 Azure Batch Task Runner
Azure Batch Task Runner
Available on: Enterprise Edition>= 0.18.0
Run tasks as containers on Azure Batch VMs.
How to use the Azure Batch task runner
This task runner will deploy a container for the task in a specified Azure Batch pool.
To launch the task on Azure Batch, there is only two main concepts you need to be aware of:
- Pool — mandatory, not created by the task. This is a pool composed of nodes where your task can run on.
- Job — created by the task runner; holds information about which image, commands, and resources to run on.
How does Azure Batch task runner work
In order to support inputFiles, namespaceFiles, and outputFiles, the Azure Batch task runner currently relies on resource files and output files which transit through Azure Blob Storage.
Since we don't know the working directory of the container in advance, we always need to explicitly define the working directory and output directory when using the Azure Batch runner, e.g. use cat {{ workingDir }}/myFile.txt rather than cat myFile.txt.
A full flow example
id: azure_batch_runner
namespace: company.team
variables:
poolId: "poolId"
containerName: "containerName"
tasks:
- id: scrape_environment_info
type: io.kestra.plugin.scripts.python.Commands
containerImage: ghcr.io/kestra-io/pydata:latest
taskRunner:
type: io.kestra.plugin.ee.azure.runner.Batch
account: "{{ secret('AZURE_ACCOUNT') }}"
accessKey: "{{ secret('AZURE_ACCESS_KEY') }}"
endpoint: "{{ secret('AZURE_ENDPOINT') }}"
poolId: "{{ vars.poolId }}"
blobStorage:
containerName: "{{ vars.containerName }}"
connectionString: "{{ secret('AZURE_CONNECTION_STRING') }}"
commands:
- python {{ workingDir }}/main.py
namespaceFiles:
enabled: true
outputFiles:
- "environment_info.json"
inputFiles:
main.py: |
import platform
import socket
import sys
import json
from kestra import Kestra
print("Hello from Azure Batch and kestra!")
def print_environment_info():
print(f"Host's network name: {platform.node()}")
print(f"Python version: {platform.python_version()}")
print(f"Platform information (instance type): {platform.platform()}")
print(f"OS/Arch: {sys.platform}/{platform.machine()}")
env_info = {
"host": platform.node(),
"platform": platform.platform(),
"OS": sys.platform,
"python_version": platform.python_version(),
}
Kestra.outputs(env_info)
filename = 'environment_info.json'
with open(filename, 'w') as json_file:
json.dump(env_info, json_file, indent=4)
if __name__ == '__main__':
print_environment_info()
For a full list of properties available in the Azure Batch task runner, check the Azure plugin documentation or explore the same in the built-in Code Editor in the Kestra UI.
Full step-by-step guide: setting up Azure Batch from scratch
Before you begin
Before you start, you need to have the following:
- An Microsoft Azure account.
- A Kestra instance in a version 0.16.0 or later with Azure credentials stored as secrets or environment variables within the Kestra instance.
Azure Portal Setup
Create a Batch account and Azure Storage account
Once you're logged into your Azure account, search for "Batch accounts" and select the first option under Services.
