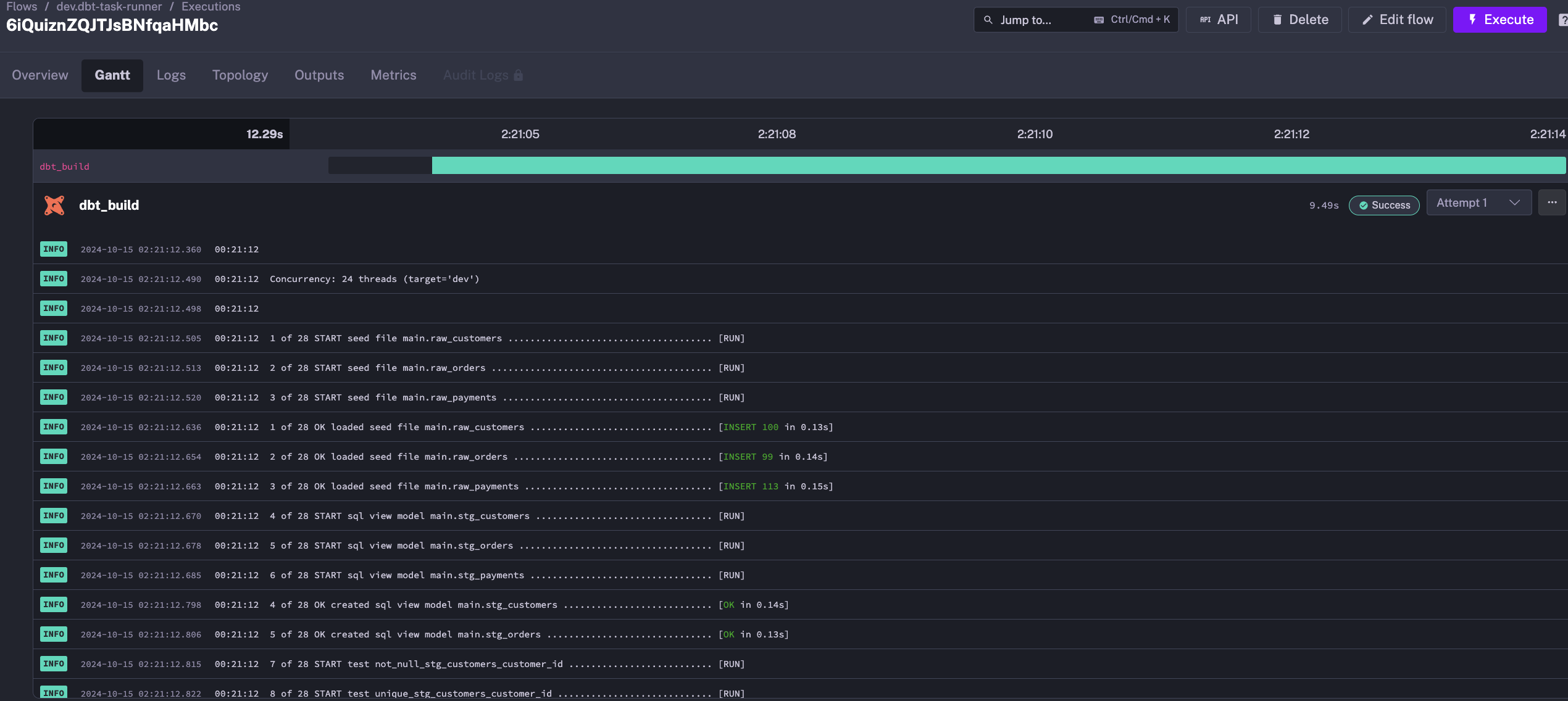
To test this flow on a local Kestra instance, change the taskRunner type to io.kestra.plugin.scripts.runner.docker.Docker:
id: dbt-task-runnernamespace: dev
tasks: - id: dbt_build type: io.kestra.plugin.dbt.cli.DbtCLI taskRunner: type: io.kestra.plugin.scripts.runner.docker.Docker containerImage: ghcr.io/kestra-io/dbt-duckdb:latest commands: - git clone --depth 1 https://github.com/dbt-labs/jaffle_shop_duckdb.git --branch duckdb --single-branch - cp -a jaffle_shop_duckdb/. . - dbt deps - dbt buildThis flexibility allows you to test your tasks locally before deploying them on Kubernetes.
Conclusion
Kestra provides a flexible way to execute long-running and intensive tasks on Kubernetes. With Kestra’s Task Runners, you can define workflows that use the plugin system while taking advantage of Kubernetes to secure and scale tasks effectively.
If needed, you can also use the podCreate task to launch a Kubernetes pod directly by providing the complete Kubernetes YAML configuration as input.
Was this page helpful?