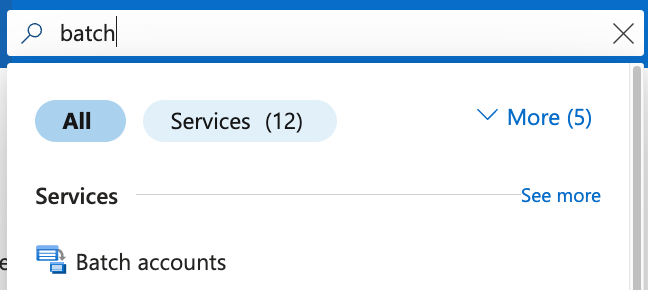
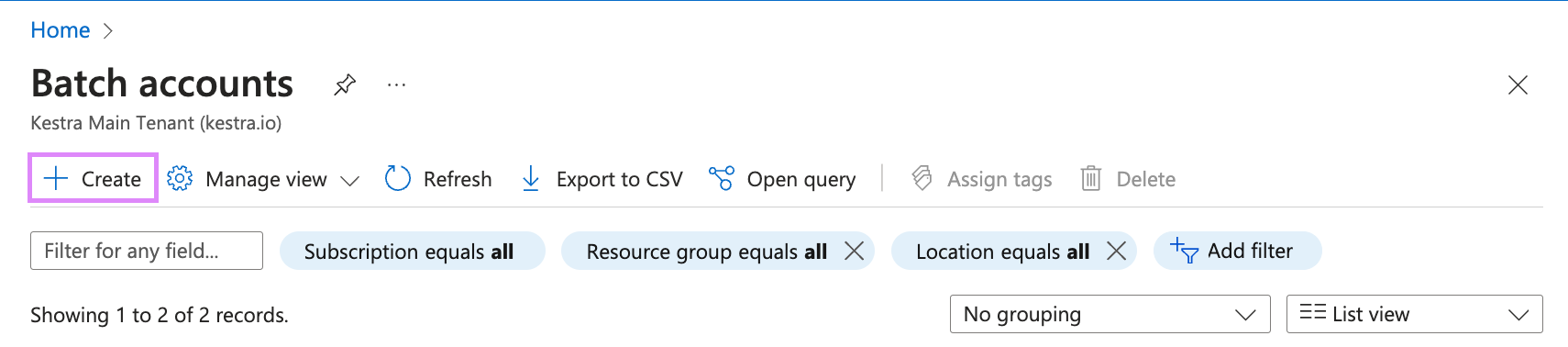
Now on that page, select Create to make a new account.
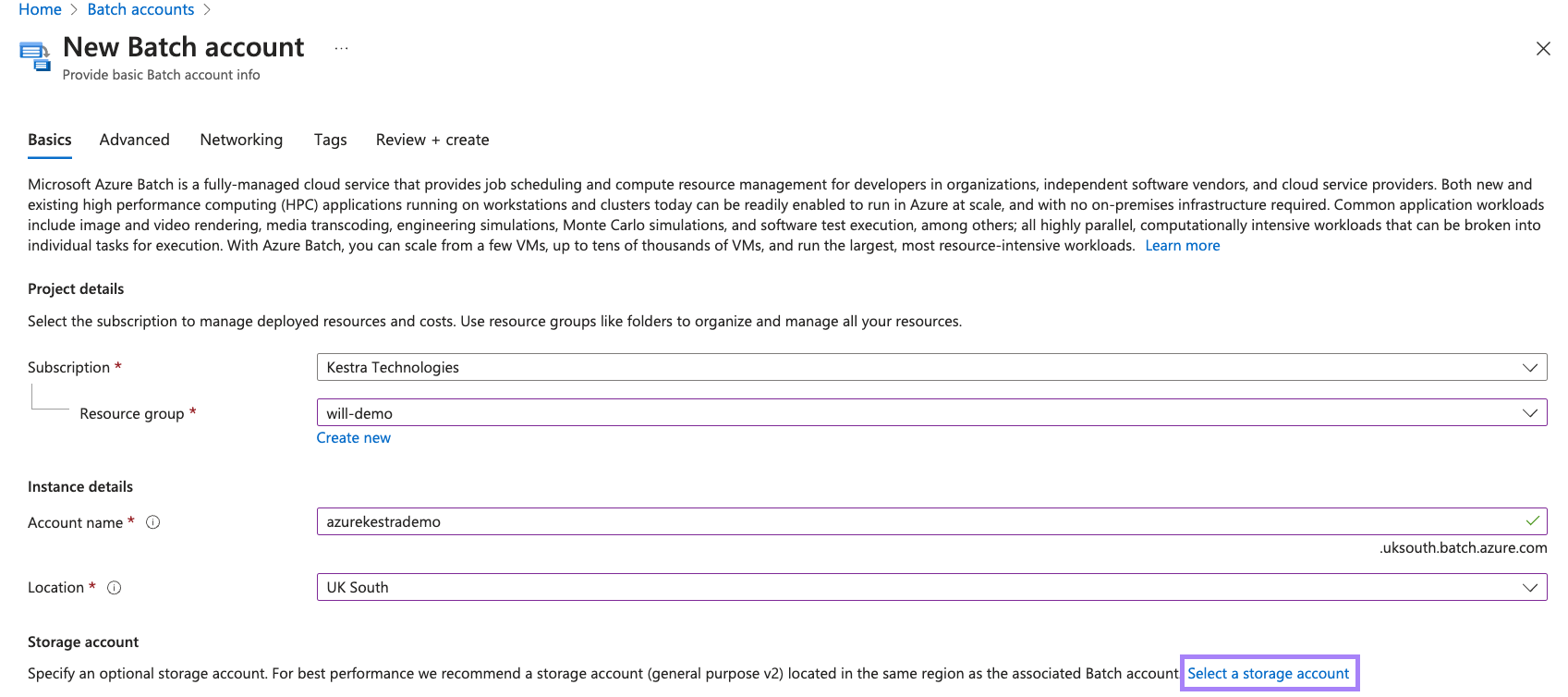
Select the appropriate resource group as well as fill in the Account name and Location fields. Afterwards, click on Select a storage account.
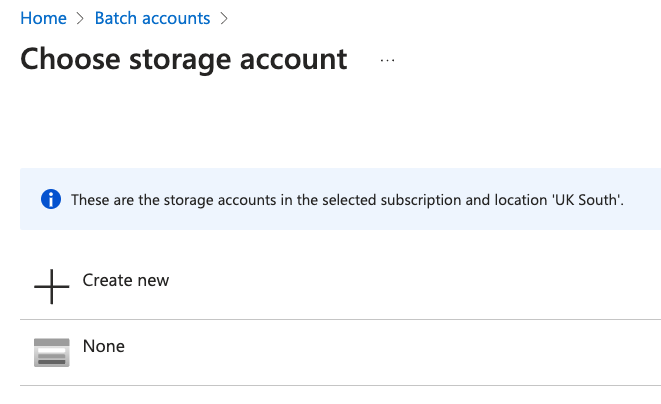
If you do not have an existing storage account, press Create new and type a name in, e.g. "mybatchstorage". Leave the other settings as the default options and select OK.
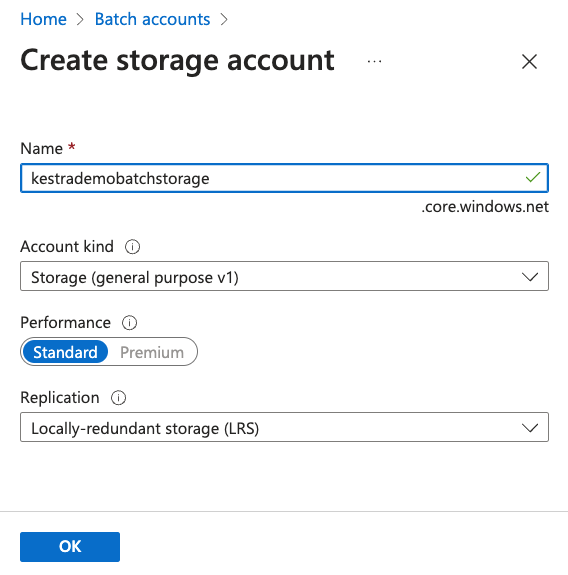
Now we have all the correct details filled, we can now press Review + create and then Create on the next page to create our new Batch account.
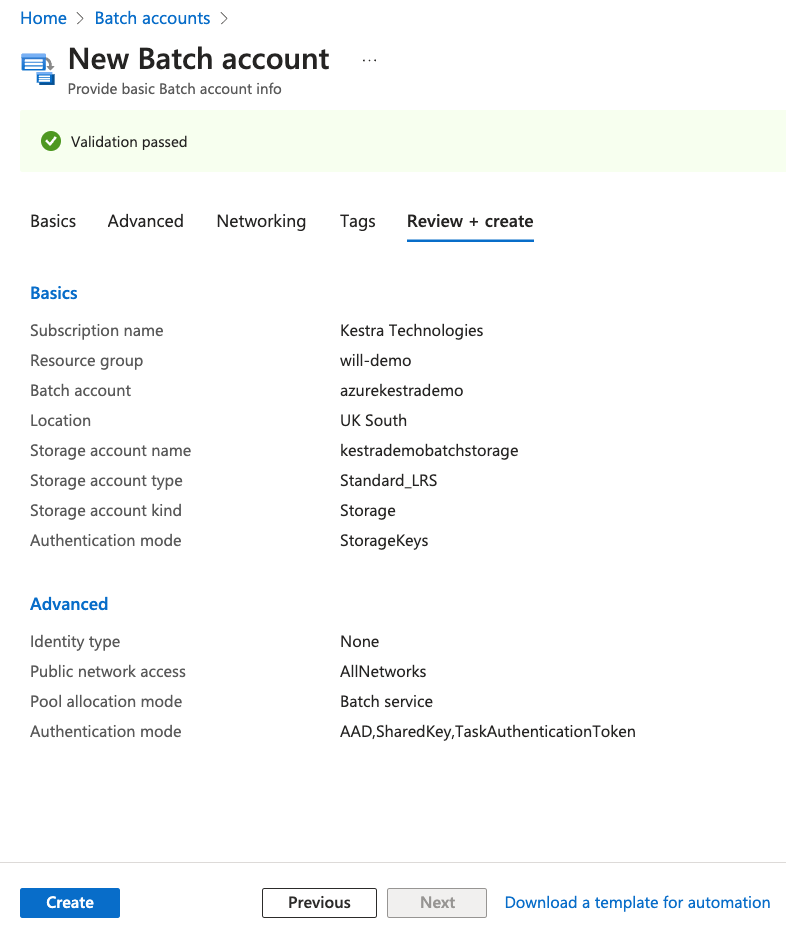
Once the account has been created, you'll receive a Deployment succeeded message appear. Select **Go to resource to go to the account.
Create a pool
Now we have a Batch account, we can create a pool of compute notes in our Batch account that Kestra will use.
On the Batch account page, select Pools in the left navigation menu, then select Add at the top of the Pools page.
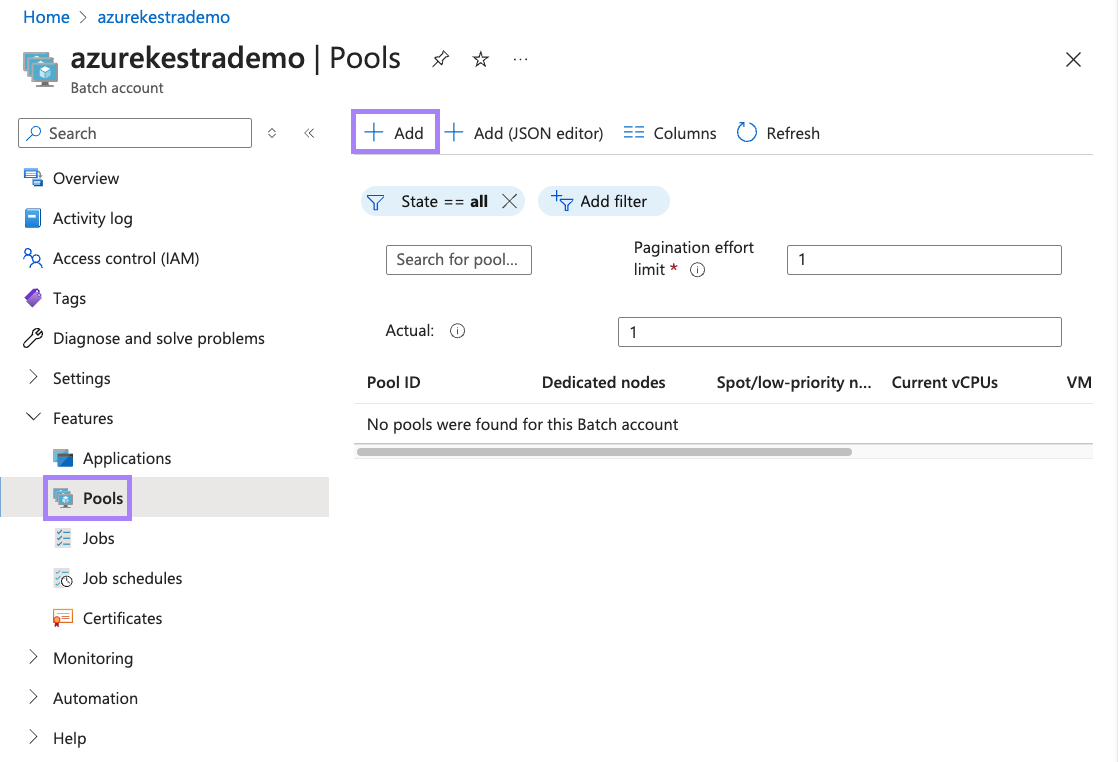
On the Add pool page, enter a Pool ID.
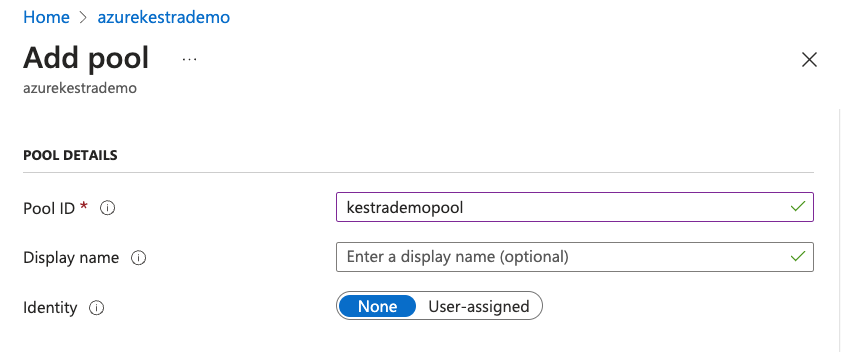
Under Operating System:
- Select the Publisher as
microsoft-azure-batch - Select the Offer as
ubuntu-server-container - Select the Sku as
20-04-lts
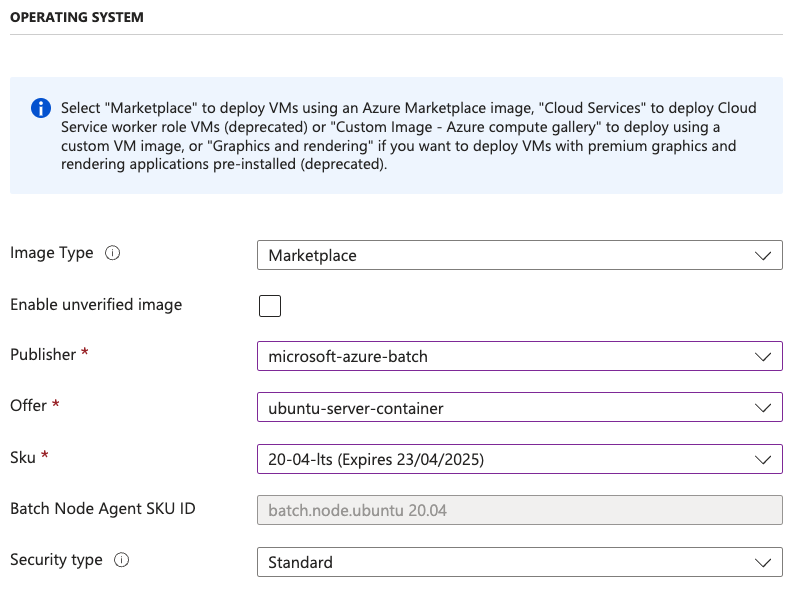
Scroll down to Node size and select Standard_A1_v2 which is 1 vCPUs and 2 GB Memory. Also enter 2 for Target dedicated nodes.
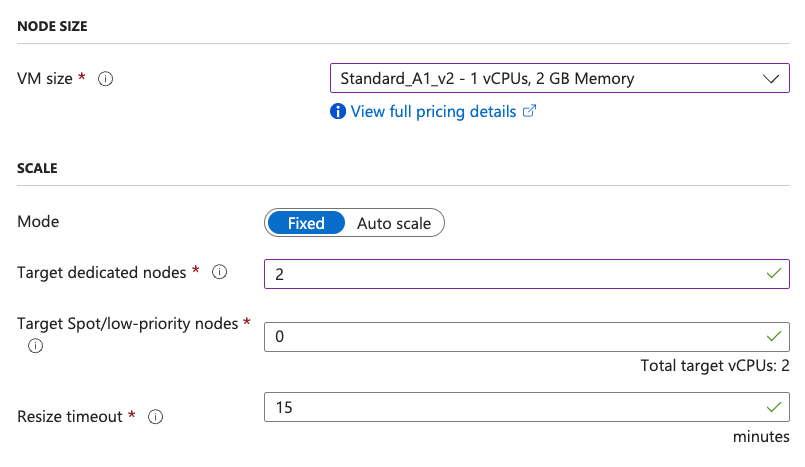
Once you've done that, you can now select OK at the bottom to create the pool.
Create Access Key
Inside of our Batch account, go to Settings and then Keys. Generate a new set of keys. We'll need:
Batch accountforaccountAccount endpointforendpointPrimary access keyforaccessKey
Blob storage
Search for Storage account and select our recently made account. Inside of here, go to the Data storage menu and select Containers. Now select + Container to make a new container.
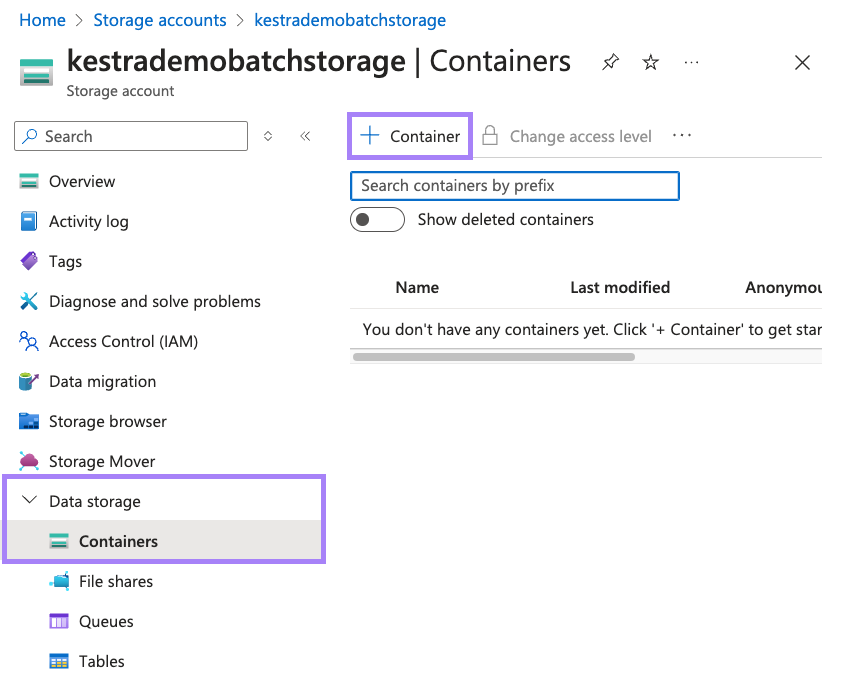
Type in a name for the container and select Create.
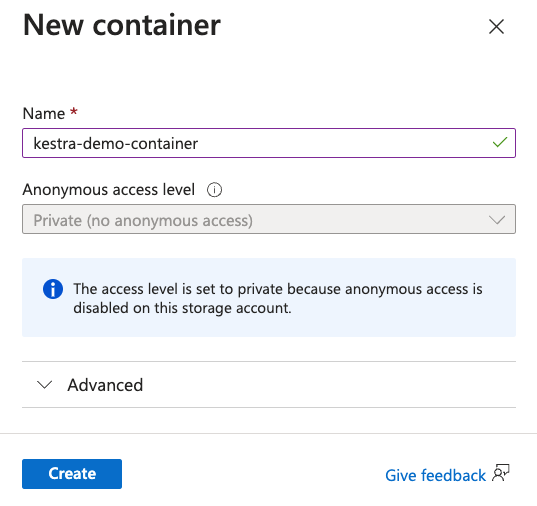
Now that we've created our batch account, storage account, pool and container, we can now create our flow inside of Kestra.
Creating our Flow
Below is an example flow that will run a Python file called main.py on a Azure Batch Task Runner. At the top of the io.kestra.plugin.scripts.python.Commands task, there are the properties for defining our Task Runner:
containerImage: ghcr.io/kestra-io/pydata:latest
taskRunner:
type: io.kestra.plugin.ee.azure.runner.Batch
account: "{{ secret('AZURE_ACCOUNT') }}"
accessKey: "{{ secret('AZURE_ACCESS_KEY') }}"
endpoint: "{{ secret('AZURE_ENDPOINT') }}"
poolId: "{{ vars.poolId }}"
blobStorage:
containerName: "{{ vars.containerName }}"
connectionString: "{{ secret('AZURE_CONNECTION_STRING') }}"
This is where we can enter the details for Azure such as account, accessKey, endpoint, poolId, and blobStorage. We can add these as secrets and variables.
id: azure_batch_runner
namespace: company.team
variables:
poolId: "poolId"
containerName: "containerName"
tasks:
- id: get_env_info
type: io.kestra.plugin.scripts.python.Commands
containerImage: ghcr.io/kestra-io/pydata:latest
taskRunner:
type: io.kestra.plugin.ee.azure.runner.Batch
account: "{{ secret('AZURE_ACCOUNT') }}"
accessKey: "{{ secret('AZURE_ACCESS_KEY') }}"
endpoint: "{{ secret('AZURE_ENDPOINT') }}"
poolId: "{{ vars.poolId }}"
blobStorage:
containerName: "{{ vars.containerName }}"
connectionString: "{{ secret('AZURE_CONNECTION_STRING') }}"
commands:
- python {{ workingDir }}/main.py
namespaceFiles:
enabled: true
outputFiles:
- "environment_info.json"
inputFiles:
main.py: |
import platform
import socket
import sys
import json
from kestra import Kestra
print("Hello from Azure Batch and kestra!")
def print_environment_info():
print(f"Host's network name: {platform.node()}")
print(f"Python version: {platform.python_version()}")
print(f"Platform information (instance type): {platform.platform()}")
print(f"OS/Arch: {sys.platform}/{platform.machine()}")
env_info = {
"host": platform.node(),
"platform": platform.platform(),
"OS": sys.platform,
"python_version": platform.python_version(),
}
Kestra.outputs(env_info)
filename = 'environment_info.json'
with open(filename, 'w') as json_file:
json.dump(env_info, json_file, indent=4)
if __name__ == '__main__':
print_environment_info()
When we press execute, we can see that our task runner is created in the Logs.
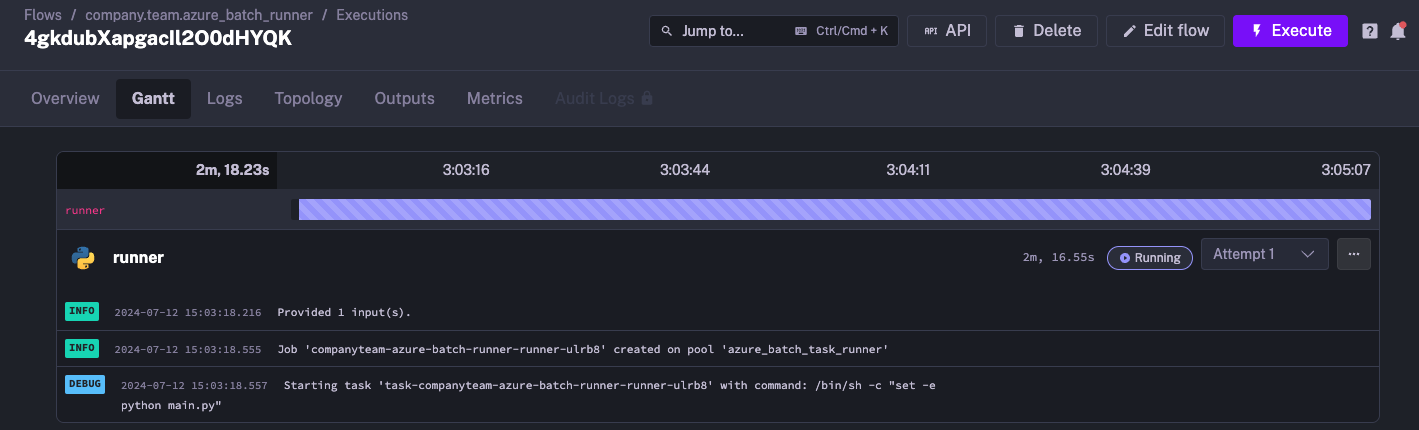
We can also go to the Azure Portal to see our task runner has been created:
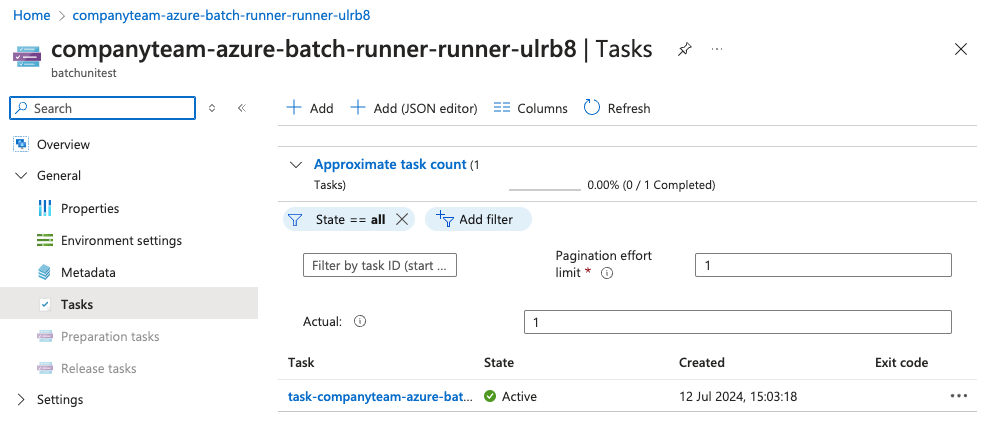
Once the task has completed, it will automatically close down the runner on Azure.
We can also view the outputs generated in the Outputs tab in Kestra, which contains information about the Azure Batch task runner generated from our Python script:
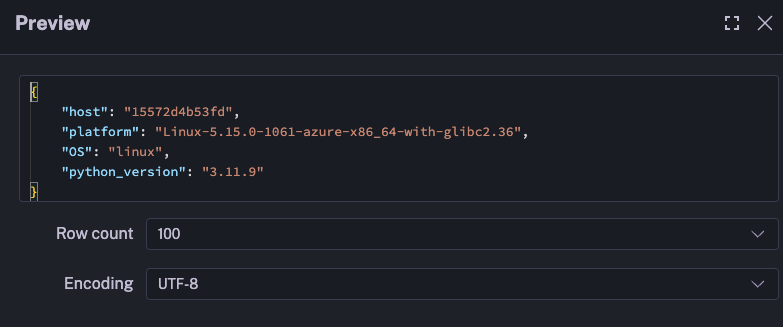
Was this page helpful?